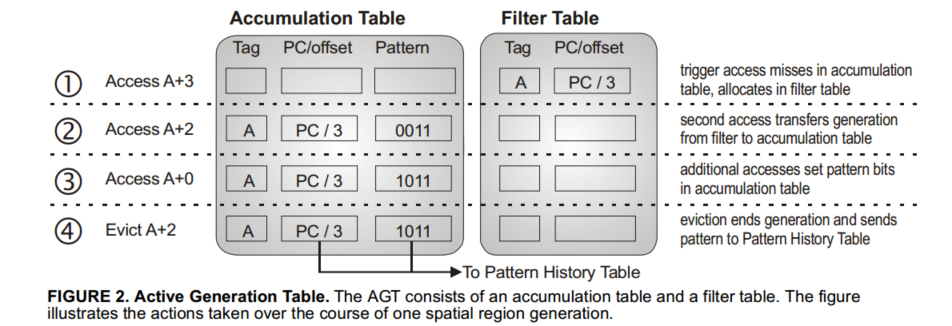
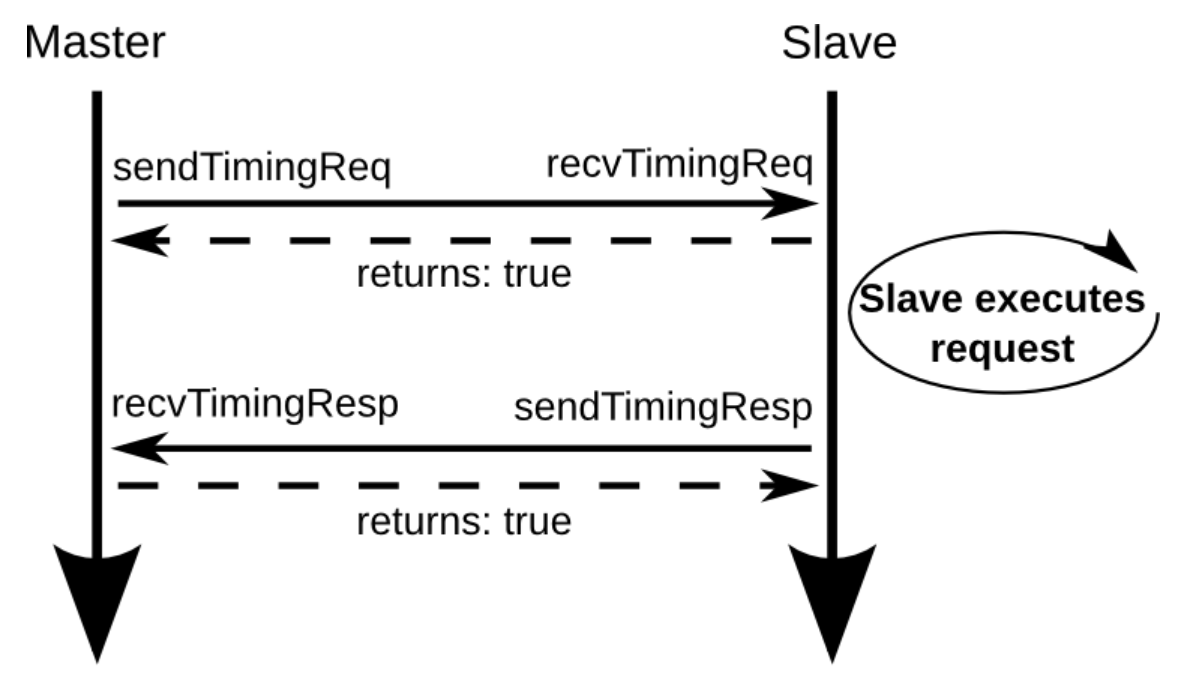
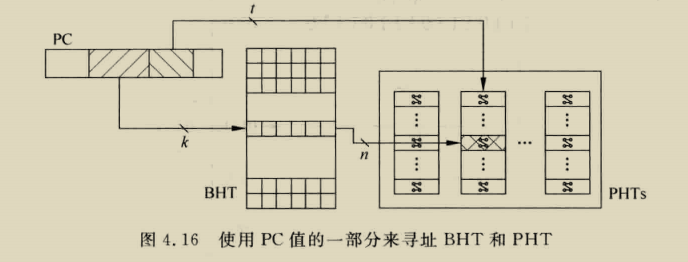
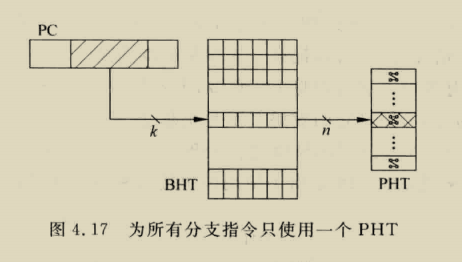
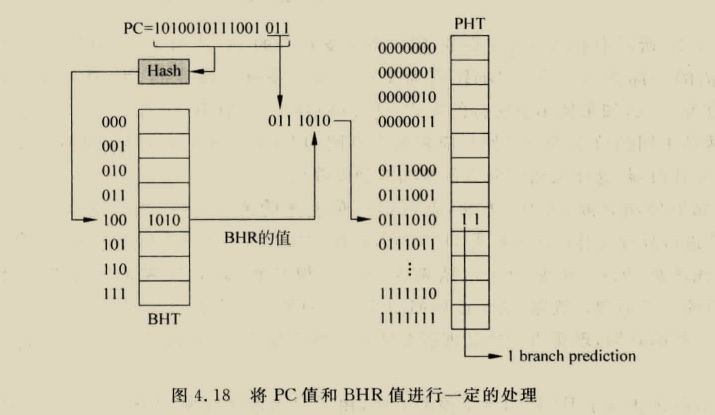
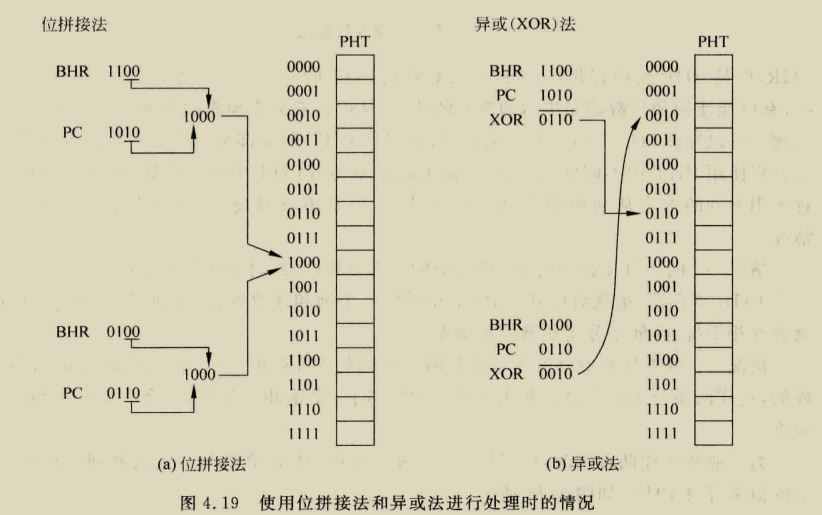
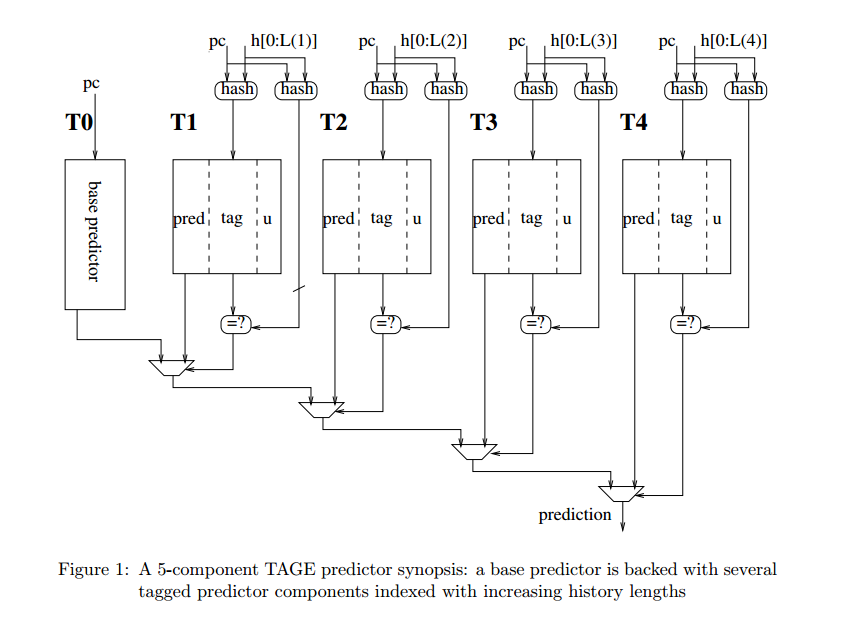
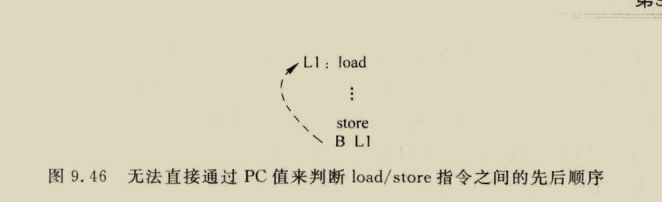
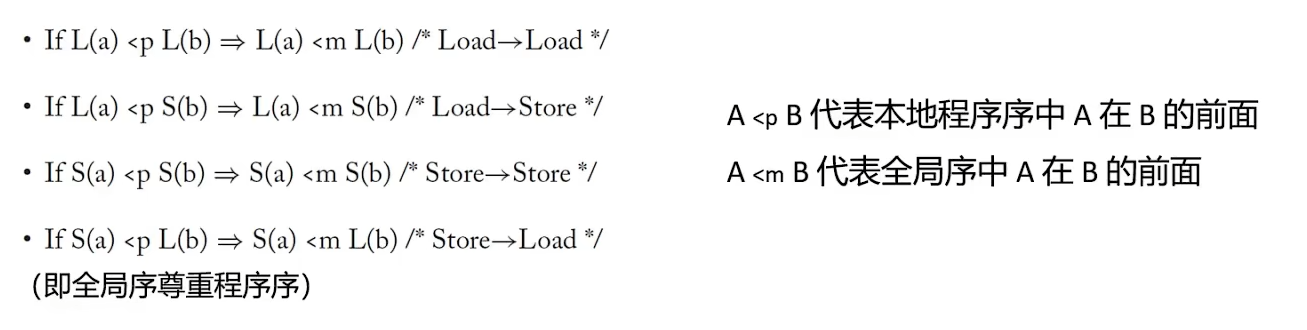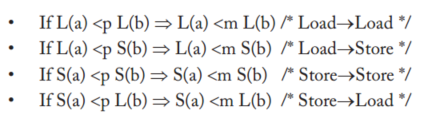我们形式化了空间相关性的概念,类似于先前的空间足迹研究[4,17]。我们将空间区域定义为系统地址空间中固定大小的部分,由多个连续的缓存块组成。A spatial region generation is the time interval over which SMS records accesses within a spatial region,我们把第一次访问这个空间区域称为触发访问,空间模式是表示在a spatial region generation期间访问区域的blocks集合的位向量???
定义a spatial region generation精确间隔会显著影响空间格局的精度和覆盖范围,a spatial region generation必须定义以确保,当SMS流在未来触发访问时进入缓存,没有预测的块在使用前被驱除或无效,
对于SPEC CPU 2000程序,PC+addr可以通过pc+a spatial region offset实现,这个偏移是cache block中与空间区域起始位置的相对地址,也就是相当于这个区域的哪个block,这个偏移允许预测器区分由相同代码片段生成的重复模式,这些重复模式不同支出就是他们相对空间区域边界对其,大大减少预测表存储需求,applications have far fewer distinct miss PCs than miss addresses.
我们观察到这种索引,除了节省内存,还可以消除cold misses,当代码序列在大型数据集重复相同的访问模式,访问序列刚开始时学习的PC相关空间模式为以前从未访问的数据提供准确预测。Database scan and join operations, which dominate the execution of decision support queries 包含着只访问数据以此的唱重复访问模式,这些应用适合这种index方式
设计
(终于到自己的SMS设计了)
我们的设计目标是多处理器环境下的高性能商业服务器应用程序,区别:之前的设计针对decoupled sectored [22] or sub-blocked caches.
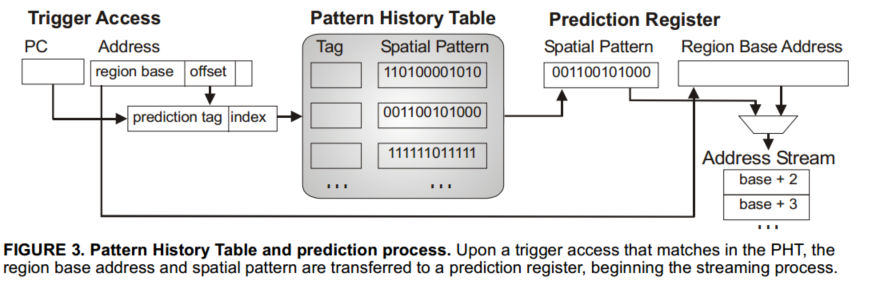
The pattern history table stores previously-observed spatial patterns, and is accessed at the start of each spatial region generation to predict the pattern of future accesses.
Observing Spatial Patterns
SMS通过记录在AGT空间区域生成过程中访问的块来学习空间模式,当空间区域生成开始时,SMS在AGT分配一个条目,当cache block被访问,更新AGT记录的模式,当eviction/invalidation of any block accessed during the generation),AGT将空间模式转移到PHT,然后释放条目
我们形式化了空间相关性的概念,类似于先前的空间足迹研究[4,17]。我们将空间区域定义为系统地址空间中固定大小的部分,由多个连续的缓存块组成。A spatial region generation is the time interval over which SMS records accesses within a spatial region,我们把第一次访问这个空间区域称为触发访问,空间模式是表示在a spatial region generation期间访问区域的blocks集合的位向量???
定义a spatial region generation精确间隔会显著影响空间格局的精度和覆盖范围,a spatial region generation必须定义以确保,当SMS流在未来触发访问时进入缓存,没有预测的块在使用前被驱除或无效,
对于SPEC CPU 2000程序,PC+addr可以通过pc+a spatial region offset实现,这个偏移是cache block中与空间区域起始位置的相对地址,也就是相当于这个区域的哪个block,这个偏移允许预测器区分由相同代码片段生成的重复模式,这些重复模式不同支出就是他们相对空间区域边界对其,大大减少预测表存储需求,applications have far fewer distinct miss PCs than miss addresses.
我们观察到这种索引,除了节省内存,还可以消除cold misses,当代码序列在大型数据集重复相同的访问模式,访问序列刚开始时学习的PC相关空间模式为以前从未访问的数据提供准确预测。Database scan and join operations, which dominate the execution of decision support queries 包含着只访问数据以此的唱重复访问模式,这些应用适合这种index方式
设计
(终于到自己的SMS设计了)
我们的设计目标是多处理器环境下的高性能商业服务器应用程序,区别:之前的设计针对decoupled sectored [22] or sub-blocked caches.
The pattern history table stores previously-observed spatial patterns, and is accessed at the start of each spatial region generation to predict the pattern of future accesses.
Observing Spatial Patterns
SMS通过记录在AGT空间区域生成过程中访问的块来学习空间模式,当空间区域生成开始时,SMS在AGT分配一个条目,当cache block被访问,更新AGT记录的模式,当eviction/invalidation of any block accessed during the generation),AGT将空间模式转移到PHT,然后释放条目
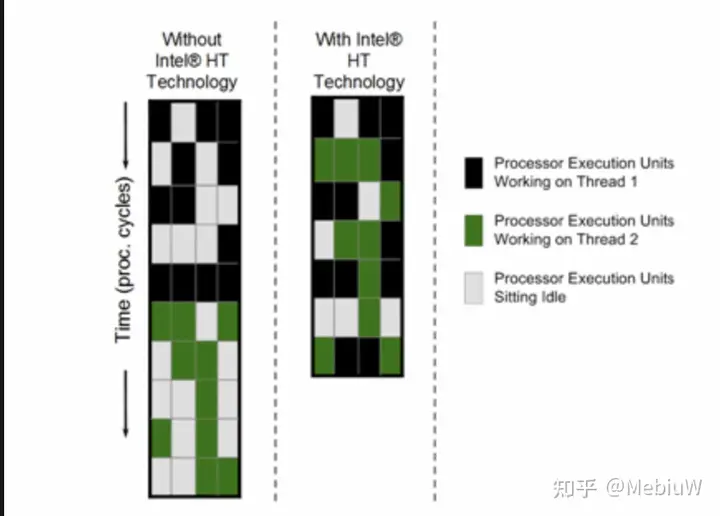
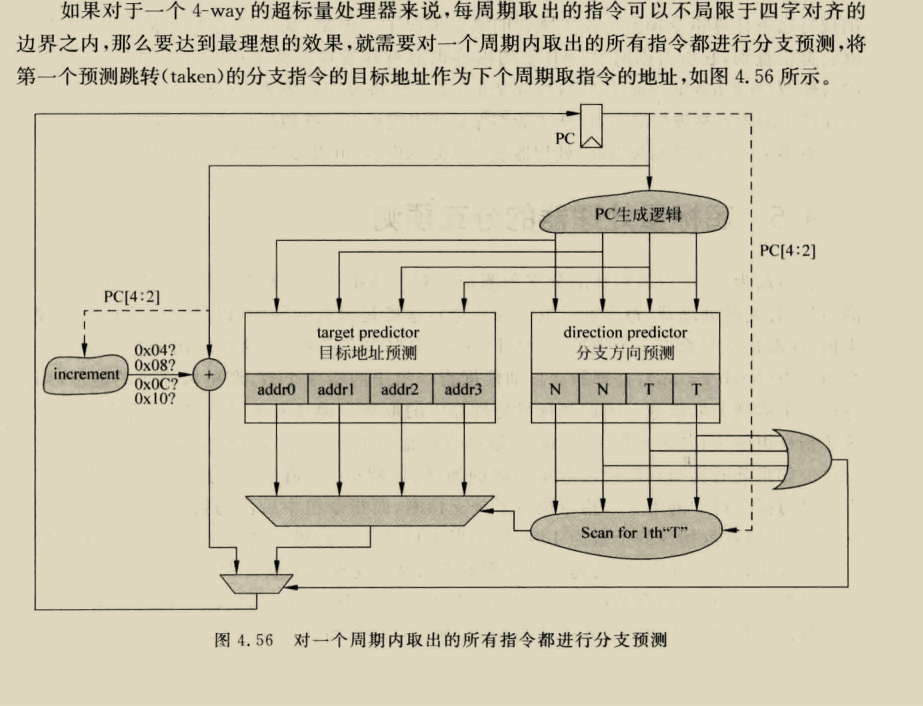
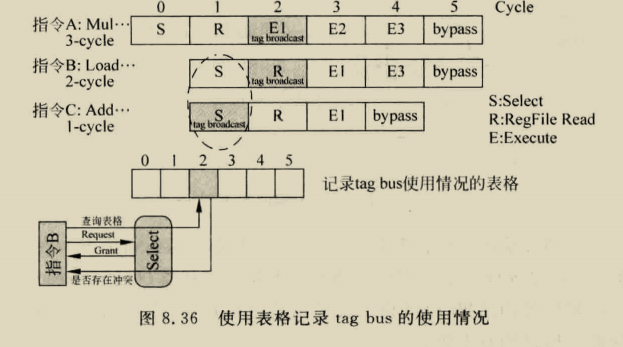
除了频率以外,要提升CPU的单核性能,第一个常见手段就是尽可能的缩短每个指令执行的周期,不过在我们假设的这个场景中和SMT关系不大,这里就不说了。第二个常见手段就是指令级并行(ILP)。虽然说这个任务1理论上是得一个指令接着一个指令的执行,但实际上这些指令并一定只能这么顺序执行,只要两个指令之间没有相互依赖和冲突,那么就可以并发执行(一起执行),从而缩短总的执行时间。 例如在上面这个例子中,我将指令分组成A B C D四组,组内必须顺序执行,组间的指令完全没有依赖(彼此不依赖对方执行后的数据)和冲突(不共享资源,不是一类操作),那么我们就可以并发执行这些指令。
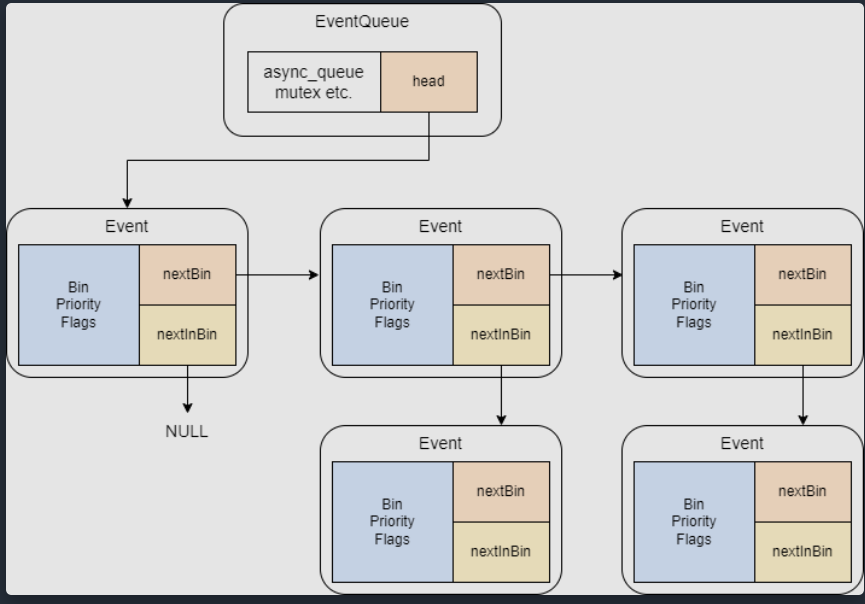
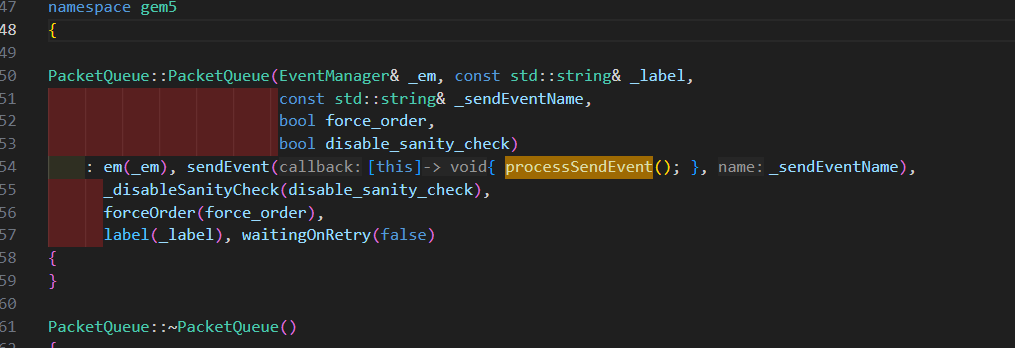
class Event : public EventBase, public Serializable { Event *nextBin; // Bin defined as when+priority Event *nextInBin; Tick _when; // timestamp when event should be processed Priority _priority; //!< event priority Flags flags; Counter instance; // event unique ID EventQueue *queue;
virtual void process() = 0; bool scheduled() const { return flags.isSet(Scheduled); } // Managed event scheduled and being held in the event queue. void acquire() { if (flags.isSet(Event::Managed)) acquireImpl(); }
// Managed event removed from the event queue. void release() { if (flags.isSet(Event::Managed)) releaseImpl(); } void setWhen(Tick when, EventQueue *q) }
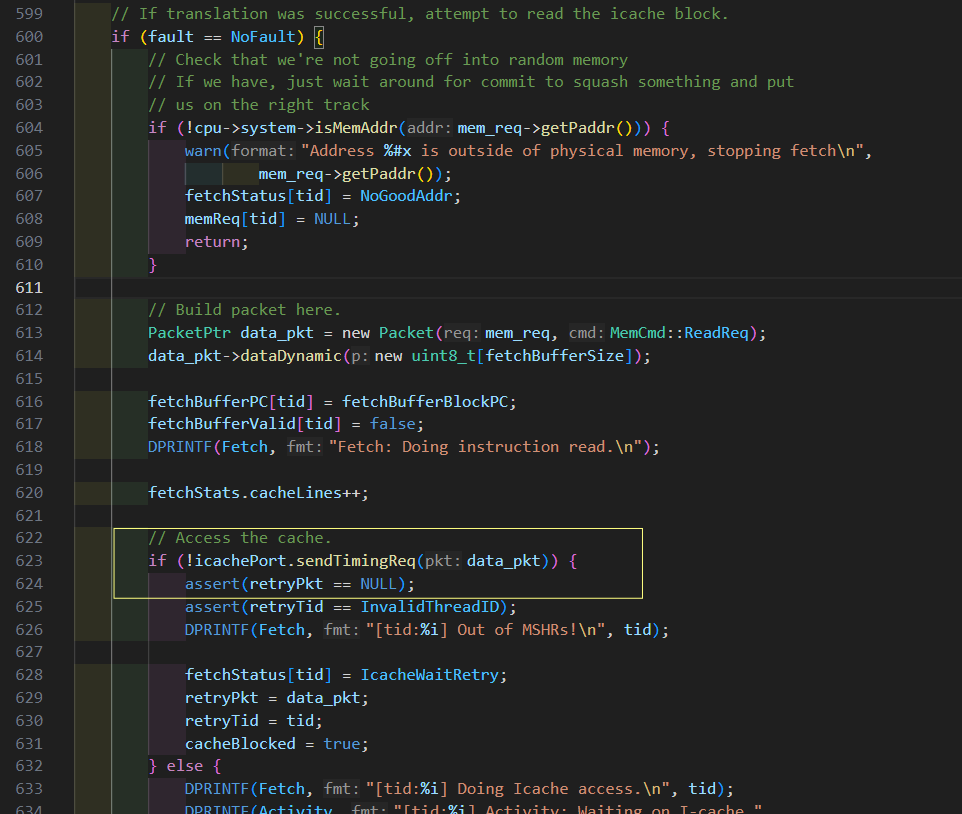
if (!(curMacroop || inRom)) { if (dec_ptr->instReady()) { staticInst = dec_ptr->decode(this_pc); // Increment stat of fetched instructions. cpu->fetchStats[tid]->numInsts++; if (staticInst->isMacroop()) { curMacroop = staticInst; } else { pcOffset = 0; } } else { // We need more bytes for this instruction so blkOffset and // pcOffset will be updated break; } }
while (dep_inst) { DPRINTF(IQ, "Waking up a dependent instruction, [sn:%llu] " "PC %s.\n", dep_inst->seqNum, dep_inst->pcState());
// Might want to give more information to the instruction // so that it knows which of its source registers is // ready. However that would mean that the dependency // graph entries would need to hold the src_reg_idx. dep_inst->markSrcRegReady();
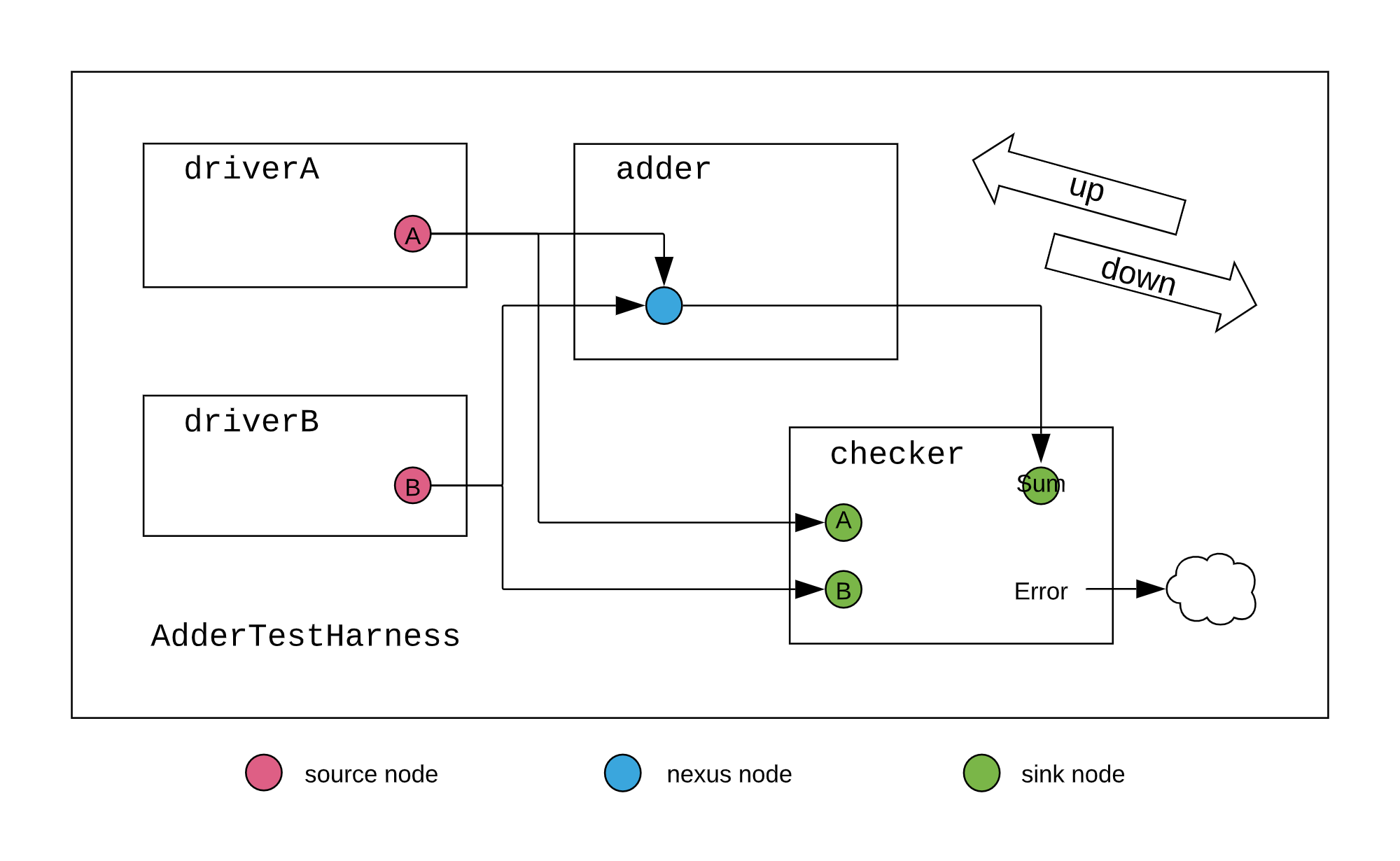
/** driver (source) * drives one random number on multiple outputs */ class AdderDriver(width: Int, numOutputs: Int)(implicit p: Parameters) extends LazyModule { val node = new AdderDriverNode(Seq.fill(numOutputs)(DownwardParam(width)))
lazy val module = new LazyModuleImp(this) { // check that node parameters converge after negotiation val negotiatedWidths = node.edges.out.map(_.width) require(negotiatedWidths.forall(_ == negotiatedWidths.head), "outputs must all have agreed on same width") val finalWidth = negotiatedWidths.head
// generate random addend (notice the use of the negotiated width) val randomAddend = FibonacciLFSR.maxPeriod(finalWidth)
class AdderMonitor(width: Int, numOperands: Int)(implicit p: Parameters) extends LazyModule { val nodeSeq = Seq.fill(numOperands) { new AdderMonitorNode(UpwardParam(width)) } val nodeSum = new AdderMonitorNode(UpwardParam(width))
lazy val module = new LazyModuleImp(this) { val io = IO(new Bundle { val error = Output(Bool()) })
class AdderTestHarness()(implicit p: Parameters) extends LazyModule { val numOperands = 2 val adder = LazyModule(new Adder) // 8 will be the downward-traveling widths from our drivers val drivers = Seq.fill(numOperands) { LazyModule(new AdderDriver(width = 8, numOutputs = 2)) } // 4 will be the upward-traveling width from our monitor val monitor = LazyModule(new AdderMonitor(width = 4, numOperands = numOperands))
// create edges via binding operators between nodes in order to define a complete graph drivers.foreach{ driver => adder.node := driver.node }
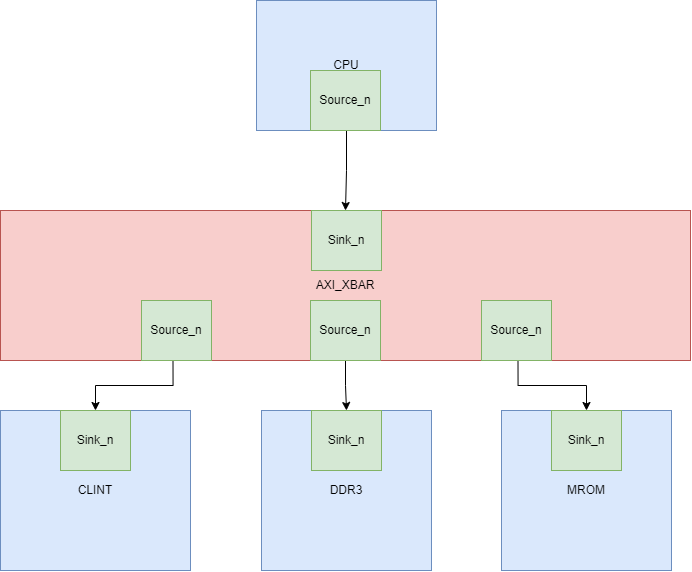
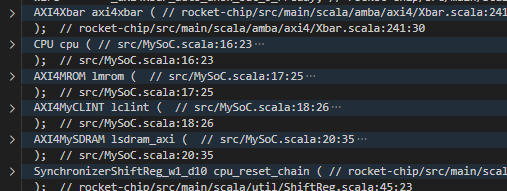
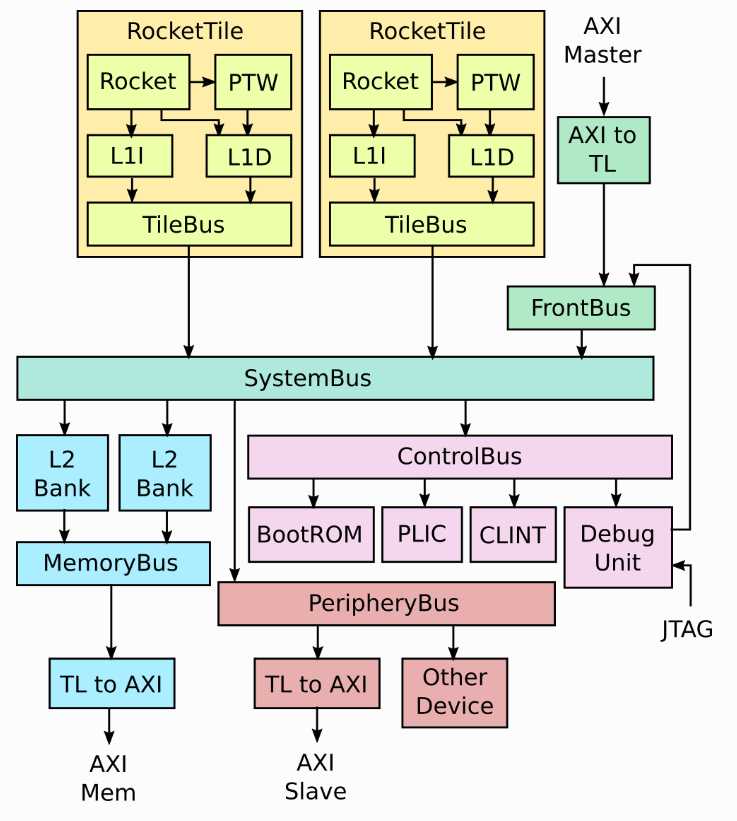
class MySoC(implicit p: Parameters) extends LazyModule { val xbar = AXI4Xbar() val cpu = LazyModule(new CPU(idBits = ChipLinkParam.idBits)) val lmrom = LazyModule(new AXI4MROM(AddressSet.misaligned(0x20000000, 0x10000))) val lclint = LazyModule(new AXI4MyCLINT(AddressSet.misaligned(0x10000000, 0x10000))) val sdramAddressSet = AddressSet.misaligned(0x80000000L, 0x2000000) val lsdram_axi = Some(LazyModule(new AXI4MySDRAM(sdramAddressSet)))
List(lsdram_axi.get.node ,lmrom.node, lclint.node).map(_ := xbar) xbar := cpu.masterNode override lazy val module = new Impl class Impl extends LazyModuleImp(this) with DontTouch {
cpu.module.reset := SynchronizerShiftReg(reset.asBool, 10) || reset.asBool cpu.module.slave := DontCare val intr_from_chipSlave = IO(Input(Bool())) cpu.module.interrupt := intr_from_chipSlave val sdramBundle = lsdram_axi.get.module.sdram_bundle val sdram = IO(chiselTypeOf(sdramBundle)) sdram <> sdramBundle } }
deffeed[T <: Data](sink: IrrevocableIO[T], source: IrrevocableIO[T], noise: T): Unit = { // irrevocable requires that we not lower valid val hold = RegInit(false.B) when (sink.valid) { hold := true.B } when (sink.fire) { hold := false.B }
def out: Seq[(BO, EO)] = { require( instantiated, s"$name.out should not be called until after instantiation of its parent LazyModule.module has begun" ) bundleOut.zip(edgesOut) }
abstract class MixedNode[DI, UI, EI, BI <: Data, DO, UO, EO, BO <: Data]( val inner: InwardNodeImp[DI, UI, EI, BI], val outer: OutwardNodeImp[DO, UO, EO, BO] )
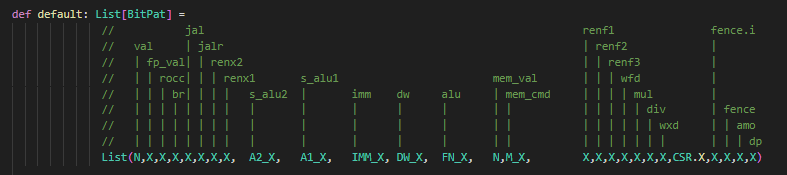
abstract class AbstractALU(implicit p: Parameters) extends CoreModule()(p) { val io = IO(new Bundle { val dw = Input(UInt(SZ_DW.W)) val fn = Input(UInt(SZ_ALU_FN.W)) val in2 = Input(UInt(xLen.W)) val in1 = Input(UInt(xLen.W)) val out = Output(UInt(xLen.W)) val adder_out = Output(UInt(xLen.W)) val cmp_out = Output(Bool()) }) }
首先dw的含义就是是32位还是64位
重点讲解一下移位操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// SLL, SRL, SRA val (shamt, shin_r) = if (xLen == 32) (io.in2(4,0), io.in1) else { require(xLen == 64) val shin_hi_32 = Fill(32, isSub(io.fn) && io.in1(31)) val shin_hi = Mux(io.dw === DW_64, io.in1(63,32), shin_hi_32) val shamt = Cat(io.in2(5) & (io.dw === DW_64), io.in2(4,0)) (shamt, Cat(shin_hi, io.in1(31,0))) } val shin = Mux(shiftReverse(io.fn), Reverse(shin_r), shin_r) val shout_r = (Cat(isSub(io.fn) & shin(xLen-1), shin).asSInt >> shamt)(xLen-1,0) val shout_l = Reverse(shout_r) val shout = Mux(io.fn === FN_SR || io.fn === FN_SRA || io.fn === FN_BEXT, shout_r, 0.U) | Mux(io.fn === FN_SL, shout_l, 0.U)
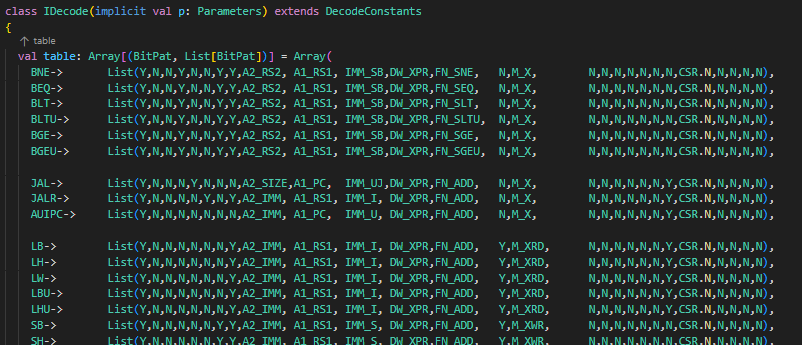
// TODO This should be a method on BitPat private def hasDontCare(bp: BitPat): Boolean = bp.mask.bitCount != bp.width // Pads BitPats that are safe to pad (no don't cares), errors otherwise private def padBP(bp: BitPat, width: Int): BitPat = { if (bp.width == width) bp else { require(!hasDontCare(bp), s"Cannot pad '$bp' to '$width' bits because it has don't cares") val diff = width - bp.width require(diff > 0, s"Cannot pad '$bp' to '$width' because it is already '${bp.width}' bits wide!") BitPat(0.U(diff.W)) ## bp } }
def apply(addr: UInt, default: Seq[BitPat], mappingIn: Iterable[(BitPat, Seq[BitPat])]): Seq[UInt] = { val nElts = default.size require(mappingIn.forall(_._2.size == nElts), s"All Seq[BitPat] must be of the same length, got $nElts vs. ${mappingIn.find(_._2.size != nElts).get}" )
val elementsGrouped = mappingIn.map(_._2).transpose val elementWidths = elementsGrouped.zip(default).map { case (elts, default) => (default :: elts.toList).map(_.getWidth).max } val resultWidth = elementWidths.sum
val elementIndices = elementWidths.scan(resultWidth - 1) { case (l, r) => l - r }
// All BitPats that correspond to a given element in the result must have the same width in the // chisel3 decoder. We will zero pad any BitPats that are too small so long as they dont have // any don't cares. If there are don't cares, it is an error and the user needs to pad the // BitPat themselves val defaultsPadded = default.zip(elementWidths).map { case (bp, w) => padBP(bp, w) } val mappingInPadded = mappingIn.map { case (in, elts) => in -> elts.zip(elementWidths).map { case (bp, w) => padBP(bp, w) } } val decoded = apply(addr, defaultsPadded.reduce(_ ## _), mappingInPadded.map { case (in, out) => (in, out.reduce(_ ## _)) })
when ((s2_valid && !icache.io.resp.valid) || (s2_valid && icache.io.resp.valid && !f3_ready)) { s0_valid := (!s2_tlb_resp.ae.inst && !s2_tlb_resp.pf.inst) || s2_is_replay || s2_tlb_miss s0_vpc := s2_vpc s0_is_replay := s2_valid && icache.io.resp.valid // When this is not a replay (it queried the BPDs, we should use f3 resp in the replaying s1) s0_s1_use_f3_bpd_resp := !s2_is_replay s0_ghist := s2_ghist s0_tsrc := s2_tsrc f1_clear := true.B } .elsewhen (s2_valid && f3_ready) { when (s1_valid && s1_vpc === f2_predicted_target && !f2_correct_f1_ghist) { // We trust our prediction of what the global history for the next branch should be s2_ghist := f2_predicted_ghist } when ((s1_valid && (s1_vpc =/= f2_predicted_target || f2_correct_f1_ghist)) || !s1_valid) { f1_clear := true.B
if (nBanks == 1) { // In the single bank case every bank sees the history including the previous bank new_history := DontCare new_history.current_saw_branch_not_taken := false.B val saw_not_taken_branch = not_taken_branches =/= 0.U || current_saw_branch_not_taken new_history.old_history := Mux(cfi_is_br && cfi_taken && cfi_valid , histories(0) << 1 | 1.U, Mux(saw_not_taken_branch , histories(0) << 1, histories(0))) } else { // In the two bank case every bank ignore the history added by the previous bank val base = histories(1) val cfi_in_bank_0 = cfi_valid && cfi_taken && cfi_idx_fixed < bankWidth.U val ignore_second_bank = cfi_in_bank_0 || mayNotBeDualBanked(addr)
val bank_data = f3_data((b+1)*bankWidth*16-1, b*bankWidth*16) val bank_mask = Wire(Vec(bankWidth, Bool())) val bank_insts = Wire(Vec(bankWidth, UInt(32.W)))
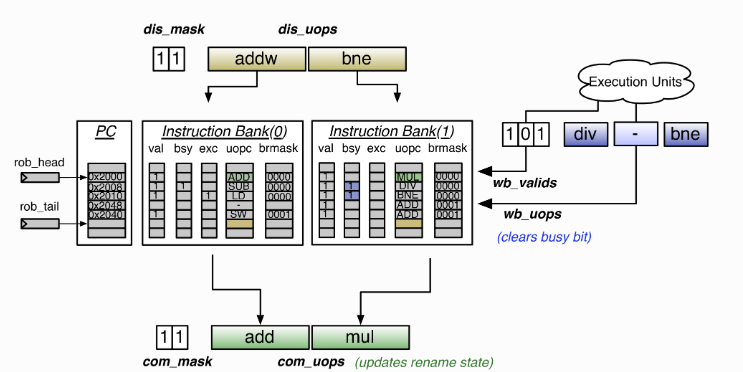
bank_mask和之前提到的mask类似,揭示了一个bank每条指令是否有效,
当f3的指令有效并且没有收到重定向信号,就对bank_mask赋值
1 2 3 4 5 6
for (b <- 0 until nBanks) { .....
for (w <- 0 until bankWidth) { val i = (b * bankWidth) + w bank_mask(w) := f3.io.deq.valid && f3_imemresp.mask(i) && valid && !redirect_found
for (w <- 0 until bankWidth) { ... val brsigs = Wire(new BranchDecodeSignals) if (w == 0) { val inst0 = Cat(bank_data(15,0), f3_prev_half) val inst1 = bank_data(31,0) ...
when (bank_prev_is_half) { bank_insts(w) := inst0 ... if (b > 0) { val inst0b = Cat(bank_data(15,0), last_inst) ... when (f3_bank_mask(b-1)) { bank_insts(w) := inst0b f3_fetch_bundle.insts(i) := inst0b f3_fetch_bundle.exp_insts(i) := exp_inst0b brsigs := bpd_decoder0b.io.out } } } .otherwise { bank_insts(w) := inst1 ... } valid := true.B } else { val inst = Wire(UInt(32.W)) .. val pc = f3_aligned_pc + (i << log2Ceil(coreInstBytes)).U ... bank_insts(w) := inst ... if (w == 1) { // Need special case since 0th instruction may carry over the wrap around inst := bank_data(47,16) valid := bank_prev_is_half || !(bank_mask(0) && !isRVC(bank_insts(0))) } else if (w == bankWidth - 1) { inst := Cat(0.U(16.W), bank_data(bankWidth*16-1,(bankWidth-1)*16)) valid := !((bank_mask(w-1) && !isRVC(bank_insts(w-1))) || !isRVC(inst)) } else { inst := bank_data(w*16+32-1,w*16) valid := !(bank_mask(w-1) && !isRVC(bank_insts(w-1))) } } last_inst = bank_insts(bankWidth-1)(15,0) ... }
val inst0 = Cat(bank_data(15,0), f3_prev_half) val inst1 = bank_data(31,0) val exp_inst0 = ExpandRVC(inst0) val exp_inst1 = ExpandRVC(inst1)//inst0和1分别对应了RVI指令和未知的指令 val pc0 = (f3_aligned_pc + (i << log2Ceil(coreInstBytes)).U - 2.U) val pc1 = (f3_aligned_pc + (i << log2Ceil(coreInstBytes)).U)
for (b <- 0 until nBanks) { ... for (w <- 0 until bankWidth) { ... val brsigs = Wire(new BranchDecodeSignals) if (w == 0) { val inst0 = Cat(bank_data(15,0), f3_prev_half) val inst1 = bank_data(31,0) val exp_inst0 = ExpandRVC(inst0) val exp_inst1 = ExpandRVC(inst1)//inst0和1分别对应了RVI指令和未知的指令 val pc0 = (f3_aligned_pc + (i << log2Ceil(coreInstBytes)).U - 2.U) val pc1 = (f3_aligned_pc + (i << log2Ceil(coreInstBytes)).U) val bpd_decoder0 = Module(new BranchDecode) bpd_decoder0.io.inst := exp_inst0 bpd_decoder0.io.pc := pc0 val bpd_decoder1 = Module(new BranchDecode) bpd_decoder1.io.inst := exp_inst1 bpd_decoder1.io.pc := pc1
when (bank_prev_is_half) { bank_insts(w) := inst0 ... bpu.io.pc := pc0 brsigs := bpd_decoder0.io.out//指令不完整.且一定为32位,选择decode0的br信号 ... if (b > 0) { val inst0b = Cat(bank_data(15,0), last_inst) val exp_inst0b = ExpandRVC(inst0b) val bpd_decoder0b = Module(new BranchDecode) bpd_decoder0b.io.inst := exp_inst0b bpd_decoder0b.io.pc := pc0
for (b <- 0 until nBanks) { for (w <- 0 until bankWidth) { val i = (b * bankWidth) + w val pc = (bankAlign(io.enq.bits.pc) + (i << 1).U) in_mask(i) := io.enq.valid && io.enq.bits.mask(i) ...
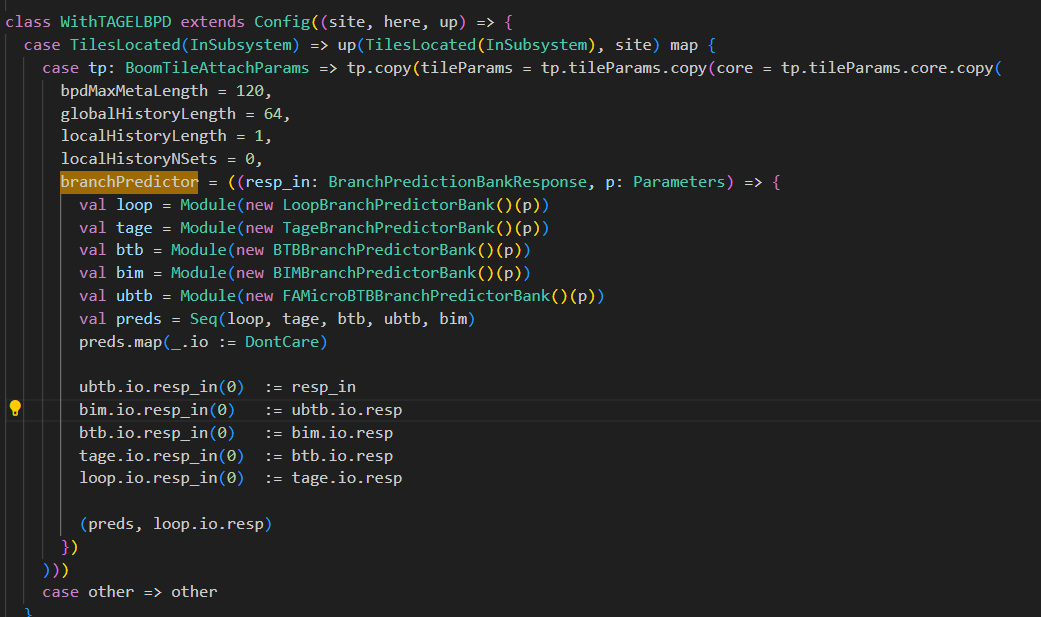
val bpdStr = new StringBuilder bpdStr.append(BoomCoreStringPrefix("==Branch Predictor Memory Sizes==\n")) val banked_predictors = (0 until nBanks) map ( b => { val m = Module(if (useBPD) new ComposedBranchPredictorBank else new NullBranchPredictorBank) for ((n, d, w) <- m.mems) { bpdStr.append(BoomCoreStringPrefix(f"bank$b $n: $d x $w = ${d * w / 8}")) total_memsize = total_memsize + d * w / 8 } m }) bpdStr.append(BoomCoreStringPrefix(f"Total bpd size: ${total_memsize / 1024} KB\n")) override def toString: String = bpdStr.toString
val io = IO(new Bundle { val f0_valid = Input(Bool()) val f0_pc = Input(UInt(vaddrBitsExtended.W)) val f0_mask = Input(UInt(bankWidth.W)) // Local history not available until end of f1 val f1_ghist = Input(UInt(globalHistoryLength.W)) val f1_lhist = Input(UInt(localHistoryLength.W))
val resp_in = Input(Vec(nInputs, new BranchPredictionBankResponse)) val resp = Output(new BranchPredictionBankResponse)
// Store the meta as a UInt, use width inference to figure out the shape val f3_meta = Output(UInt(bpdMaxMetaLength.W))
val f3_fire = Input(Bool())
val update = Input(Valid(new BranchPredictionBankUpdate)) })
val alloc_way = { val r_metas = Cat(VecInit(meta.map(e => VecInit(e.map(_.tag)))).asUInt, s1_idx(tagSz-1,0)) val l = log2Ceil(nWays) val nChunks = (r_metas.getWidth + l - 1) / l val chunks = (0 until nChunks) map { i => r_metas(min((i+1)*l, r_metas.getWidth)-1, i*l) } chunks.reduce(_^_) } s1_meta.write_way := Mux(s1_hits.reduce(_||_), PriorityEncoder(s1_hit_ohs.map(_.asUInt).reduce(_|_)), alloc_way)
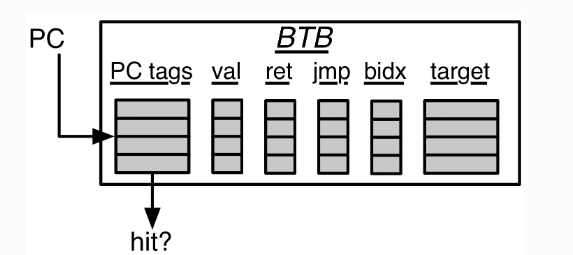
// Write the BTB with the target when (s1_update.valid && s1_update.bits.cfi_taken && s1_update.bits.cfi_idx.valid && s1_update.bits.is_commit_update) { btb(s1_update_write_way)(s1_update_cfi_idx).offset := new_offset_value }
// Write the meta for (w <- 0 until bankWidth) { when (s1_update.valid && s1_update.bits.is_commit_update && (s1_update.bits.br_mask(w) || (s1_update_cfi_idx === w.U && s1_update.bits.cfi_taken && s1_update.bits.cfi_idx.valid))) { val was_taken = (s1_update_cfi_idx === w.U && s1_update.bits.cfi_idx.valid && (s1_update.bits.cfi_taken || s1_update.bits.cfi_is_jal))
class BoomRAS(implicit p: Parameters) extends BoomModule()(p) { val io = IO(new Bundle { val read_idx = Input(UInt(log2Ceil(nRasEntries).W)) val read_addr = Output(UInt(vaddrBitsExtended.W))
val write_valid = Input(Bool()) val write_idx = Input(UInt(log2Ceil(nRasEntries).W)) val write_addr = Input(UInt(vaddrBitsExtended.W)) }) val ras = Reg(Vec(nRasEntries, UInt(vaddrBitsExtended.W)))
var altpred = io.resp_in(0).f3(w).taken val final_altpred = WireInit(io.resp_in(0).f3(w).taken) var provided = false.B var provider = 0.U io.resp.f3(w).taken := io.resp_in(0).f3(w).taken // for (i <- 0 until tageNTables) { val hit = f3_resps(i)(w).valid val ctr = f3_resps(i)(w).bits.ctr when (hit) { io.resp.f3(w).taken := Mux(ctr === 3.U || ctr === 4.U, altpred, ctr(2))//预测可能不准 final_altpred := altpred }
class DecodeUnitIo(implicit p: Parameters) extends BoomBundle { val enq = new Bundle { val uop = Input(new MicroOp()) } val deq = new Bundle { val uop = Output(new MicroOp()) }
// from CSRFile val status = Input(new freechips.rocketchip.rocket.MStatus()) val csr_decode = Flipped(new freechips.rocketchip.rocket.CSRDecodeIO) val interrupt = Input(Bool()) val interrupt_cause = Input(UInt(xLen.W)) }
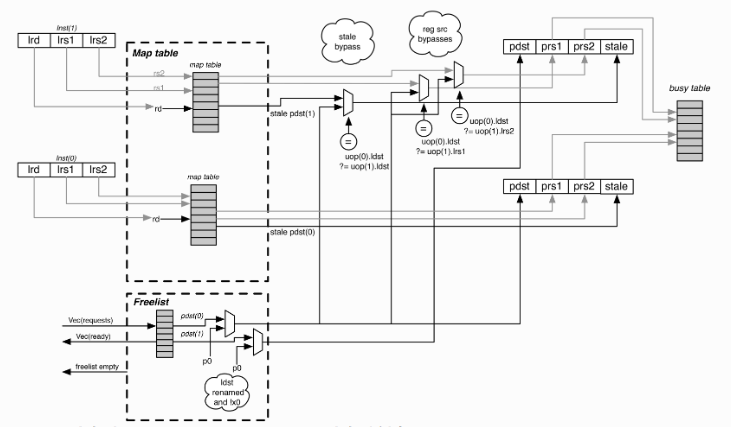
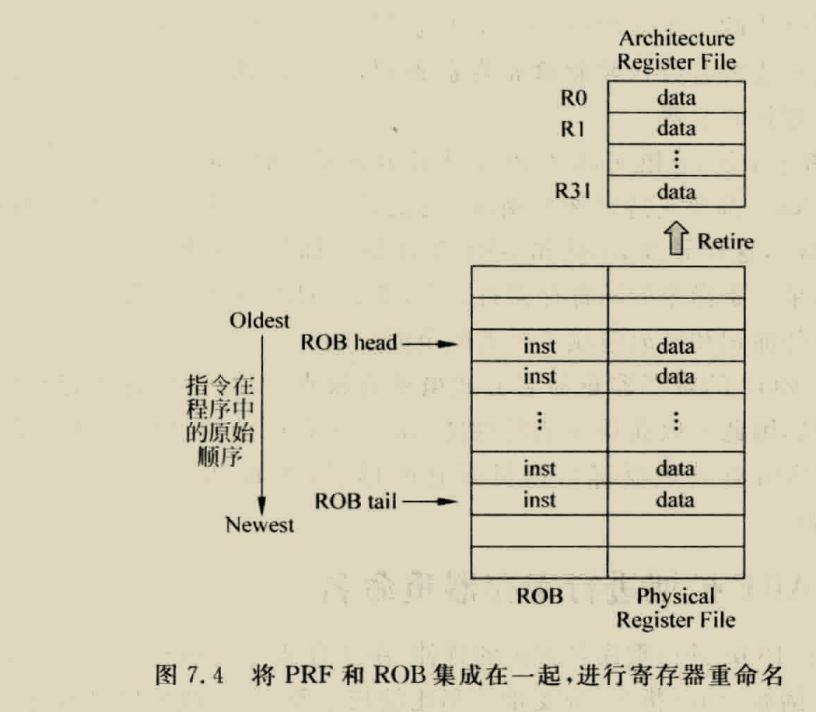
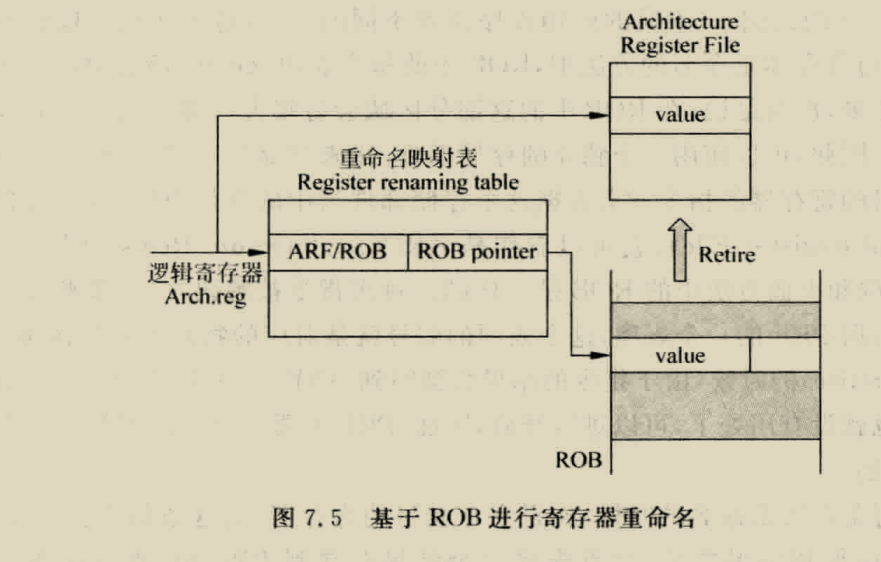
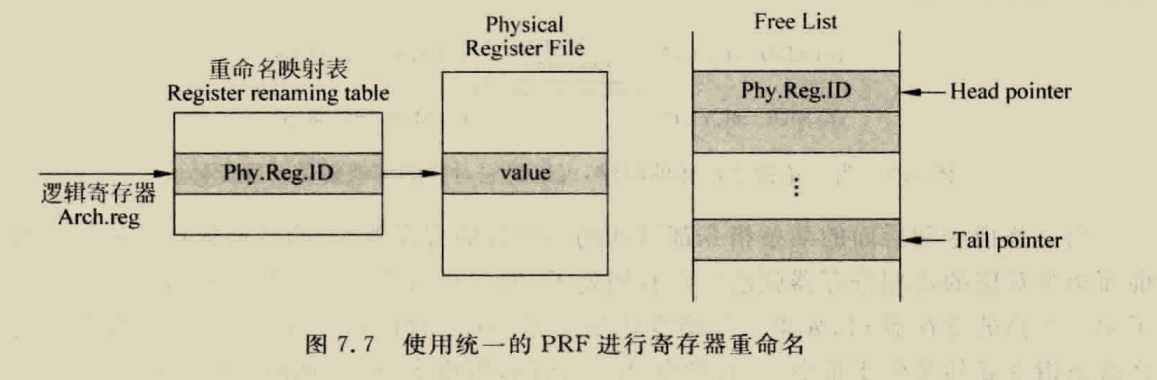
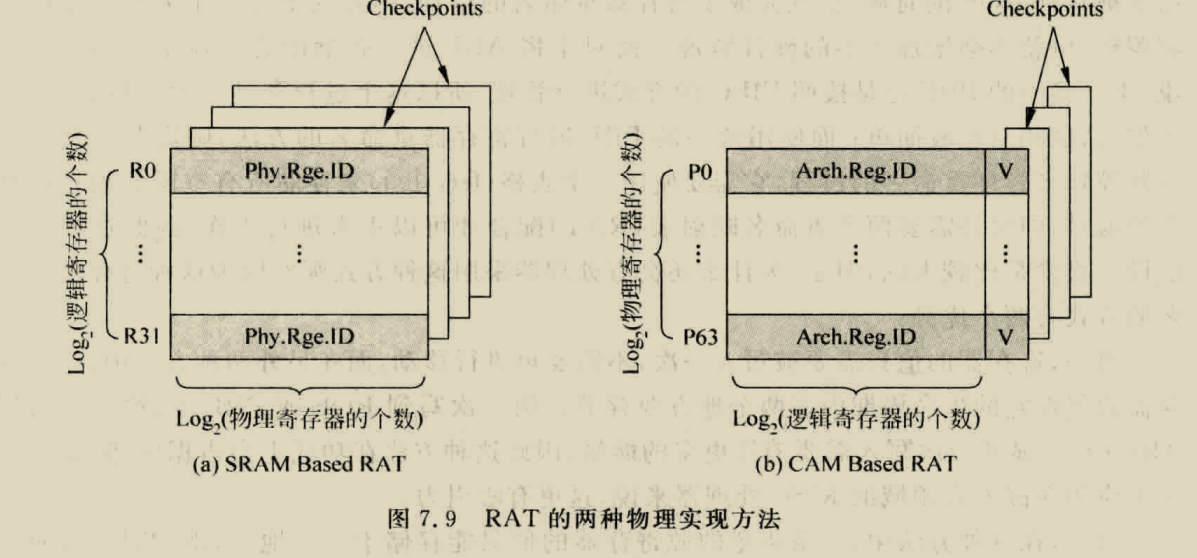
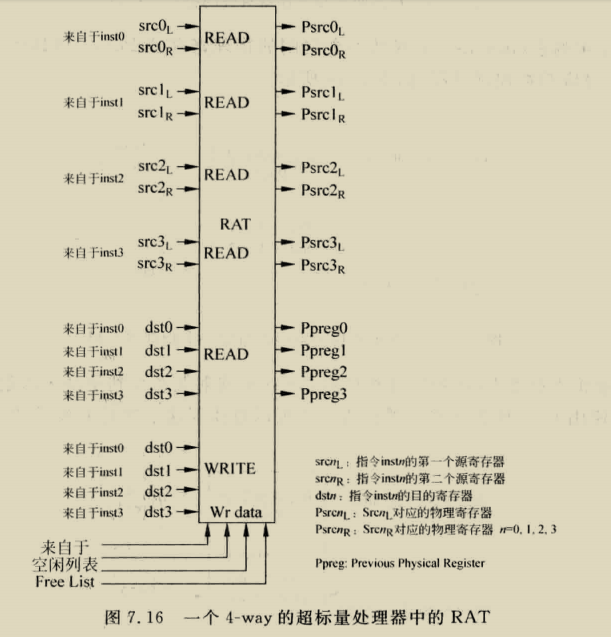
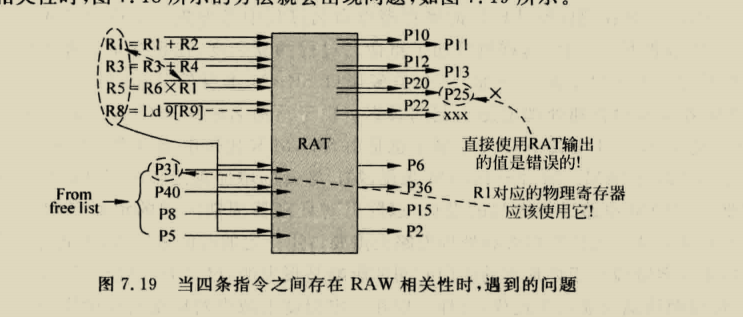
BOOM RENAME
boom采用的是统一的PRF结构,
RAT就是图中的map table,busytable揭示每个物理寄存器的忙碌情况,
Busy table
busytable在唤醒阶段把寄存器设置为空闲,在rename阶段将寄存器设置为忙
首先列出输入输出信号
1 2 3 4 5 6 7 8 9 10 11
val io = IO(new BoomBundle()(p) { val ren_uops = Input(Vec(plWidth, new MicroOp)) val busy_resps = Output(Vec(plWidth, new BusyResp)) val rebusy_reqs = Input(Vec(plWidth, Bool()))
val wb_pdsts = Input(Vec(numWbPorts, UInt(pregSz.W))) val wb_valids = Input(Vec(numWbPorts, Bool()))
val debug = new Bundle { val busytable = Output(Bits(numPregs.W)) } })
val busy_table = RegInit(0.U(numPregs.W)) // Unbusy written back registers. val busy_table_wb = busy_table & ~(io.wb_pdsts zip io.wb_valids) .map {case (pdst, valid) => UIntToOH(pdst) & Fill(numPregs, valid.asUInt)}.reduce(_|_) // Rebusy newly allocated registers. val busy_table_next = busy_table_wb | (io.ren_uops zip io.rebusy_reqs) .map {case (uop, req) => UIntToOH(uop.pdst) & Fill(numPregs, req.asUInt)}.reduce(_|_)
busy_table := busy_table_next
接下来是主要模块,首先将写回的寄存器unbusy,我们看busy_table_wb,首先看io.wb_pdsts zip io.wb_valids表示将两个作为一个元组,然后使用map函数,对每个院组都进行操作,操作的内容是后面{}内容,这个{首先使用模式匹配case,然后输出的值是=>后面的值,也就是把写回的寄存器变成oh编码,然后把这些元素通过reduce按位或,得到写回寄存器的oh编码,然后取非再&busytable,就相当于释放了写回的寄存器
之后的busy_table_next,就是为寄存器分配忙位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// Read the busy table. for (i <- 0 until plWidth) { val prs1_was_bypassed = (0 until i).map(j => io.ren_uops(i).lrs1 === io.ren_uops(j).ldst && io.rebusy_reqs(j)).foldLeft(false.B)(_||_) val prs2_was_bypassed = (0 until i).map(j => io.ren_uops(i).lrs2 === io.ren_uops(j).ldst && io.rebusy_reqs(j)).foldLeft(false.B)(_||_) val prs3_was_bypassed = (0 until i).map(j => io.ren_uops(i).lrs3 === io.ren_uops(j).ldst && io.rebusy_reqs(j)).foldLeft(false.B)(_||_)
class MapReq(val lregSz: Int) extends Bundle { val lrs1 = UInt(lregSz.W) val lrs2 = UInt(lregSz.W) val lrs3 = UInt(lregSz.W) val ldst = UInt(lregSz.W) }
class MapResp(val pregSz: Int) extends Bundle { val prs1 = UInt(pregSz.W) val prs2 = UInt(pregSz.W) val prs3 = UInt(pregSz.W) val stale_pdst = UInt(pregSz.W) }
class RemapReq(val lregSz: Int, val pregSz: Int) extends Bundle { val ldst = UInt(lregSz.W) val pdst = UInt(pregSz.W) val valid = Bool() }
val io = IO(new BoomBundle()(p) { // Logical sources -> physical sources. val map_reqs = Input(Vec(plWidth, new MapReq(lregSz))) val map_resps = Output(Vec(plWidth, new MapResp(pregSz)))
// Remapping an ldst to a newly allocated pdst? val remap_reqs = Input(Vec(plWidth, new RemapReq(lregSz, pregSz)))
// Dispatching branches: need to take snapshots of table state. val ren_br_tags = Input(Vec(plWidth, Valid(UInt(brTagSz.W))))
// Signals for restoring state following misspeculation. val brupdate = Input(new BrUpdateInfo) val rollback = Input(Bool()) })
// The map table register array and its branch snapshots. val map_table = RegInit(VecInit(Seq.fill(numLregs){0.U(pregSz.W)})) val br_snapshots = Reg(Vec(maxBrCount, Vec(numLregs, UInt(pregSz.W))))
// The intermediate states of the map table following modification by each pipeline slot. val remap_table = Wire(Vec(plWidth+1, Vec(numLregs, UInt(pregSz.W))))
// Uops requesting changes to the map table. val remap_pdsts = io.remap_reqs map (_.pdst) val remap_ldsts_oh = io.remap_reqs map (req => UIntToOH(req.ldst) & Fill(numLregs, req.valid.asUInt))
// Figure out the new mappings seen by each pipeline slot. for (i <- 0 until numLregs) { if (i == 0 && !float) { for (j <- 0 until plWidth+1) { remap_table(j)(i) := 0.U } } else { val remapped_row = (remap_ldsts_oh.map(ldst => ldst(i)) zip remap_pdsts) .scanLeft(map_table(i)) {case (pdst, (ldst, new_pdst)) => Mux(ldst, new_pdst, pdst)}
for (j <- 0 until plWidth+1) { remap_table(j)(i) := remapped_row(j) } } }
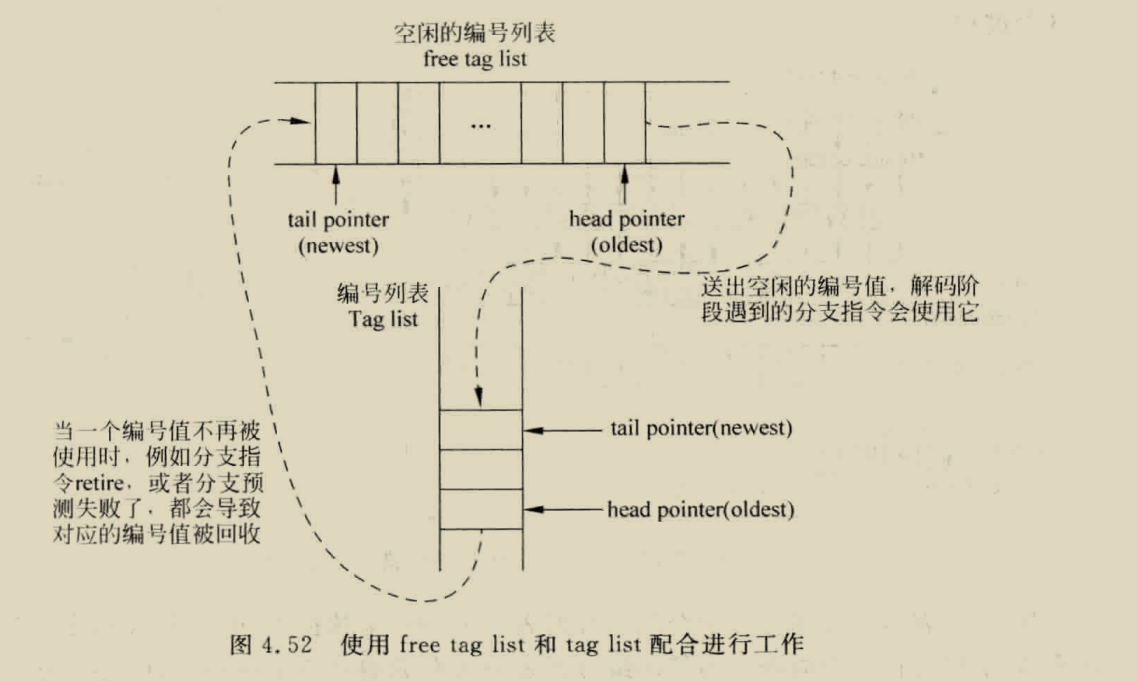
// The free list register array and its branch allocation lists. val free_list = RegInit(UInt(numPregs.W), ~(1.U(numPregs.W))) val br_alloc_lists = Reg(Vec(maxBrCount, UInt(numPregs.W)))
// Select pregs from the free list. val sels = SelectFirstN(free_list, plWidth) val sel_fire = Wire(Vec(plWidth, Bool()))
// Allocations seen by branches in each pipeline slot. val allocs = io.alloc_pregs map (a => UIntToOH(a.bits)) val alloc_masks = (allocs zip io.reqs).scanRight(0.U(n.W)) { case ((a,r),m) => m | a & Fill(n,r) }
// Masks that modify the freelist array. val sel_mask = (sels zip sel_fire) map { case (s,f) => s & Fill(n,f) } reduce(_|_) val br_deallocs = br_alloc_lists(io.brupdate.b2.uop.br_tag) & Fill(n, io.brupdate.b2.mispredict) val dealloc_mask = io.dealloc_pregs.map(d => UIntToOH(d.bits)(numPregs-1,0) & Fill(n,d.valid)).reduce(_|_) | br_deallocs
val br_slots = VecInit(io.ren_br_tags.map(tag => tag.valid)).asUInt
// Pipeline logic | hookup outputs. for (w <- 0 until plWidth) { val can_sel = sels(w).orR val r_valid = RegInit(false.B) val r_sel = RegEnable(OHToUInt(sels(w)), sel_fire(w))
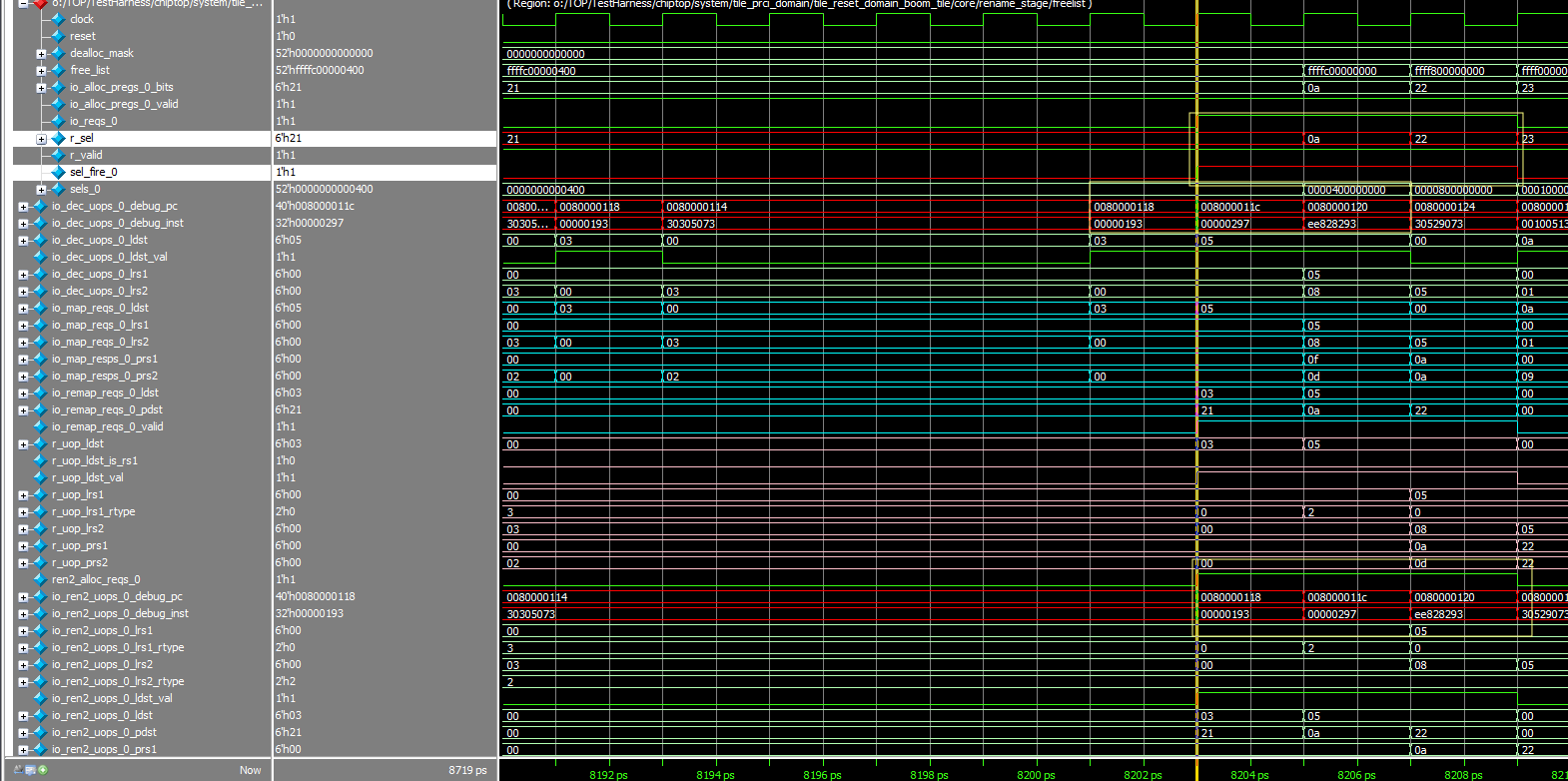
assert (ren2_alloc_reqs zip freelist.io.alloc_pregs map {case (r,p) => !r || p.bits =/= 0.U} reduce (_&&_), "[rename-stage] A uop is trying to allocate the zero physical register.")
// incoming microops from rename2 val ren_uops = Vec(coreWidth, Flipped(DecoupledIO(new MicroOp)))
// outgoing microops to issue queues // N issues each accept up to dispatchWidth uops // dispatchWidth may vary between issue queues val dis_uops = MixedVec(issueParams.map(ip=>Vec(ip.dispatchWidth, DecoupledIO(new MicroOp))))
/** * Tries to dispatch as many uops as it can to issue queues, * which may accept fewer than coreWidth per cycle. * When dispatchWidth == coreWidth, its behavior differs * from the BasicDispatcher in that it will only stall dispatch when * an issue queue required by a uop is full. */ class CompactingDispatcher(implicit p: Parameters) extends Dispatcher { issueParams.map(ip => require(ip.dispatchWidth >= ip.issueWidth))
val ren_readys = Wire(Vec(issueParams.size, Vec(coreWidth, Bool())))
for (((ip, dis), rdy) <- issueParams zip io.dis_uops zip ren_readys) { val ren = Wire(Vec(coreWidth, Decoupled(new MicroOp))) ren <> io.ren_uops
val uses_iq = ren map (u => (u.bits.iq_type & ip.iqType.U).orR)
// Only request an issue slot if the uop needs to enter that queue. (ren zip io.ren_uops zip uses_iq) foreach {case ((u,v),q) => u.valid := v.valid && q}
val compactor = Module(new Compactor(coreWidth, ip.dispatchWidth, new MicroOp)) compactor.io.in <> ren dis <> compactor.io.out
// The queue is considered ready if the uop doesn't use it. rdy := ren zip uses_iq map {case (u,q) => u.ready || !q} }
(ren_readys.reduce((r,i) => VecInit(r zip i map {case (r,i) => r && i})) zip io.ren_uops) foreach {case (r,u) => u.ready := r} }
for (i <- 0 until numWakeupPorts) { val wb_resp = io.wb_resps(i) val wb_uop = wb_resp.bits.uop val row_idx = GetRowIdx(wb_uop.rob_idx) when (wb_resp.valid && MatchBank(GetBankIdx(wb_uop.rob_idx))) { rob_bsy(row_idx) := false.B rob_unsafe(row_idx) := false.B rob_predicated(row_idx) := wb_resp.bits.predicated } }
for (clr_rob_idx <- io.lsu_clr_bsy) { when (clr_rob_idx.valid && MatchBank(GetBankIdx(clr_rob_idx.bits))) { val cidx = GetRowIdx(clr_rob_idx.bits) rob_bsy(cidx) := false.B rob_unsafe(cidx) := false.B assert (rob_val(cidx) === true.B, "[rob] store writing back to invalid entry.") assert (rob_bsy(cidx) === true.B, "[rob] store writing back to a not-busy entry.") } } for (clr <- io.lsu_clr_unsafe) { when (clr.valid && MatchBank(GetBankIdx(clr.bits))) { val cidx = GetRowIdx(clr.bits) rob_unsafe(cidx) := false.B } } when (io.lxcpt.valid && MatchBank(GetBankIdx(io.lxcpt.bits.uop.rob_idx))) { rob_exception(GetRowIdx(io.lxcpt.bits.uop.rob_idx)) := true.B when (io.lxcpt.bits.cause =/= MINI_EXCEPTION_MEM_ORDERING) { // In the case of a mem-ordering failure, the failing load will have been marked safe already. assert(rob_unsafe(GetRowIdx(io.lxcpt.bits.uop.rob_idx)), "An instruction marked as safe is causing an exception") } } can_throw_exception(w) := rob_val(rob_head) && rob_exception(rob_head)
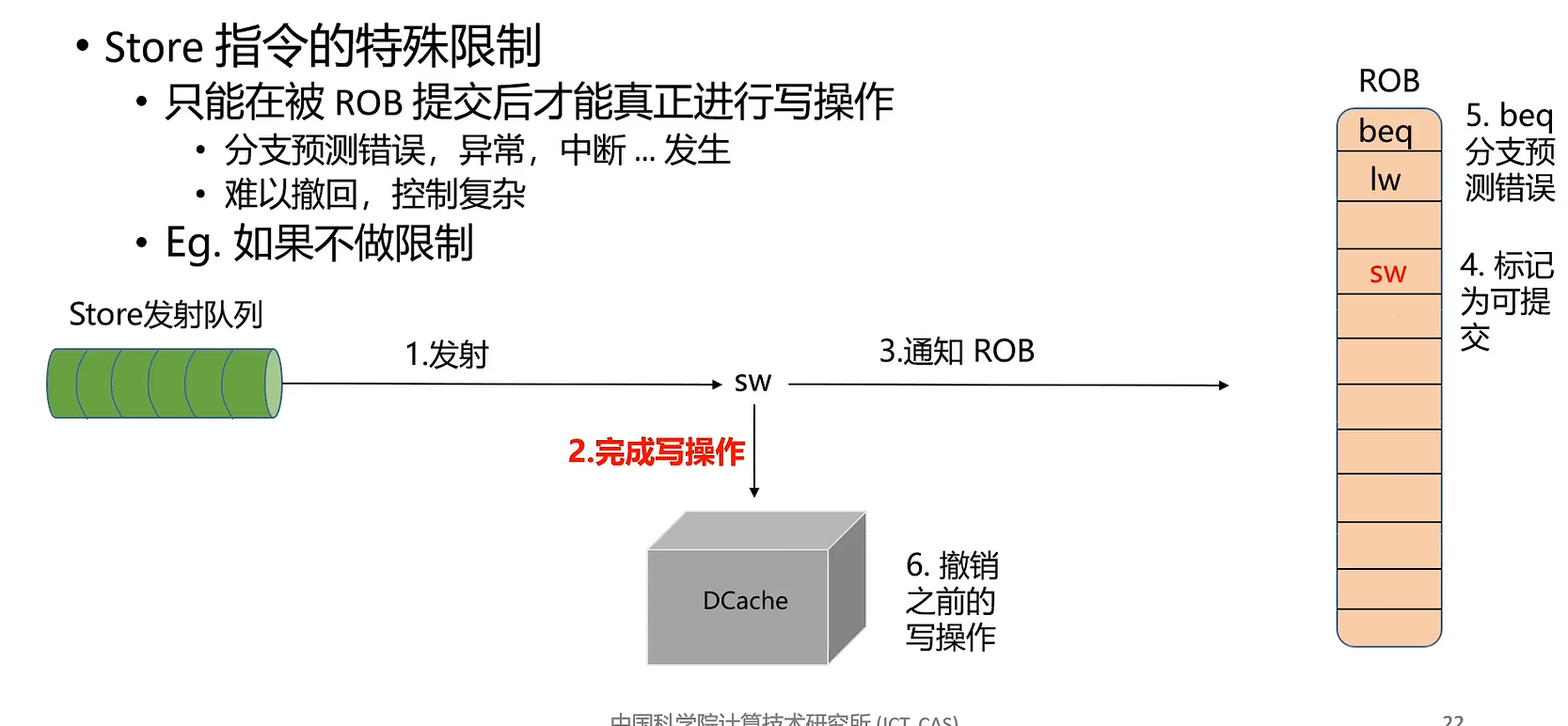
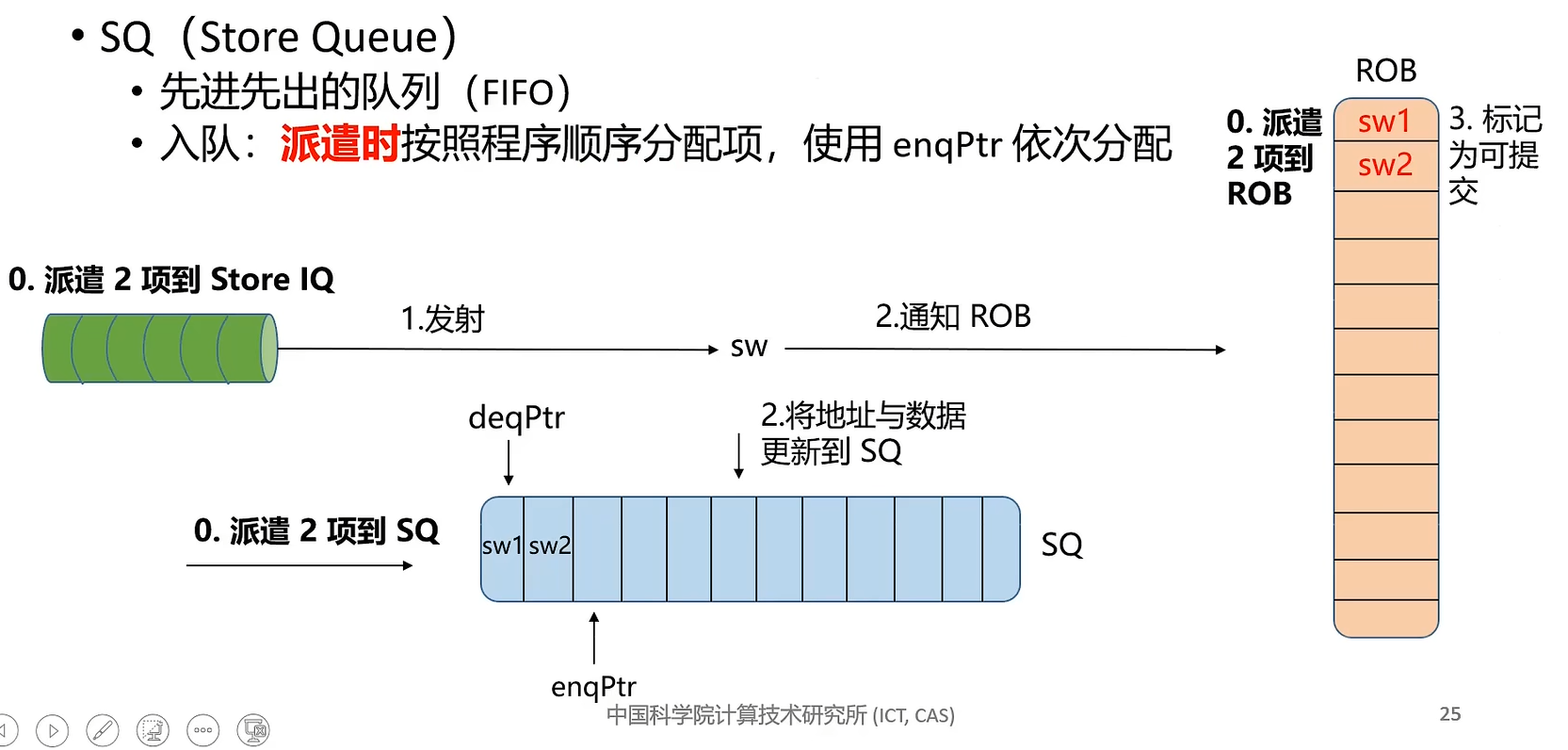
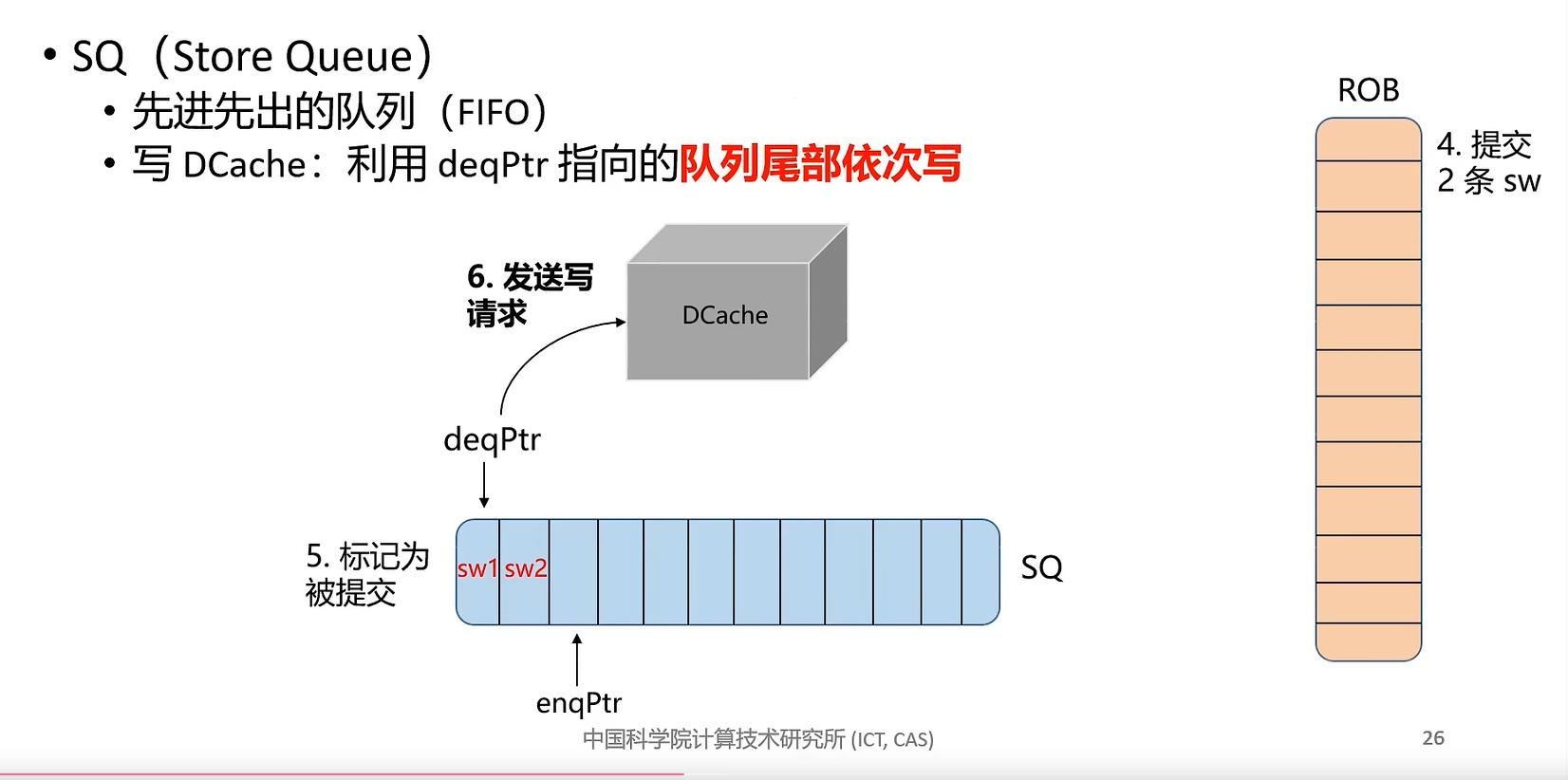
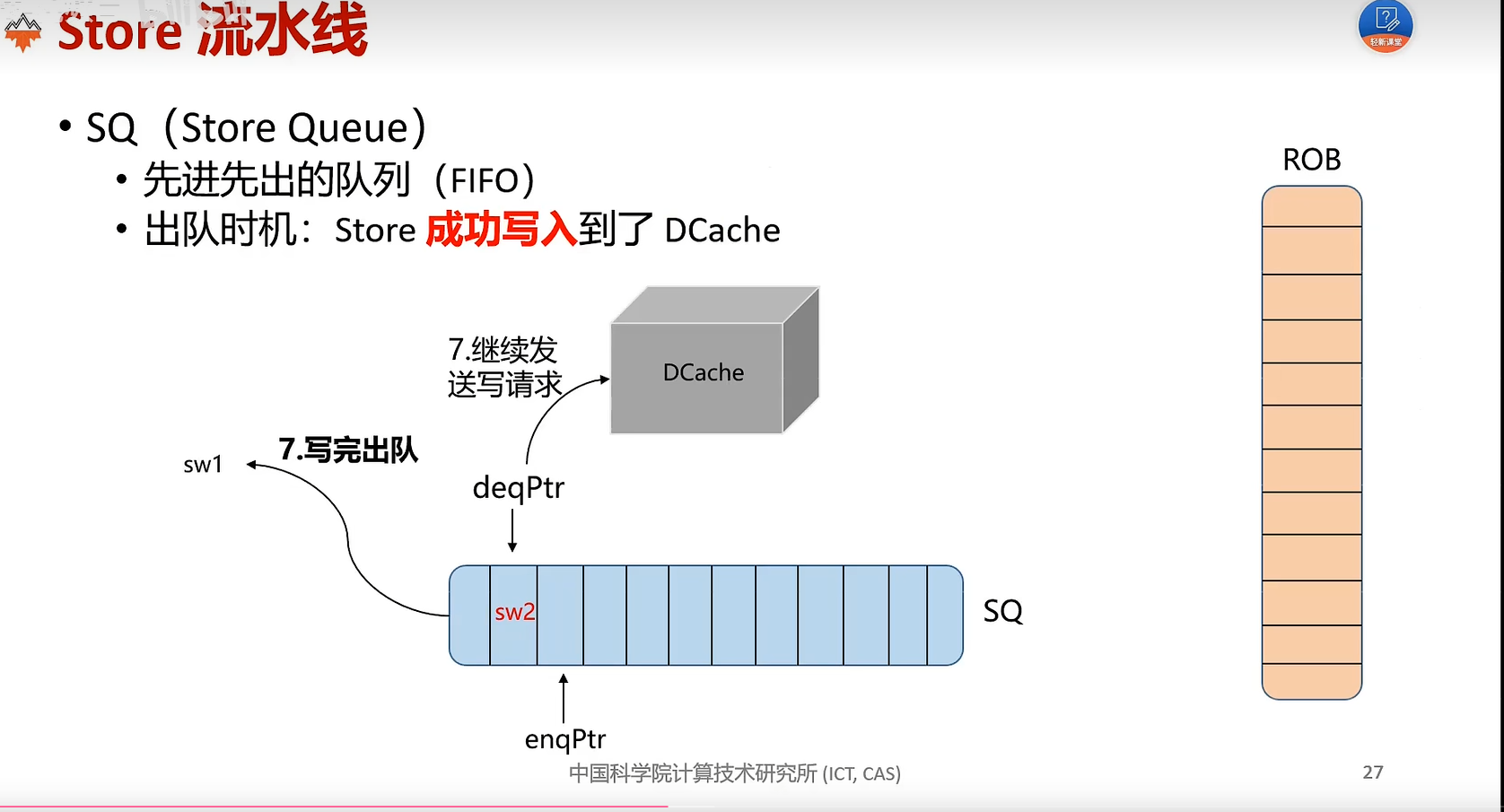
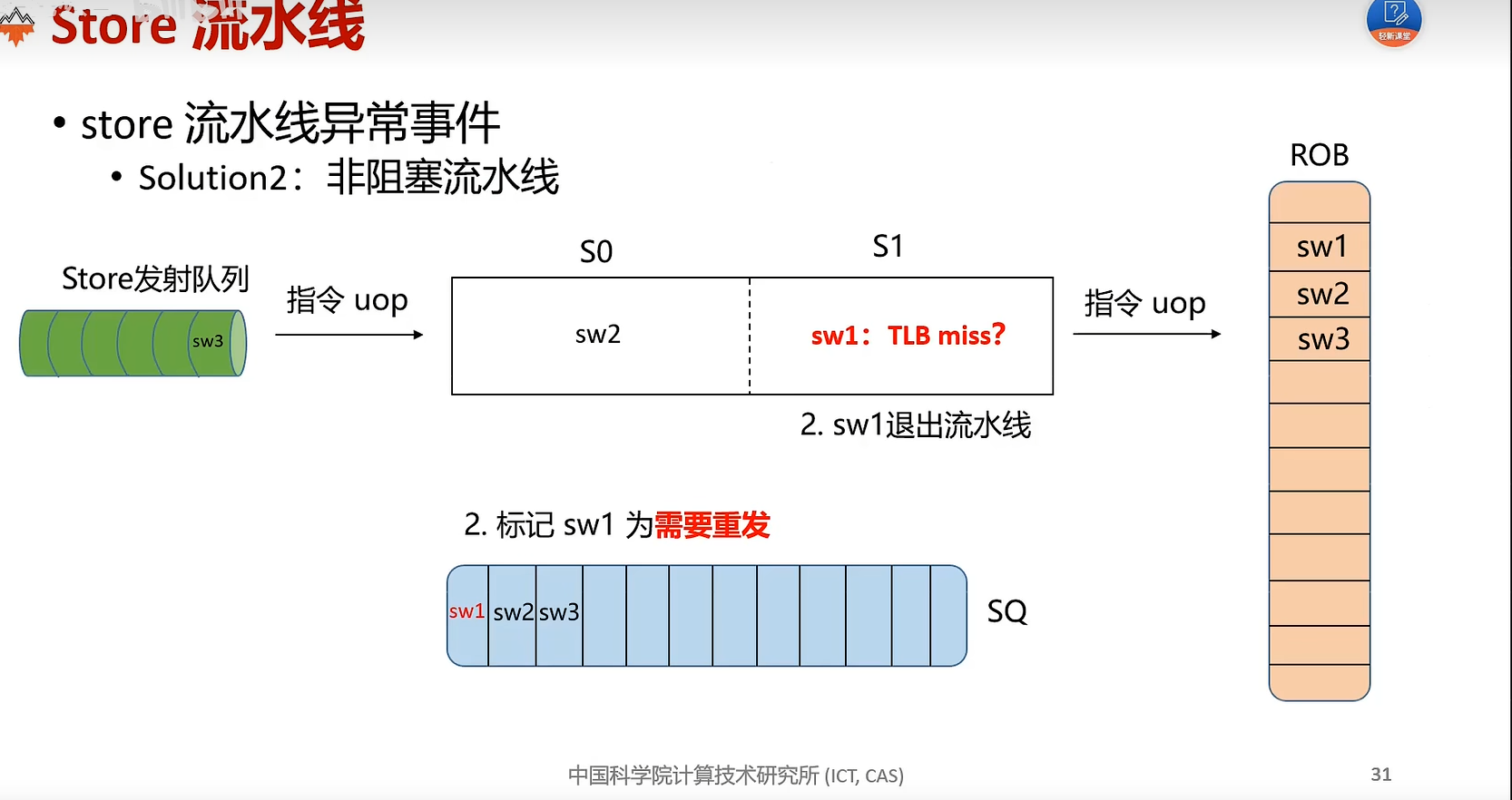
store 命令特殊之处在于不需要写回 (Write Back) 寄存器,因此 LSU 模块将 store 指令从存储队列提交后,store 命令就可以从流水线中退休,即 io.lsu_clr_bsy 信号将 store 指令置为 safe 时同时置为 unbusy。
MINI_EXCEPTION_MEM_ORDERING 是指发生存储-加载顺序异常(Memory Ordering Failure)。当 store 指令与其后的 load 指令有共同的目标地址时,类似 RAW 冲突,若 load 指令在 store 之前发射(Issue),load 命令将从内存中读取错误的值。处理器在提交 store 指令时需要检查是否发生了 Memory Ordering Failure,如果有,则需要刷新流水线、修改重命名映射表等。Memory Ordering Failure 是处理器乱序执行带来的问题,是处理器设计的缺陷,不属于 RISCV 规定的异常,采用 MINI_EXCEPTION_MEM_ORSERING 来弥补。
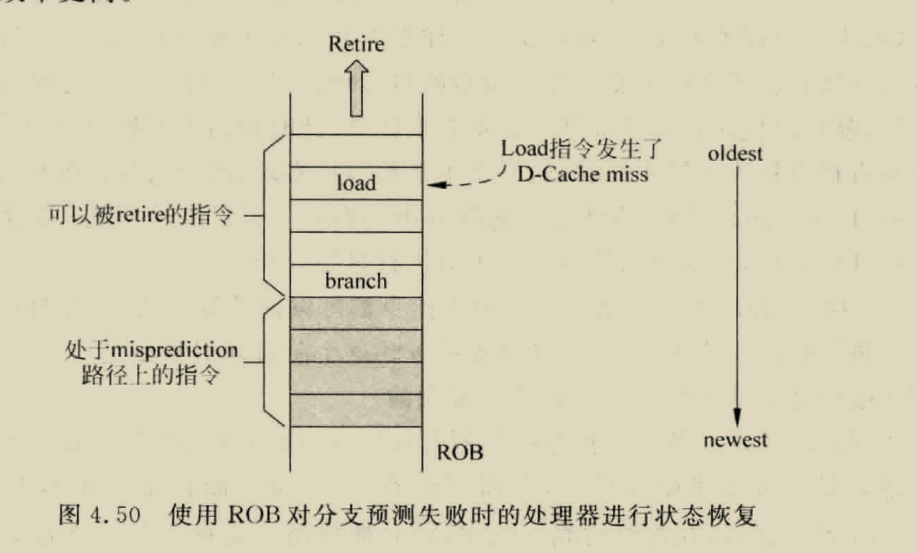
will_commit 这一段代码的主要作用是为 head 指针指向的 ROB 行中的每一个 bank 生成 will_commit 信号,will_commit 信号指示下一时钟周期指令是否提交。will_commit 信号有效的条件是:
该 bank 中的指令可以提交
该 bank 中的指令不会抛出异常
ROB 的提交没有被封锁
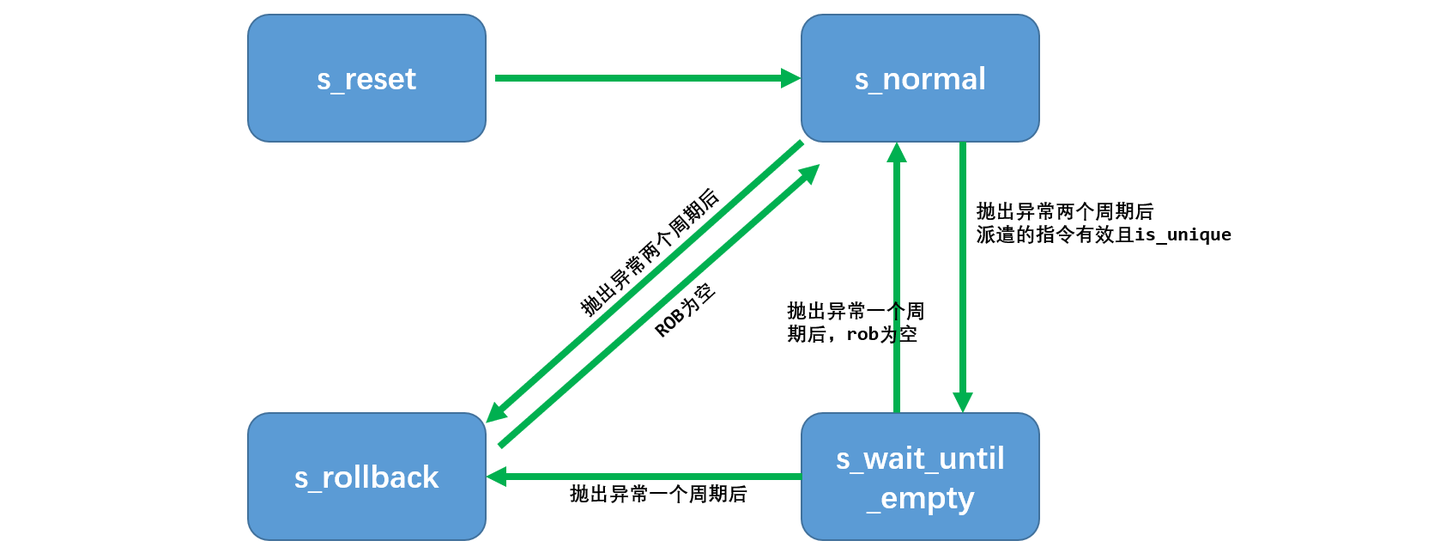
block_commit block_commit=1 时,ROB 既不能提交指令,也不能抛出异常。对于每个bank,都有一个自己的 block_commit 信号,只要一个 bank 被封锁提交,其后的所有 bank 都将被封锁提交。block_commit 信号保证 ROB 只能顺序提交。若 ROB 处于 s_rollback 或 s_reset 状态,或在前两个时钟周期内抛出异常时,block_commit将被初始化为1,即该行所有指令的提交都被封锁。
// ----------------------------------------------- // Kill speculated entries on branch mispredict for (i <- 0 until numRobRows) { val br_mask = rob_uop(i).br_mask
//kill instruction if mispredict & br mask match when (IsKilledByBranch(io.brupdate, br_mask)) { rob_val(i) := false.B rob_uop(i.U).debug_inst := BUBBLE } .elsewhen (rob_val(i)) { // clear speculation bit even on correct speculation rob_uop(i).br_mask := GetNewBrMask(io.brupdate, br_mask) } }
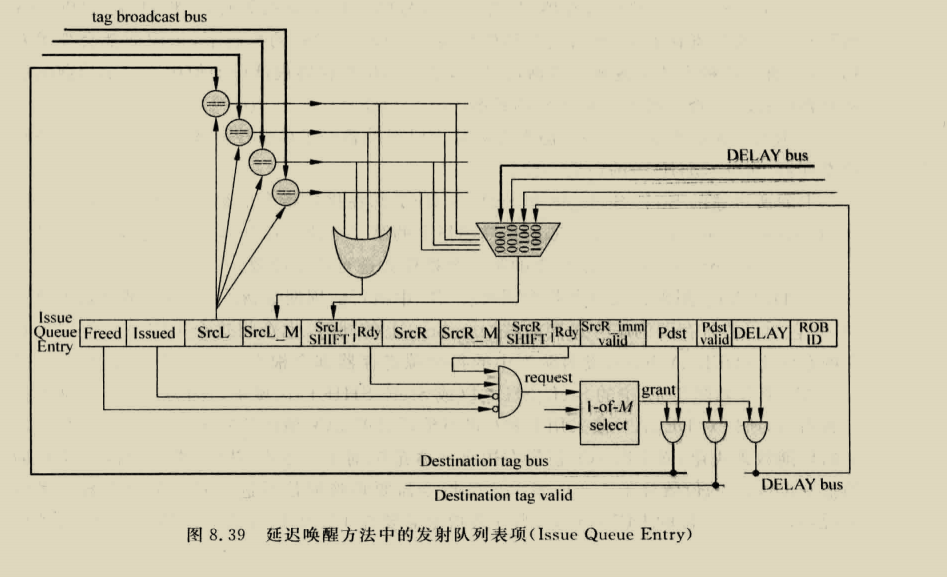
trait IssueUnitConstants { // invalid : slot holds no valid uop. // s_valid_1: slot holds a valid uop. // s_valid_2: slot holds a store-like uop that may be broken into two micro-ops. val s_invalid :: s_valid_1 :: s_valid_2 :: Nil = Enum(3) }
// slot invalid? // slot is valid, holding 1 uop // slot is valid, holds 2 uops (like a store) def is_invalid = state === s_invalid def is_valid = state =/= s_invalid
val next_state = Wire(UInt()) // the next state of this slot (which might then get moved to a new slot) val next_uopc = Wire(UInt()) // the next uopc of this slot (which might then get moved to a new slot) val next_lrs1_rtype = Wire(UInt()) // the next reg type of this slot (which might then get moved to a new slot) val next_lrs2_rtype = Wire(UInt()) // the next reg type of this slot (which might then get moved to a new slot)
val state = RegInit(s_invalid) val p1 = RegInit(false.B) val p2 = RegInit(false.B) val p3 = RegInit(false.B) val ppred = RegInit(false.B)
// Poison if woken up by speculative load. // Poison lasts 1 cycle (as ldMiss will come on the next cycle). // SO if poisoned is true, set it to false! val p1_poisoned = RegInit(false.B) val p2_poisoned = RegInit(false.B) p1_poisoned := false.B p2_poisoned := false.B val next_p1_poisoned = Mux(io.in_uop.valid, io.in_uop.bits.iw_p1_poisoned, p1_poisoned) val next_p2_poisoned = Mux(io.in_uop.valid, io.in_uop.bits.iw_p2_poisoned, p2_poisoned)
val slot_uop = RegInit(NullMicroOp) val next_uop = Mux(io.in_uop.valid, io.in_uop.bits, slot_uop)
//----------------------------------------------------------------------------- // next slot state computation // compute the next state for THIS entry slot (in a collasping queue, the // current uop may get moved elsewhere, and a new uop can enter
when (io.kill) { state := s_invalid } .elsewhen (io.in_uop.valid) { state := io.in_uop.bits.iw_state } .elsewhen (io.clear) { state := s_invalid } .otherwise { state := next_state }
//----------------------------------------------------------------------------- // "update" state // compute the next state for the micro-op in this slot. This micro-op may // be moved elsewhere, so the "next_state" travels with it.
// these signals are the "next_p*" for the current slot's micro-op. // they are important for shifting the current slot_uop up to an other entry. val next_p1 = WireInit(p1) val next_p2 = WireInit(p2) val next_p3 = WireInit(p3) val next_ppred = WireInit(ppred)
when (io.ldspec_miss && next_p1_poisoned) { assert(next_uop.prs1 =/= 0.U, "Poison bit can't be set for prs1=x0!") p1 := false.B } when (io.ldspec_miss && next_p2_poisoned) { assert(next_uop.prs2 =/= 0.U, "Poison bit can't be set for prs2=x0!") p2 := false.B }
for (i <- 0 until numWakeupPorts) { when (io.wakeup_ports(i).valid && (io.wakeup_ports(i).bits.pdst === next_uop.prs1)) { p1 := true.B } when (io.wakeup_ports(i).valid && (io.wakeup_ports(i).bits.pdst === next_uop.prs2)) { p2 := true.B } when (io.wakeup_ports(i).valid && (io.wakeup_ports(i).bits.pdst === next_uop.prs3)) { p3 := true.B } } when (io.pred_wakeup_port.valid && io.pred_wakeup_port.bits === next_uop.ppred) { ppred := true.B }
for (w <- 0 until memWidth) { assert (!(io.spec_ld_wakeup(w).valid && io.spec_ld_wakeup(w).bits === 0.U), "Loads to x0 should never speculatively wakeup other instructions") }
// TODO disable if FP IQ. for (w <- 0 until memWidth) { when (io.spec_ld_wakeup(w).valid && io.spec_ld_wakeup(w).bits === next_uop.prs1 && next_uop.lrs1_rtype === RT_FIX) { p1 := true.B p1_poisoned := true.B assert (!next_p1_poisoned) } when (io.spec_ld_wakeup(w).valid && io.spec_ld_wakeup(w).bits === next_uop.prs2 && next_uop.lrs2_rtype === RT_FIX) { p2 := true.B p2_poisoned := true.B assert (!next_p2_poisoned) } }
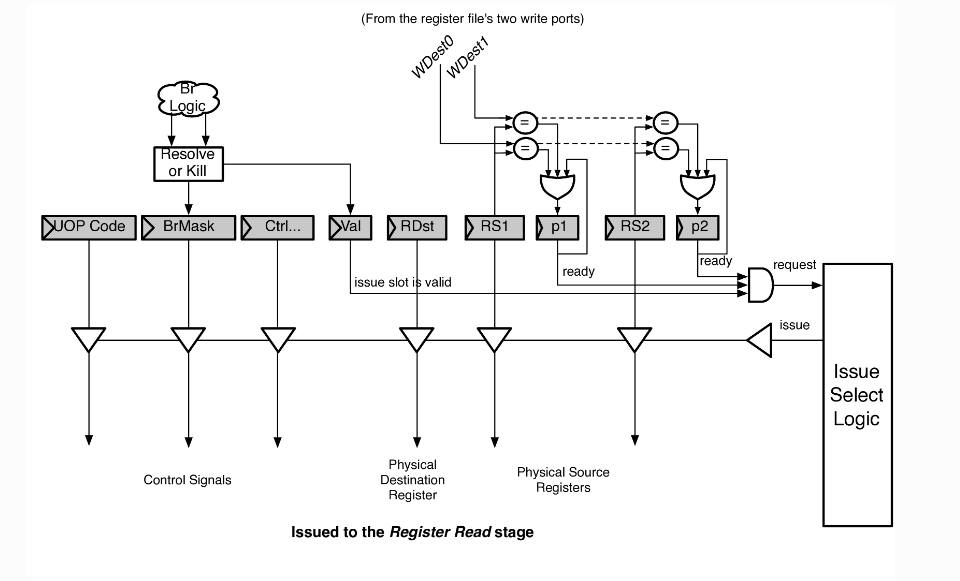
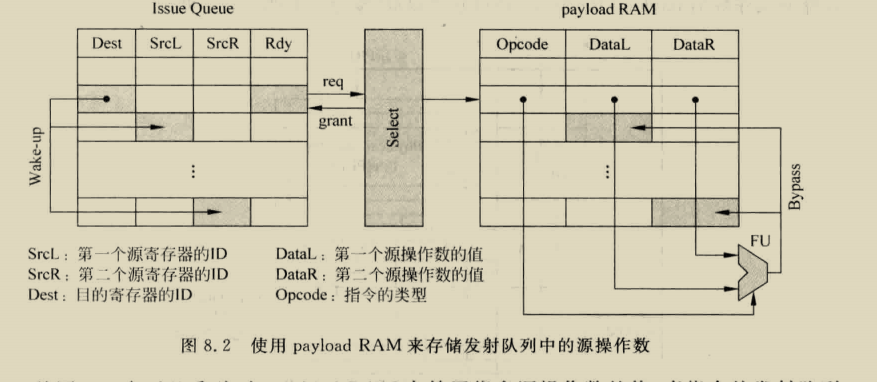
/** * Abstract top level issue unit * * @param numIssueSlots depth of issue queue * @param issueWidth amoutn of operations that can be issued at once * @param numWakeupPorts number of wakeup ports for issue unit * @param iqType type of issue queue (mem, int, fp) */ abstract class IssueUnit( val numIssueSlots: Int, val issueWidth: Int, val numWakeupPorts: Int, val iqType: BigInt, val dispatchWidth: Int) (implicit p: Parameters) extends BoomModule with IssueUnitConstants { val io = IO(new IssueUnitIO(issueWidth, numWakeupPorts, dispatchWidth))
//------------------------------------------------------------- // Set up the dispatch uops // special case "storing" 2 uops within one issue slot.
val dis_uops = Array.fill(dispatchWidth) {Wire(new MicroOp())} for (w <- 0 until dispatchWidth) { dis_uops(w) := io.dis_uops(w).bits dis_uops(w).iw_p1_poisoned := false.B dis_uops(w).iw_p2_poisoned := false.B dis_uops(w).iw_state := s_valid_1
if (iqType == IQT_MEM.litValue || iqType == IQT_INT.litValue) { // For StoreAddrGen for Int, or AMOAddrGen, we go to addr gen state when ((io.dis_uops(w).bits.uopc === uopSTA && io.dis_uops(w).bits.lrs2_rtype === RT_FIX) || io.dis_uops(w).bits.uopc === uopAMO_AG) { dis_uops(w).iw_state := s_valid_2 // For store addr gen for FP, rs2 is the FP register, and we don't wait for that here } .elsewhen (io.dis_uops(w).bits.uopc === uopSTA && io.dis_uops(w).bits.lrs2_rtype =/= RT_FIX) { dis_uops(w).lrs2_rtype := RT_X dis_uops(w).prs2_busy := false.B } dis_uops(w).prs3_busy := false.B } else if (iqType == IQT_FP.litValue) { // FP "StoreAddrGen" is really storeDataGen, and rs1 is the integer address register when (io.dis_uops(w).bits.uopc === uopSTA) { dis_uops(w).lrs1_rtype := RT_X dis_uops(w).prs1_busy := false.B } }
val slots = for (i <- 0 until numIssueSlots) yield { val slot = Module(new IssueSlot(numWakeupPorts)); slot } val issue_slots = VecInit(slots.map(_.io))
for (i <- 0 until numIssueSlots) { issue_slots(i).wakeup_ports := io.wakeup_ports issue_slots(i).pred_wakeup_port := io.pred_wakeup_port issue_slots(i).spec_ld_wakeup := io.spec_ld_wakeup issue_slots(i).ldspec_miss := io.ld_miss issue_slots(i).brupdate := io.brupdate issue_slots(i).kill := io.flush_pipeline }
//------------------------------------------------------------- // Dispatch/Entry Logic // find a slot to enter a new dispatched instruction
val entry_wen_oh_array = Array.fill(numIssueSlots,dispatchWidth){false.B} var allocated = VecInit(Seq.fill(dispatchWidth){false.B}) // did an instruction find an issue width?
for (i <- 0 until numIssueSlots) { var next_allocated = Wire(Vec(dispatchWidth, Bool())) var can_allocate = !(issue_slots(i).valid)
for (w <- 0 until dispatchWidth) { entry_wen_oh_array(i)(w) = can_allocate && !(allocated(w))
// if we can find an issue slot, do we actually need it? // also, translate from Scala data structures to Chisel Vecs for (i <- 0 until numIssueSlots) { val temp_uop_val = Wire(Vec(dispatchWidth, Bool()))
for (w <- 0 until dispatchWidth) { // TODO add ctrl bit for "allocates iss_slot" temp_uop_val(w) := io.dis_uops(w).valid && !dis_uops(w).exception && !dis_uops(w).is_fence && !dis_uops(w).is_fencei && entry_wen_oh_array(i)(w) } entry_wen_oh(i) := temp_uop_val.asUInt }
for (w <- 0 until dispatchWidth) { io.dis_uops(w).ready := allocated(w) }
// TODO can we use flatten to get an array of bools on issue_slot(*).request? val lo_request_not_satisfied = Array.fill(numIssueSlots){Bool()} val hi_request_not_satisfied = Array.fill(numIssueSlots){Bool()}
for (i <- 0 until numIssueSlots) { lo_request_not_satisfied(i) = issue_slots(i).request hi_request_not_satisfied(i) = issue_slots(i).request_hp issue_slots(i).grant := false.B // default }
for (w <- 0 until issueWidth) { var port_issued = false.B
// first look for high priority requests for (i <- 0 until numIssueSlots) { val can_allocate = (issue_slots(i).uop.fu_code & io.fu_types(w)) =/= 0.U
val port_already_in_use = port_issued port_issued = (lo_request_not_satisfied(i) && can_allocate) | port_issued // if request is 0, stay 0. only stay 1 if request is true and can't allocate or port already in use lo_request_not_satisfied(i) = (lo_request_not_satisfied(i) && (!can_allocate || port_already_in_use)) } }
//------------------------------------------------------------- // Figure out how much to shift entries by
val maxShift = dispatchWidth val vacants = issue_slots.map(s => !(s.valid)) ++ io.dis_uops.map(_.valid).map(!_.asBool) val shamts_oh = Array.fill(numIssueSlots+dispatchWidth) {Wire(UInt(width=maxShift.W))} // track how many to shift up this entry by by counting previous vacant spots def SaturatingCounterOH(count_oh:UInt, inc: Bool, max: Int): UInt = { val next = Wire(UInt(width=max.W)) next := count_oh when (count_oh === 0.U && inc) { next := 1.U } .elsewhen (!count_oh(max-1) && inc) { next := (count_oh << 1.U) } next } shamts_oh(0) := 0.U for (i <- 1 until numIssueSlots + dispatchWidth) { shamts_oh(i) := SaturatingCounterOH(shamts_oh(i-1), vacants(i-1), maxShift) }
// which entries' uops will still be next cycle? (not being issued and vacated) val will_be_valid = (0 until numIssueSlots).map(i => issue_slots(i).will_be_valid) ++ (0 until dispatchWidth).map(i => io.dis_uops(i).valid && !dis_uops(i).exception && !dis_uops(i).is_fence && !dis_uops(i).is_fencei)
val uops = issue_slots.map(s=>s.out_uop) ++ dis_uops.map(s=>s) for (i <- 0 until numIssueSlots) { issue_slots(i).in_uop.valid := false.B issue_slots(i).in_uop.bits := uops(i+1) for (j <- 1 to maxShift by 1) { when (shamts_oh(i+j) === (1 << (j-1)).U) { issue_slots(i).in_uop.valid := will_be_valid(i+j) issue_slots(i).in_uop.bits := uops(i+j) } } issue_slots(i).clear := shamts_oh(i) =/= 0.U }
//------------------------------------------------------------- // Dispatch/Entry Logic // did we find a spot to slide the new dispatched uops into?
val will_be_available = (0 until numIssueSlots).map(i => (!issue_slots(i).will_be_valid || issue_slots(i).clear) && !(issue_slots(i).in_uop.valid)) val num_available = PopCount(will_be_available) for (w <- 0 until dispatchWidth) { io.dis_uops(w).ready := RegNext(num_available > w.U) }
// set default for (w <- 0 until issueWidth) { io.iss_valids(w) := false.B io.iss_uops(w) := NullMicroOp // unsure if this is overkill io.iss_uops(w).prs1 := 0.U io.iss_uops(w).prs2 := 0.U io.iss_uops(w).prs3 := 0.U io.iss_uops(w).lrs1_rtype := RT_X io.iss_uops(w).lrs2_rtype := RT_X }
val requests = issue_slots.map(s => s.request) val port_issued = Array.fill(issueWidth){Bool()} for (w <- 0 until issueWidth) { port_issued(w) = false.B }
for (i <- 0 until numIssueSlots) { issue_slots(i).grant := false.B var uop_issued = false.B
for (w <- 0 until issueWidth) { val can_allocate = (issue_slots(i).uop.fu_code & io.fu_types(w)) =/= 0.U
if (bypassableArray.reduce(_||_)) { val bypassable_wports = ArrayBuffer[Valid[RegisterFileWritePort]]() io.write_ports zip bypassableArray map { case (wport, b) => if (b) { bypassable_wports += wport} }
for (i <- 0 until numReadPorts) { val bypass_ens = bypassable_wports.map(x => x.valid && x.bits.addr === read_addrs(i)) //使用Mux1H得出最新的指令的bypass的结果 val bypass_data = Mux1H(VecInit(bypass_ens.toSeq), VecInit(bypassable_wports.map(_.bits.data).toSeq))
io.read_ports(i).data := Mux(bypass_ens.reduce(_|_), bypass_data, read_data(i)) } } else { for (i <- 0 until numReadPorts) { io.read_ports(i).data := read_data(i) } }
写逻辑
代码如下.
1 2 3 4 5
for (wport <- io.write_ports) { when (wport.valid) { regfile(wport.bits.addr) := wport.bits.data } }
if (enableSFBOpt) rrd_pred_data(w) := Mux(RegNext(io.iss_uops(w).is_sfb_shadow), io.prf_read_ports(w).data, false.B)
val rrd_kill = io.kill || IsKilledByBranch(io.brupdate, rrd_uops(w))
exe_reg_valids(w) := Mux(rrd_kill, false.B, rrd_valids(w)) // TODO use only the valids signal, don't require us to set nullUop exe_reg_uops(w) := Mux(rrd_kill, NullMicroOp, rrd_uops(w))
for (w <- 0 until issueWidth) { val numReadPorts = numReadPortsArray(w) var rs1_cases = Array((false.B, 0.U(registerWidth.W))) var rs2_cases = Array((false.B, 0.U(registerWidth.W))) var pred_cases = Array((false.B, 0.U(1.W)))
val prs1 = rrd_uops(w).prs1 val lrs1_rtype = rrd_uops(w).lrs1_rtype val prs2 = rrd_uops(w).prs2 val lrs2_rtype = rrd_uops(w).lrs2_rtype val ppred = rrd_uops(w).ppred
for (b <- 0 until numTotalBypassPorts) { val bypass = io.bypass(b) // can't use "io.bypass.valid(b) since it would create a combinational loop on branch kills" rs1_cases ++= Array((bypass.valid && (prs1 === bypass.bits.uop.pdst) && bypass.bits.uop.rf_wen && bypass.bits.uop.dst_rtype === RT_FIX && lrs1_rtype === RT_FIX && (prs1 =/= 0.U), bypass.bits.data)) rs2_cases ++= Array((bypass.valid && (prs2 === bypass.bits.uop.pdst) && bypass.bits.uop.rf_wen && bypass.bits.uop.dst_rtype === RT_FIX && lrs2_rtype === RT_FIX && (prs2 =/= 0.U), bypass.bits.data)) }
for (b <- 0 until numTotalPredBypassPorts) { val bypass = io.pred_bypass(b) pred_cases ++= Array((bypass.valid && (ppred === bypass.bits.uop.pdst) && bypass.bits.uop.is_sfb_br, bypass.bits.data)) }
if (numReadPorts > 0) bypassed_rs1_data(w) := MuxCase(rrd_rs1_data(w), rs1_cases) if (numReadPorts > 1) bypassed_rs2_data(w) := MuxCase(rrd_rs2_data(w), rs2_cases) if (enableSFBOpt) bypassed_pred_data(w) := MuxCase(rrd_pred_data(w), pred_cases) }
送往执行阶段信号
代码如下,主要送了valid,数据和uops,注意这里是有pipe reg的
1 2 3 4 5 6 7 8 9 10 11
// set outputs to execute pipelines for (w <- 0 until issueWidth) { val numReadPorts = numReadPortsArray(w)
io.exe_reqs(w).valid := exe_reg_valids(w) io.exe_reqs(w).bits.uop := exe_reg_uops(w) if (numReadPorts > 0) io.exe_reqs(w).bits.rs1_data := exe_reg_rs1_data(w) if (numReadPorts > 1) io.exe_reqs(w).bits.rs2_data := exe_reg_rs2_data(w) if (numReadPorts > 2) io.exe_reqs(w).bits.rs3_data := exe_reg_rs3_data(w) if (enableSFBOpt) io.exe_reqs(w).bits.pred_data := exe_reg_pred_data(w) }
// Can we fire an incoming sfence val can_fire_sfence = widthMap(w => exe_req(w).valid && exe_req(w).bits.sfence.valid)
// Can we fire a request from dcache to release a line // This needs to go through LDQ search to mark loads as dangerous val can_fire_release = widthMap(w => (w == memWidth-1).B && io.dmem.release.valid) io.dmem.release.ready := will_fire_release.reduce(_||_)
// Can we retry a load that missed in the TLB val can_fire_load_retry = widthMap(w => ( ldq_retry_e.valid && ldq_retry_e.bits.addr.valid && ldq_retry_e.bits.addr_is_virtual && !p1_block_load_mask(ldq_retry_idx) && !p2_block_load_mask(ldq_retry_idx) && RegNext(dtlb.io.miss_rdy) && !store_needs_order && (w == memWidth-1).B && // TODO: Is this best scheduling? !ldq_retry_e.bits.order_fail))
// Can we retry a store addrgen that missed in the TLB // - Weird edge case when sta_retry and std_incoming for same entry in same cycle. Delay this val can_fire_sta_retry = widthMap(w => ( stq_retry_e.valid && stq_retry_e.bits.addr.valid && stq_retry_e.bits.addr_is_virtual && (w == memWidth-1).B && RegNext(dtlb.io.miss_rdy) && !(widthMap(i => (i != w).B && can_fire_std_incoming(i) && stq_incoming_idx(i) === stq_retry_idx).reduce(_||_)) )) // Can we commit a store val can_fire_store_commit = widthMap(w => ( stq_commit_e.valid && !stq_commit_e.bits.uop.is_fence && !mem_xcpt_valid && !stq_commit_e.bits.uop.exception && (w == 0).B && (stq_commit_e.bits.committed || ( stq_commit_e.bits.uop.is_amo && stq_commit_e.bits.addr.valid && !stq_commit_e.bits.addr_is_virtual && stq_commit_e.bits.data.valid))))
// Can we wakeup a load that was nack'd val block_load_wakeup = WireInit(false.B) val can_fire_load_wakeup = widthMap(w => ( ldq_wakeup_e.valid && ldq_wakeup_e.bits.addr.valid && !ldq_wakeup_e.bits.succeeded && !ldq_wakeup_e.bits.addr_is_virtual && !ldq_wakeup_e.bits.executed && !ldq_wakeup_e.bits.order_fail && !p1_block_load_mask(ldq_wakeup_idx) && !p2_block_load_mask(ldq_wakeup_idx) && !store_needs_order && !block_load_wakeup && (w == memWidth-1).B && (!ldq_wakeup_e.bits.addr_is_uncacheable || (io.core.commit_load_at_rob_head && ldq_head === ldq_wakeup_idx && ldq_wakeup_e.bits.st_dep_mask.asUInt === 0.U))))
elsewhen (do_ld_search(w) && l_valid && l_bits.addr.valid && !l_bits.addr_is_virtual && dword_addr_matches(w) && mask_overlap(w)) { val searcher_is_older = IsOlder(lcam_ldq_idx(w), i.U, ldq_head) when (searcher_is_older) { when ((l_bits.executed || l_bits.succeeded || l_is_forwarding) && !s1_executing_loads(i) && // If the load is proceeding in parallel we don't need to kill it l_bits.observed) { // Its only a ordering failure if the cache line was observed between the younger load and us ldq(i).bits.order_fail := true.B failed_loads(i) := true.B } } .elsewhen (lcam_ldq_idx(w) =/= i.U) { // The load is older, and either it hasn't executed, it was nacked, or it is ignoring its response // we need to kill ourselves, and prevent forwarding val older_nacked = nacking_loads(i) || RegNext(nacking_loads(i)) when (!(l_bits.executed || l_bits.succeeded) || older_nacked) { s1_set_execute(lcam_ldq_idx(w)) := false.B io.dmem.s1_kill(w) := RegNext(dmem_req_fire(w)) can_forward(w) := false.B } } }
val forwarding_age_logic = Seq.fill(memWidth) { Module(new ForwardingAgeLogic(numStqEntries)) } for (w <- 0 until memWidth) { forwarding_age_logic(w).io.addr_matches := ldst_addr_matches(w).asUInt forwarding_age_logic(w).io.youngest_st_idx := lcam_uop(w).stq_idx } val forwarding_idx = widthMap(w => forwarding_age_logic(w).io.forwarding_idx)
// Forward if st-ld forwarding is possible from the writemask and loadmask mem_forward_valid := widthMap(w => (ldst_forward_matches(w)(forwarding_idx(w)) && !IsKilledByBranch(io.core.brupdate, lcam_uop(w)) && !io.core.exception && !RegNext(io.core.exception))) mem_forward_stq_idx := forwarding_idx
The supervisor memory-management fence instruction SFENCE.VMA is used to synchronize updates to in-memory memory-management data structures with current execution.SFENCE.VMA is also used to invalidate entries in the address-translation cache associated with a hart
当rs 2!= x 0时,rs 2中保存的值的位SXLEN-1:ASIDMAX被保留以供将来的标准使用。在标准扩展定义了它们的使用之前,它们应该被软件归零并被当前的实现忽略。此外,如果ASIDLEN < ASIDMAX,则实现应忽略rs 2中保存的值的位ASIDMAX-1:ASIDLEN。
For example, simpler implementations can ignore the virtual address in rs1 and the ASID value in rs2 and always perform a global fence. The choice not to raise an exception when an invalid virtual address is held in rs1 facilitates this type of simplification
val meta = Seq.fill(memWidth) { Module(new L1MetadataArray(onReset _)) } val metaWriteArb = Module(new Arbiter(new L1MetaWriteReq, 2)) // 0 goes to MSHR refills, 1 goes to prober val metaReadArb = Module(new Arbiter(new BoomL1MetaReadReq, 6)) // 0 goes to MSHR replays, 1 goes to prober, 2 goes to wb, 3 goes to MSHR meta read, // 4 goes to pipeline, 5 goes to prefetcher
metaReadArb.io.in := DontCare for (w <- 0 until memWidth) { meta(w).io.write.valid := metaWriteArb.io.out.fire meta(w).io.write.bits := metaWriteArb.io.out.bits meta(w).io.read.valid := metaReadArb.io.out.valid meta(w).io.read.bits := metaReadArb.io.out.bits.req(w) } metaReadArb.io.out.ready := meta.map(_.io.read.ready).reduce(_||_) metaWriteArb.io.out.ready := meta.map(_.io.write.ready).reduce(_||_)
val data = Module(if (boomParams.numDCacheBanks == 1) new BoomDuplicatedDataArray else new BoomBankedDataArray) val dataWriteArb = Module(new Arbiter(new L1DataWriteReq, 2)) // 0 goes to pipeline, 1 goes to MSHR refills val dataReadArb = Module(new Arbiter(new BoomL1DataReadReq, 3)) // 0 goes to MSHR replays, 1 goes to wb, 2 goes to pipeline dataReadArb.io.in := DontCare
for (w <- 0 until memWidth) { data.io.read(w).valid := dataReadArb.io.out.bits.valid(w) && dataReadArb.io.out.valid data.io.read(w).bits := dataReadArb.io.out.bits.req(w) } dataReadArb.io.out.ready := true.B
val io = new Bundle { val req = Flipped(Decoupled(new TLBundleB(edge.bundle))) val rep = Decoupled(new TLBundleC(edge.bundle)) val meta_read = Decoupled(new L1MetaReadReq) val meta_write = Decoupled(new L1MetaWriteReq) val wb_req = Decoupled(new WritebackReq(edge.bundle)) val way_en = Input(UInt(nWays.W)) val wb_rdy = Input(Bool()) // Is writeback unit currently busy? If so need to retry meta read when its done val mshr_rdy = Input(Bool()) // Is MSHR ready for this request to proceed? val mshr_wb_rdy = Output(Bool()) // Should we block MSHR writebacks while we finish our own? val block_state = Input(new ClientMetadata()) val lsu_release = Decoupled(new TLBundleC(edge.bundle))
val state = Output(Valid(UInt(coreMaxAddrBits.W))) }
// state === s_invalid when (state === s_invalid) { when (io.req.fire) {//TL B 握手成功 state := s_meta_read req := io.req.bits//从代理送入的请求信号 } } .elsewhen (state === s_meta_read) { when (io.meta_read.fire) { state := s_meta_resp } } .elsewhen (state === s_meta_resp) { // we need to wait one cycle for the metadata to be read from the array state := s_mshr_req } .elsewhen (state === s_mshr_req) { old_coh := io.block_state//s2阶段读出的meta way_en := io.way_en//s2阶段得到的命中信息 // if the read didn't go through, we need to retry state := Mux(io.mshr_rdy && io.wb_rdy, s_mshr_resp, s_meta_read)//等待wb和mshr准备好 } .elsewhen (state === s_mshr_resp) { state := Mux(tag_matches && is_dirty, s_writeback_req, s_lsu_release)//若此时命中且dirty,进入s_writeback_req,如果其他命中但不脏 } .elsewhen (state === s_lsu_release) { when (io.lsu_release.fire) { state := s_release } } .elsewhen (state === s_release) { when (io.rep.ready) { state := Mux(tag_matches, s_meta_write, s_invalid)//更新权限 } } .elsewhen (state === s_writeback_req) { when (io.wb_req.fire) { state := s_writeback_resp//脏的数据写回成功,转换为s_writeback_resp } } .elsewhen (state === s_writeback_resp) { // wait for the writeback request to finish before updating the metadata when (io.wb_req.ready) { state := s_meta_write } } .elsewhen (state === s_meta_write) { when (io.meta_write.fire) {//此时写入新的权限 state := s_meta_write_resp } } .elsewhen (state === s_meta_write_resp) { state := s_invalid }
BoomWritebackUnit模块
该模块是去写回脏数据(主动release或者probe请求)
信号定义
1 2 3 4 5 6 7 8 9
val req = Flipped(Decoupled(new WritebackReq(edge.bundle))) val meta_read = Decoupled(new L1MetaReadReq) val resp = Output(Bool()) val idx = Output(Valid(UInt())) val data_req = Decoupled(new L1DataReadReq) val data_resp = Input(UInt(encRowBits.W)) val mem_grant = Input(Bool()) val release = Decoupled(new TLBundleC(edge.bundle)) val lsu_release = Decoupled(new TLBundleC(edge.bundle))
val s1_addr = s1_req.map(_.addr) val s1_nack = s1_addr.map(a => a(idxMSB,idxLSB) === prober.io.meta_write.bits.idx && !prober.io.req.ready) val s1_send_resp_or_nack = RegNext(s0_send_resp_or_nack) val s1_type = RegNext(s0_type)
val s1_mshr_meta_read_way_en = RegNext(mshrs.io.meta_read.bits.way_en) val s1_replay_way_en = RegNext(mshrs.io.replay.bits.way_en) // For replays, the metadata isn't written yet val s1_wb_way_en = RegNext(wb.io.data_req.bits.way_en)
final def apply[T](pname: Field[T]): T = { val out = find(pname) require(out.isDefined, s"Key ${pname} is not defined in Parameters") out.get } .... protected[config] def find[T](pname: Field[T]): Option[T] = chain(this, this, new TerminalView, pname)
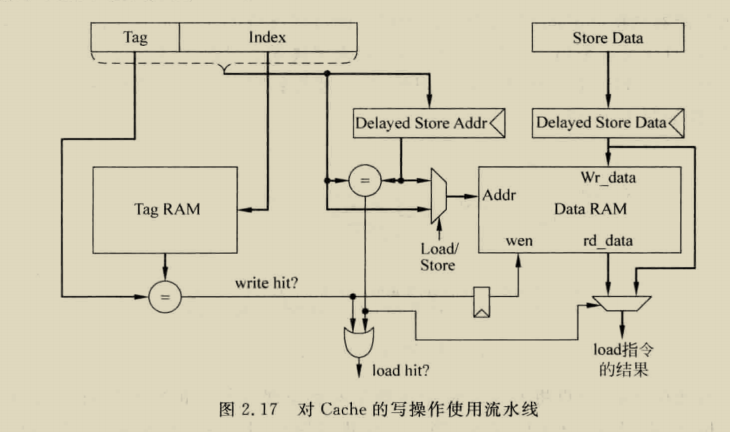
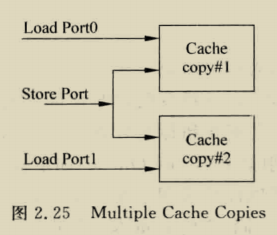
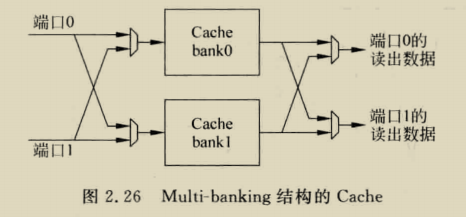
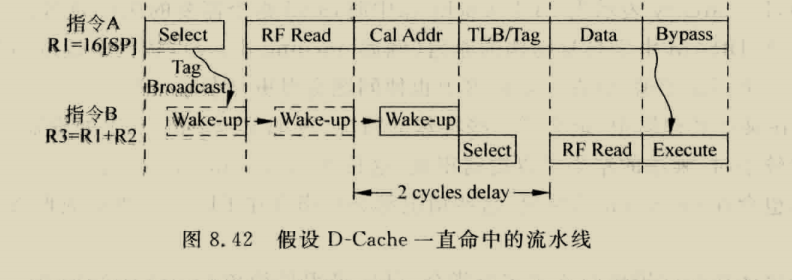
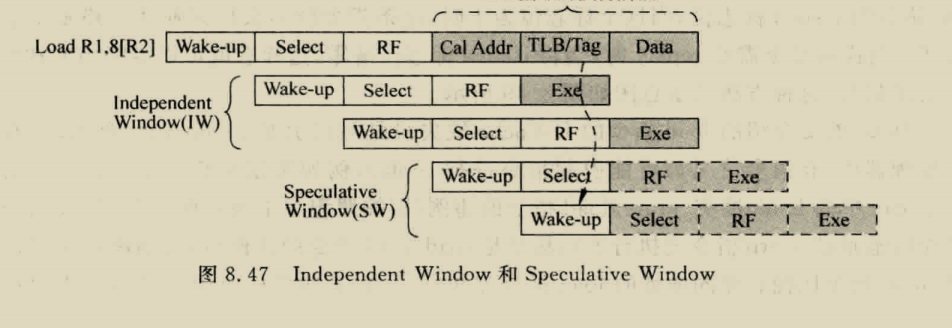
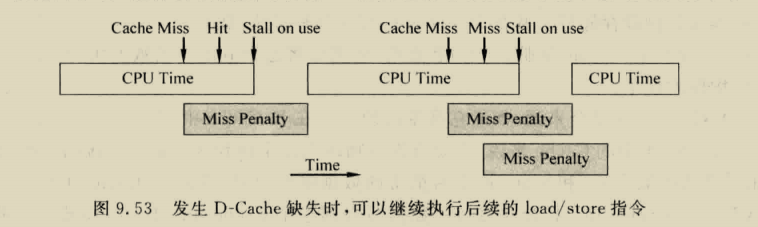
load在hit情况只需要一个周期,但store指令在hit时,第一个周期比较,第二个中秋选择是否写入数据,假如store后紧接着load,这时load的数据可能在delayed store data中,需要做一个bypass,但其实这个有一个问题,也就是假如发生load aft store,这样会导致两个指令竞争addr端口,必须对两个指令进行调度,或者使用双端口cache
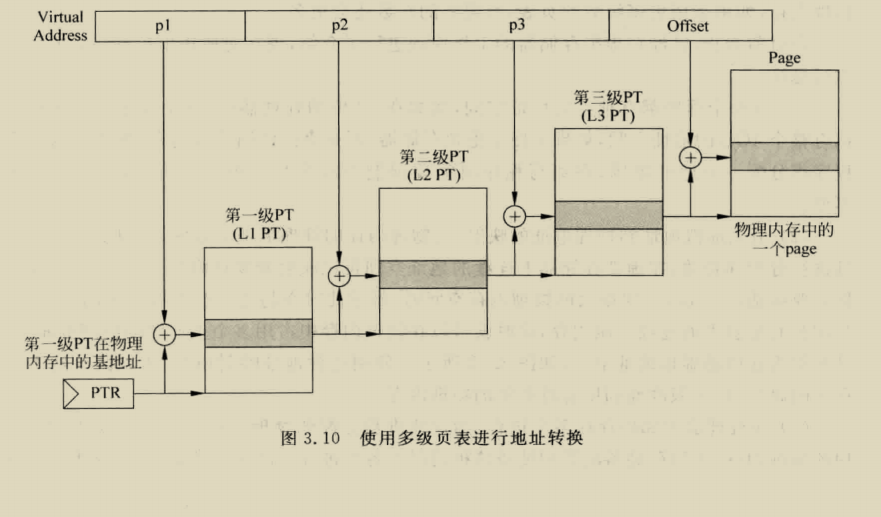
首先将a=satp.ppnxPAGESIZE,让i=LEVELS-1,SV32是PAGESIZE=4k,LEV=2,有效的模式为S和U,然后pte就是a+va.vpn[i]×PTESIZE.(PTESIZE=4 for SV32)(为什么要xPTEsize呢,vpn存储的是表项的个数,乘size才会变为地址),然后会进行PMP和PMA检查,如果PTE有效,且R=0,X=0这个是指向下一个节点的指针,i=i-1然后a=pte.ppn×PAGESIZE ,接着寻址下一个页表的PTE,如果R=1,X=1,就说明叶子PTE找到了,然后进行PMP
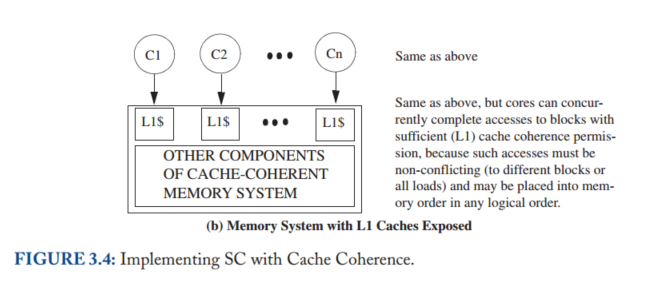
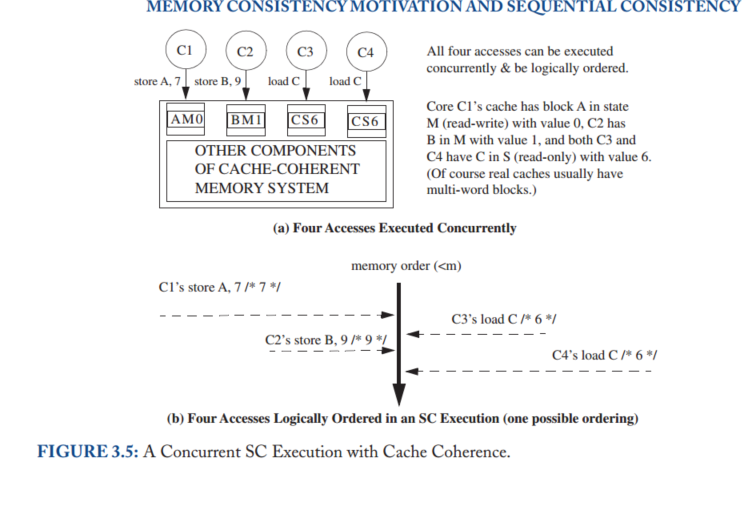
The goal of this chapter is to explain enough about coherence to understand how consistency models interact with coherent caches, but not to explore specific coherence protocols or implementations, which are topics we defer until the second portion of this primer in Chapters 6–9.
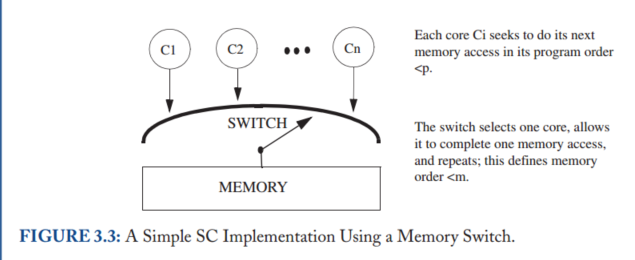
we need to define shared memory correctness—that is, which shared memory behaviors are allowed—so that programmers know what to expect and implementors know the limits to what they can provide
Transient states are required in real implementations because modern systems rarely permit atomic transitions from one stable state to another (e.g., a read miss in state Invalid will spend some time waiting for a data response before it can enter state Shared).
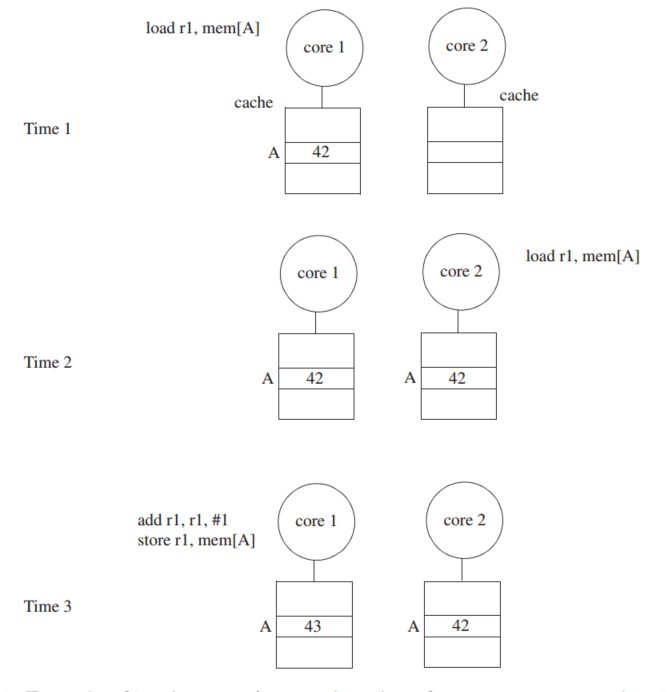
Single-Writer, Multiple-Read (SWMR) Invariant. For any memory location A, at any given (logical) time, there exists only a single core that may write to A (and can also read it) or some number of cores that may only read A.
Data-Value Invariant. The value of the memory location at the start of an epoch is the same as the value of the memory location at the end of its last read–write epoch.
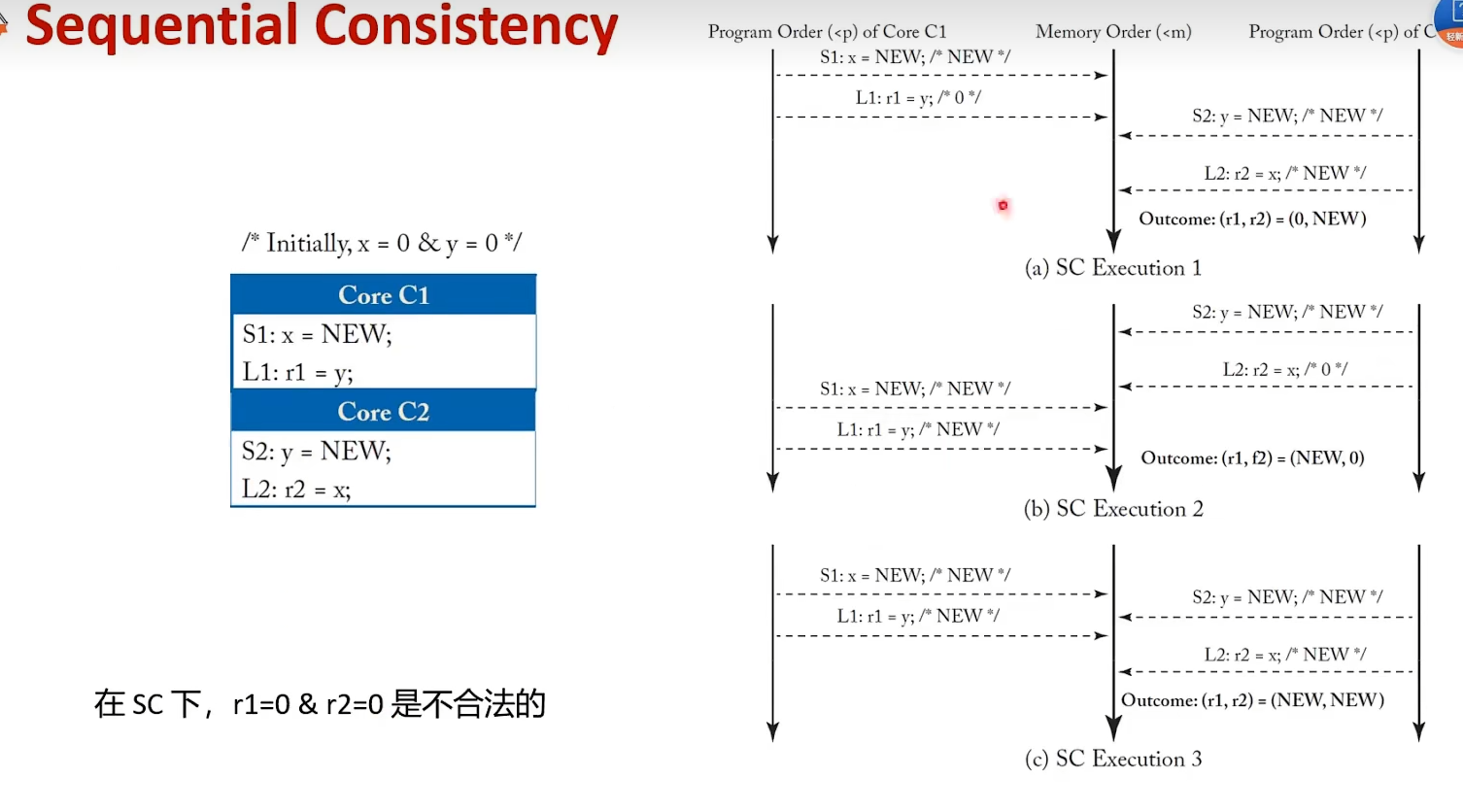
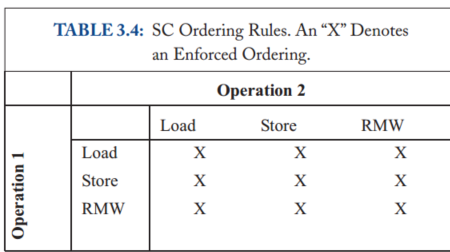
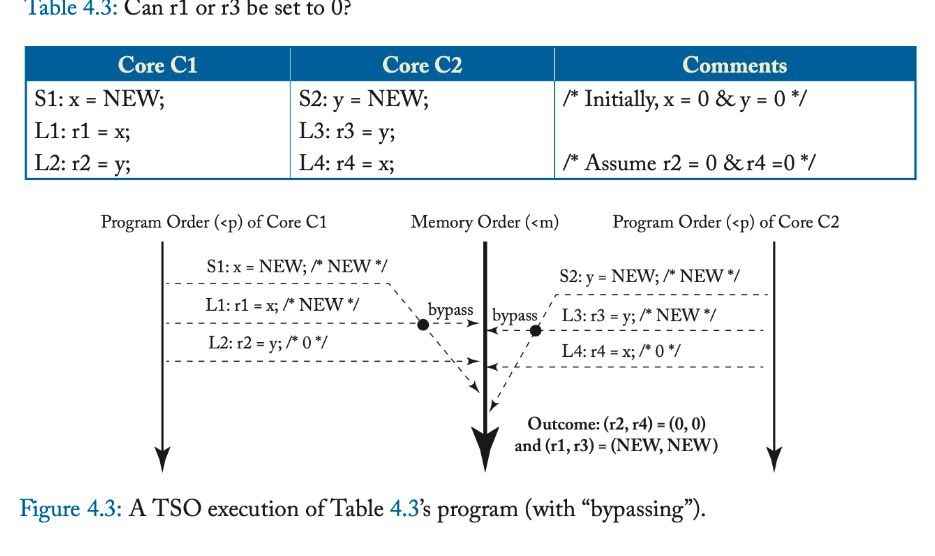
An SC execution requires:All cores insert their loads and stores into the order <m respecting their program order, regardless of whether they are to the same or different addresses (i.e., a=b or a≠b). There are four cases:
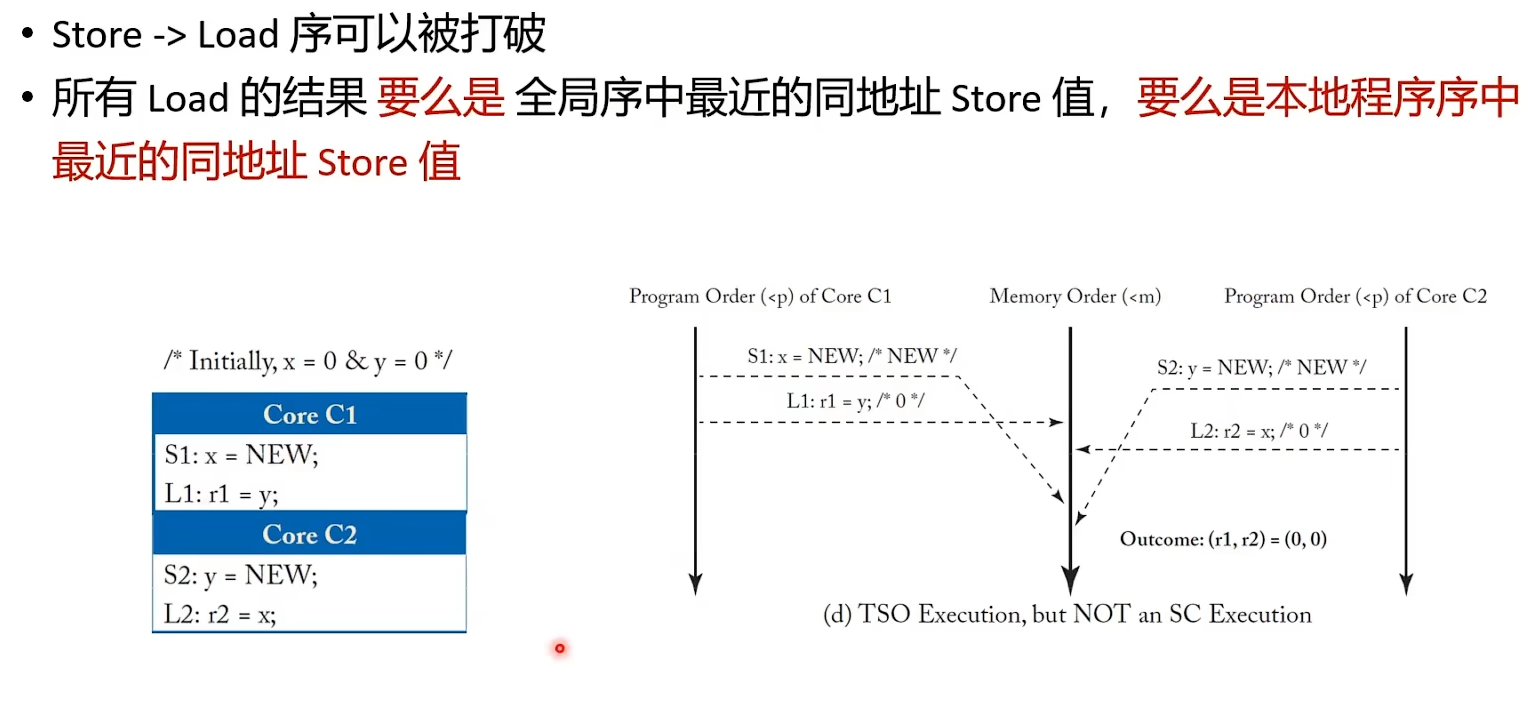
Every load gets its value from the last store before it (in global memory order) to the same address: Value of L(a) = Value of MAX <m {S(a) | S(a) <m L(a)}, where MAX <m denotes “latest in memory order.”
The decomposition of misaligned memory operations down to byte granularity facilitates emulation on implementations that do not natively support misaligned accesses. Such implementations might, for example, simply iterate over the bytes of a misaligned access one by one.
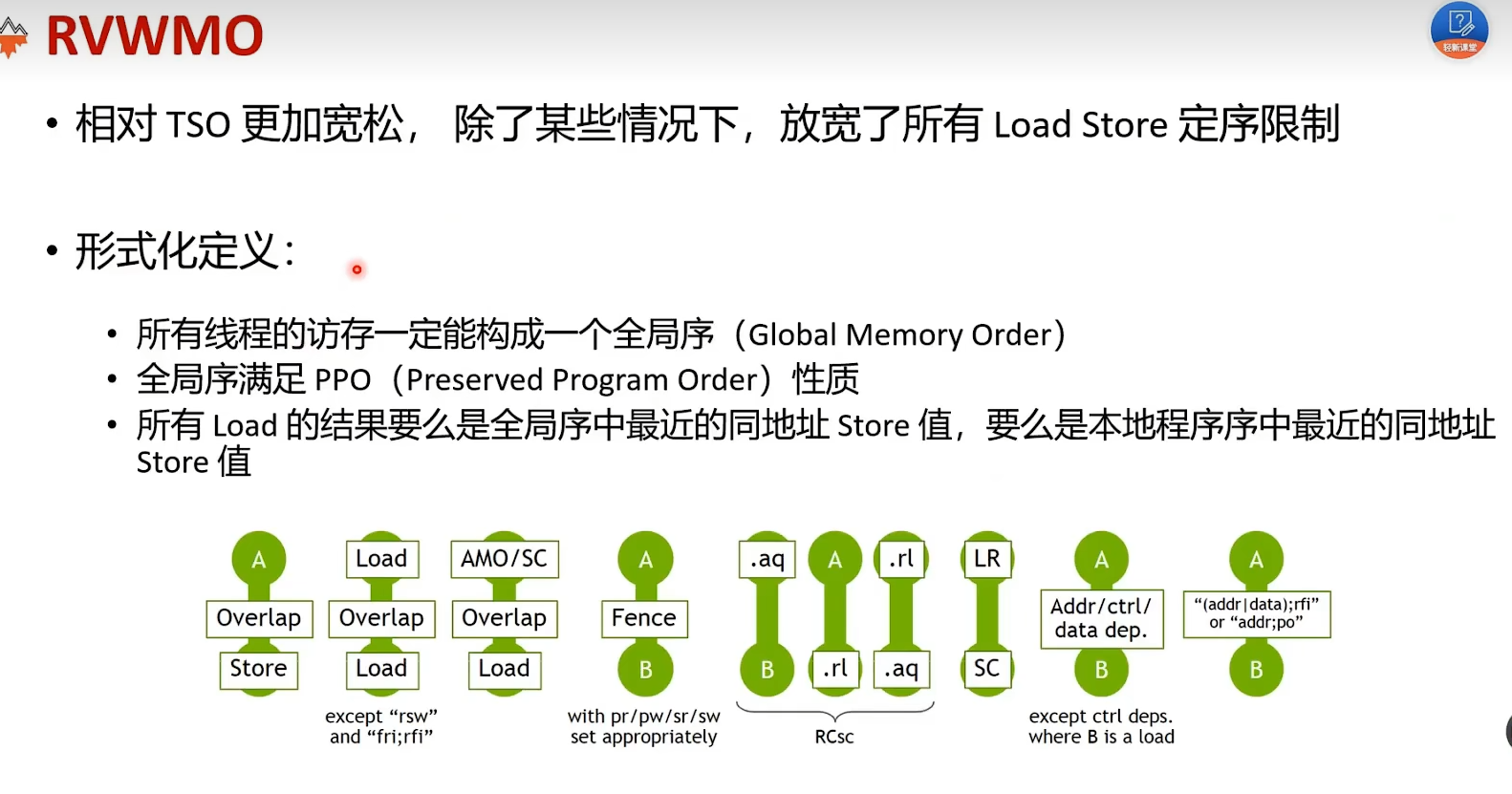
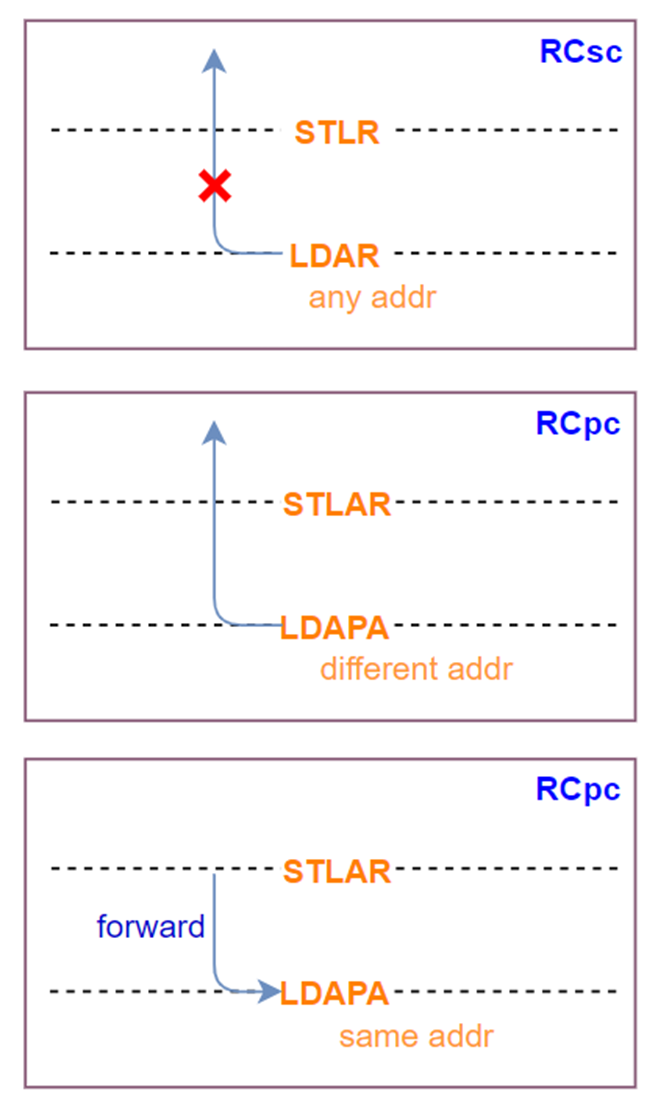
For convenience, we use the term “acquire annotation” to refer to an acquire-RCpc annotation or an acquire-RCsc annotation. Likewise, a “release annotation” refers to a release-RCpc annotation or a release-RCsc annotation. An “RCpc annotation” refers to an acquire-RCpc annotation or a releaseRCpc annotation. An RCsc annotation refers to an acquire-RCsc annotation or a release-RCsc annotation.
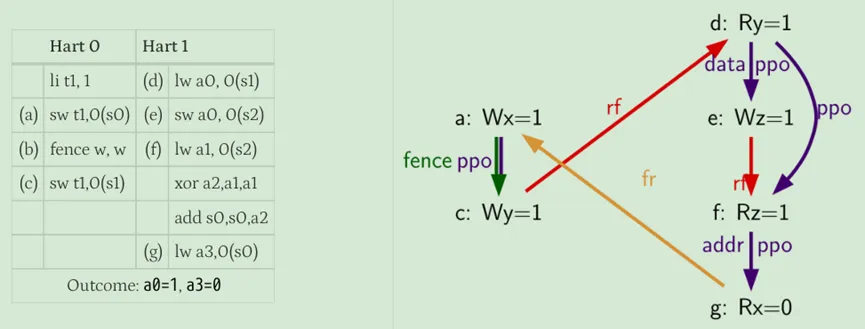
An execution of a RISC-V program obeys the RVWMO memory consistency model only if there exists a global memory order conforming to preserved program order and satisfying the load value axiom, the atomicity axiom, and the progress axiom.
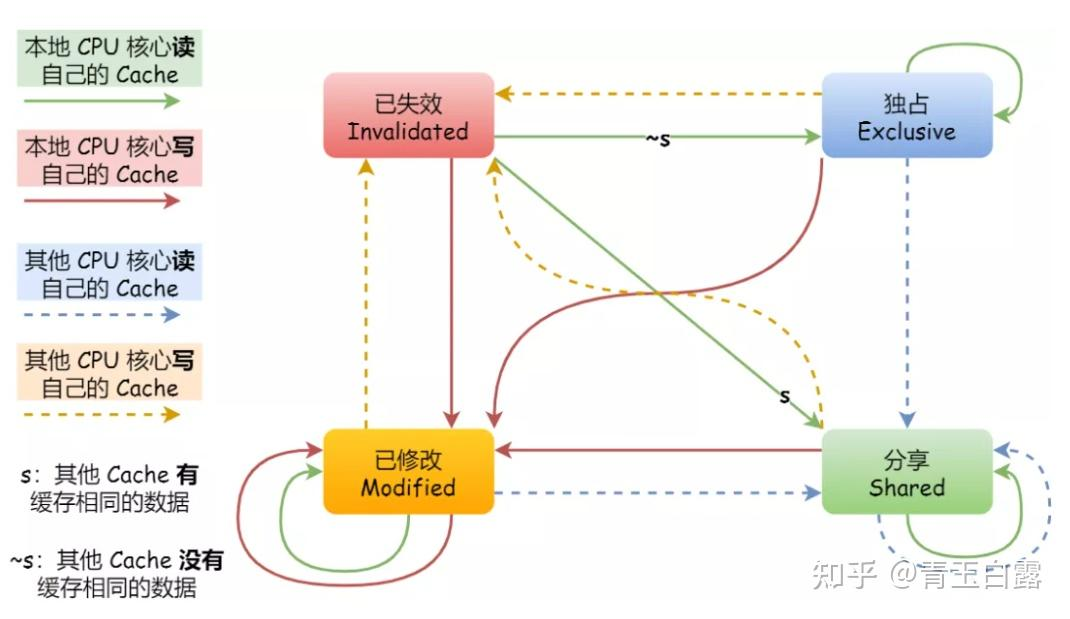
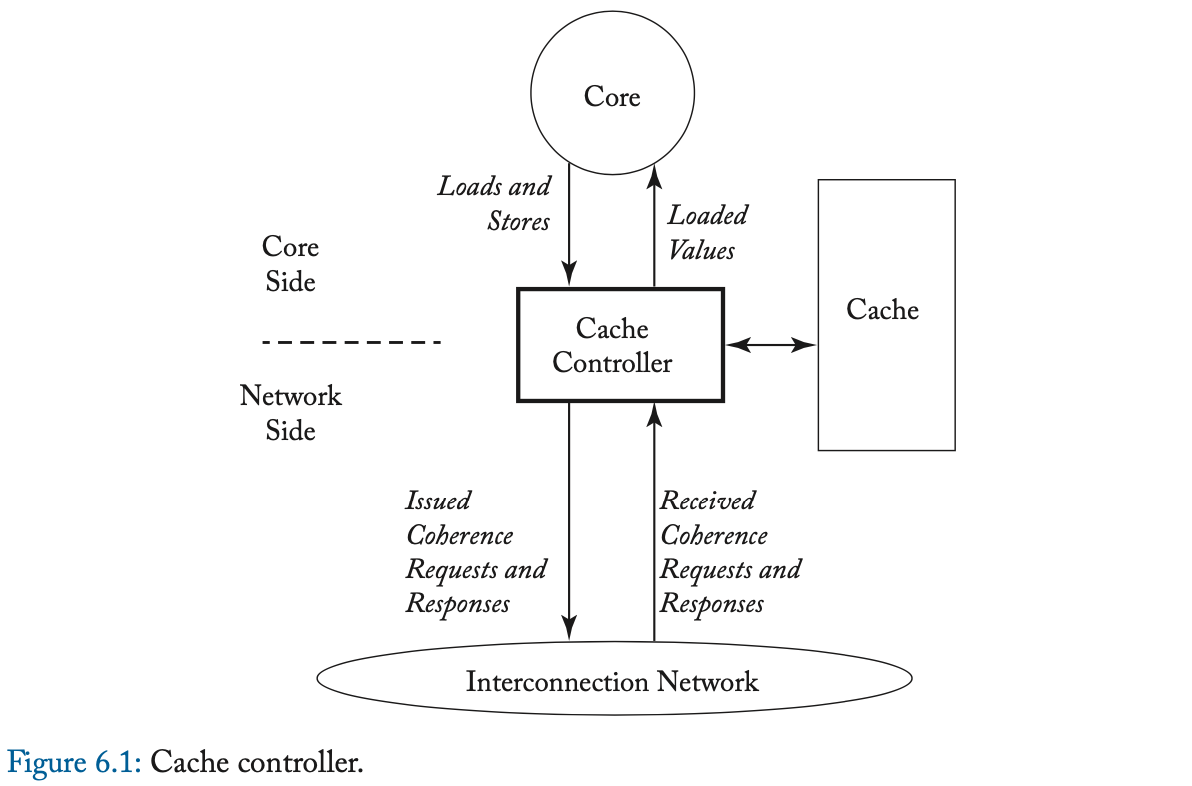
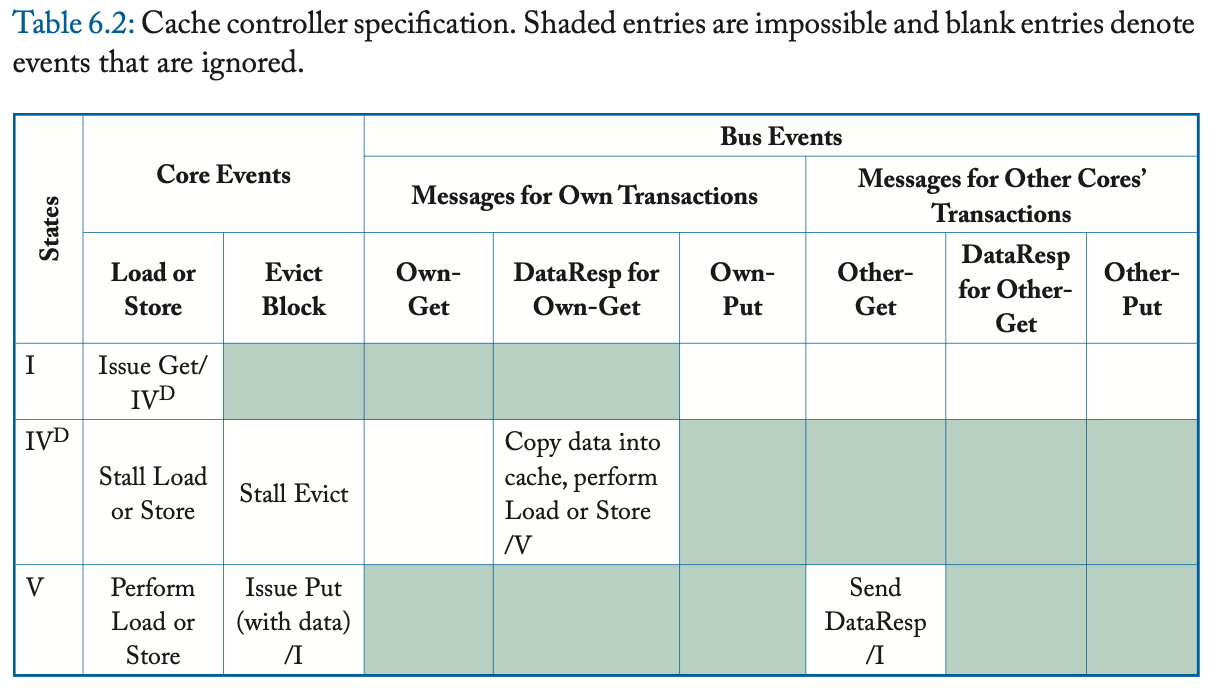
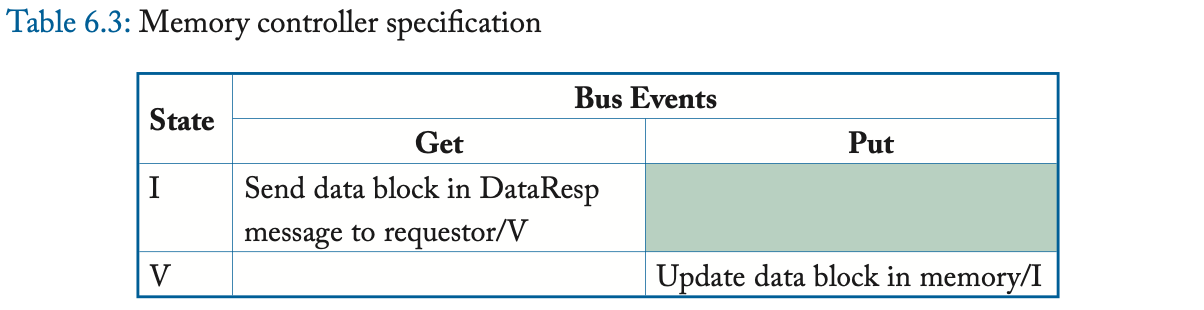
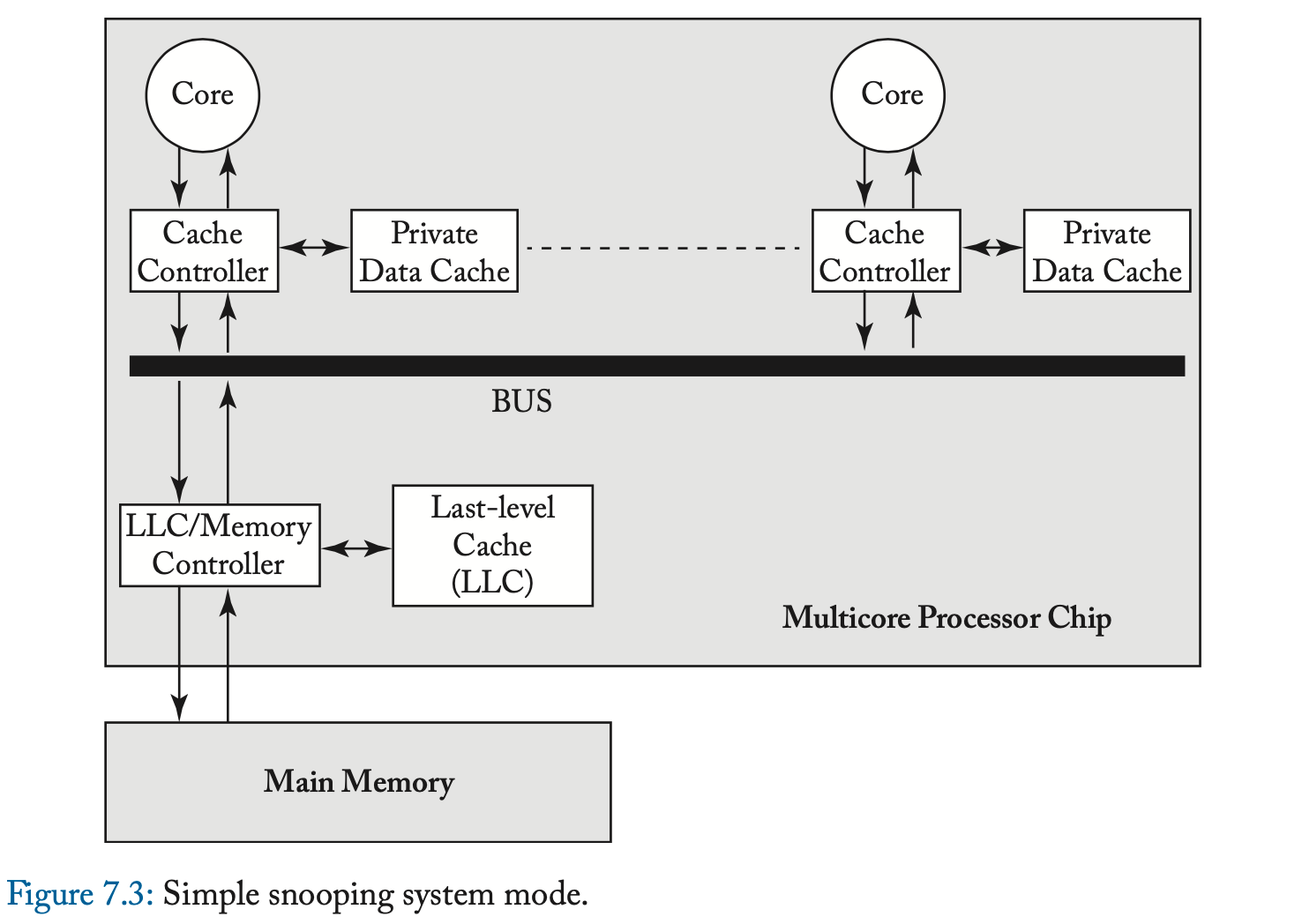
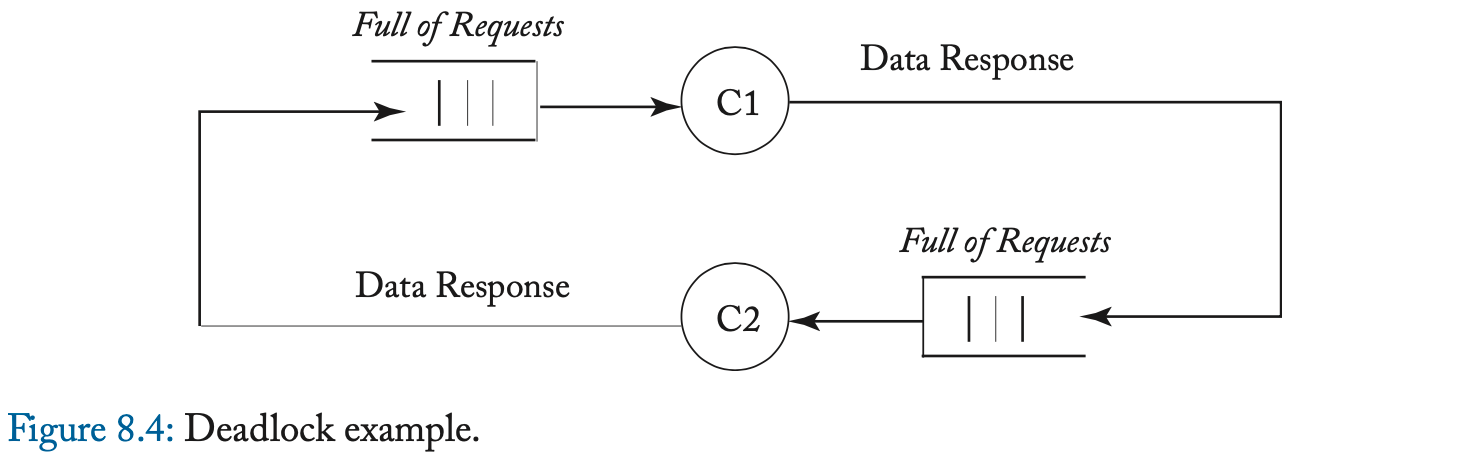
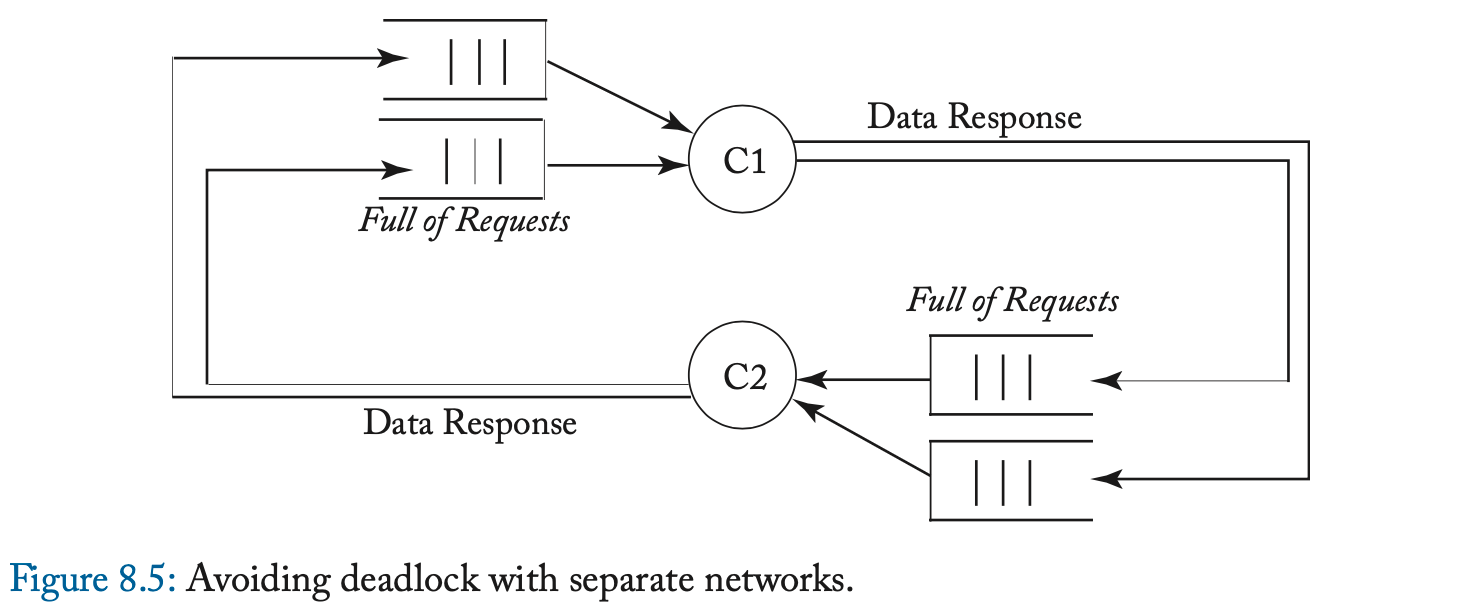
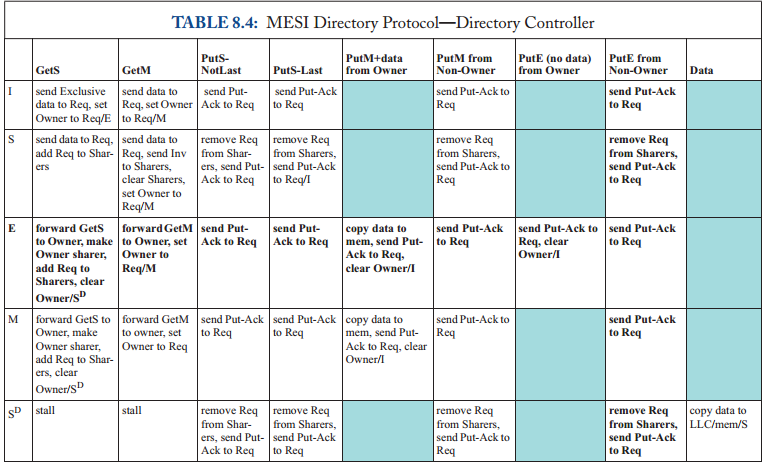
在一次 load 或 store miss 时,缓存控制器通过发送 Get 消息、并等待相应的 DataResp 消息、来启动 Get 事务。Get 事务是原子的,因为在缓存发送 Get 和该 Get 的 DataResp 出现在总线上之间,没有其他事务(Get 或 Put)可以使用总线。在 Evict Block 事件中,缓存控制器将带有整个缓存块的 Put 消息发送到内存控制器。
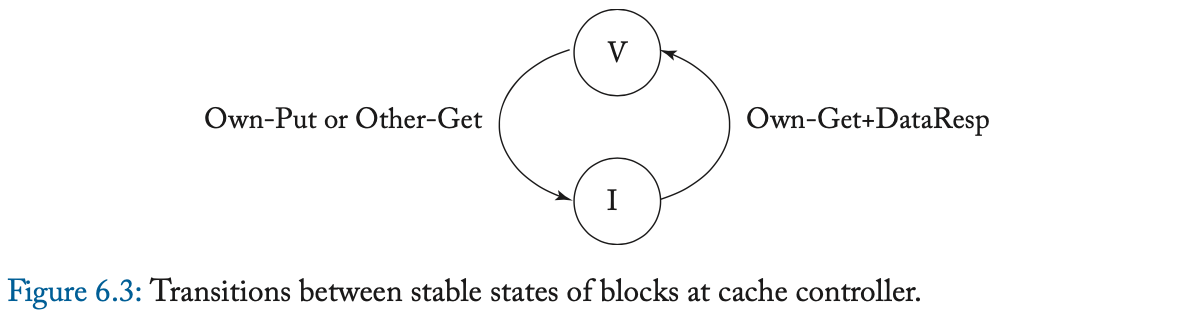
我们在图 6.3 中说明了稳定 coherence 状态之间的转换。我们使用前缀 “ Own ” 和 “ Other ” 来区分由给定缓存控制器发起的事务的消息、以及由其他缓存控制器发起的事务的消息。请注意,如果给定的缓存控制器具有处于状态 V 的块,并且另一个缓存使用 Get 消息(表示为 Other-Get )请求它,则 owning cache 必须用一个块去响应(使用 DataResp 消息,图中未显示)、并转换到状态 I。
表 6.2 和 6.3 更详细地指定了协议。表中的阴影条目表示不可能的转换。例如,缓存控制器不应该在总线上看到它自己对于一个块的 Put 请求,其中,该请求在其缓存中处于状态 V(因为它应该已经转换到了状态 I)。
瞬间状态 IV^D 对应于状态 I 中的块,该块在转换到状态 V 之前正在等待数据(通过 DataResp 消息,也就是等待数据阶段)。当稳定状态之间的转换不是原子的之时,会出现瞬间状态。在这个简单的协议中,单个消息的发送和接收是原子的,但是从内存控制器获取一个块需要发送一个 Get 消息、并接收一个 DataResp 消息,两者之间有一个中间的间隙 (gap)。IV^D 状态指示协议正在等待 DataResp。我们将在 6.4.1 节更深入地讨论瞬间状态。
到目前为止,我们只讨论了当块没有当前 coherence 活动时出现的稳定状态,并且在提到协议(例如,“具有 MESI 协议的系统”)时,仅使用这些稳定状态。然而,正如我们在 6.3 节的例子中看到的那样,在从一种稳定状态到另一种稳定状态的转换过程中,可能存在瞬间状态。在 6.3 节中,我们有瞬间状态 IV^D(在 I 中,正在进入 V,等待 DataResp)。在更复杂的协议中,我们可能会遇到几十种瞬间状态。我们使用符号 XY^Z 对这些状态进行编码,这表示该块正在从稳定状态 X 转换到稳定状态 Y,并且在发生 Z 类型的事件之前不会完成转换。例如,在后面章节的一个协议中,我们使用 IM^D 来表示一个块先前在 I 中,一旦 D (Data) 消息到达该块,它将变为 M。
用状态位扩充每个内存块。 最通用的实现是向每个内存块添加额外的位、以保持 coherence 状态。如果内存中有 N 个可能的状态,那么每个块需要 log_2(N) 个额外的位。尽管这种设计是完全通用的并且在概念上很简单,但它有几个缺点。首先,额外的位可能会以两种方式增加成本。使用现代的面向块的 DRAM 芯片很难添加两个或三个额外位,这些芯片通常至少需要 4 位宽,而且通常更宽。此外,内存中的任何变化都会妨碍使用商用 DRAM 模块(例如 DIMM),这会显著增加成本。幸运的是,对于每个块只需要几位状态的协议,可以使用修改后的 ECC 代码来存储这些状态。通过在更大的粒度上维护 ECC(例如,512 位、而不是 64 位),可以释放足够的代码空间来 “隐藏” 少量额外的位,同时,还能使用商用 DRAM 模块 [1, 5, 7]。第二个缺点是,将状态位存储在 DRAM 中、意味着获取状态会导致完整的 DRAM 延迟,即使在最新版本的、块存储在其他缓存中的情况下、也是如此。在某些情况下,这可能会增加缓存到缓存 coherence 传输的延迟。最后,将状态存储在 DRAM 中意味着所有状态更改都需要一个 DRAM read-modify-write 周期,这可能会影响功率和 DRAM 带宽。
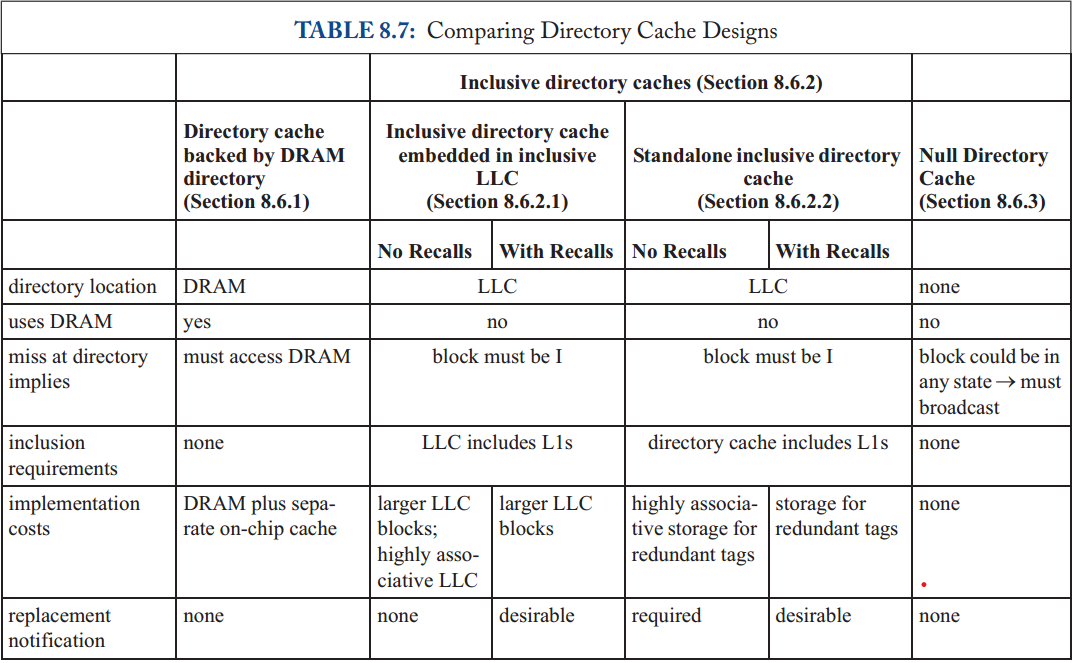
监听与目录的选择涉及权衡取舍。监听协议在逻辑上很简单,但它们无法扩展到大量核心,因为广播无法扩展。目录协议是可扩展的,因为它们是单播的,但许多事务需要更多时间,因为当 home 不是所有者时,它们需要发送额外的消息。此外,协议的选择会影响互连网络(例如,经典的监听协议需要请求消息的 total order)。
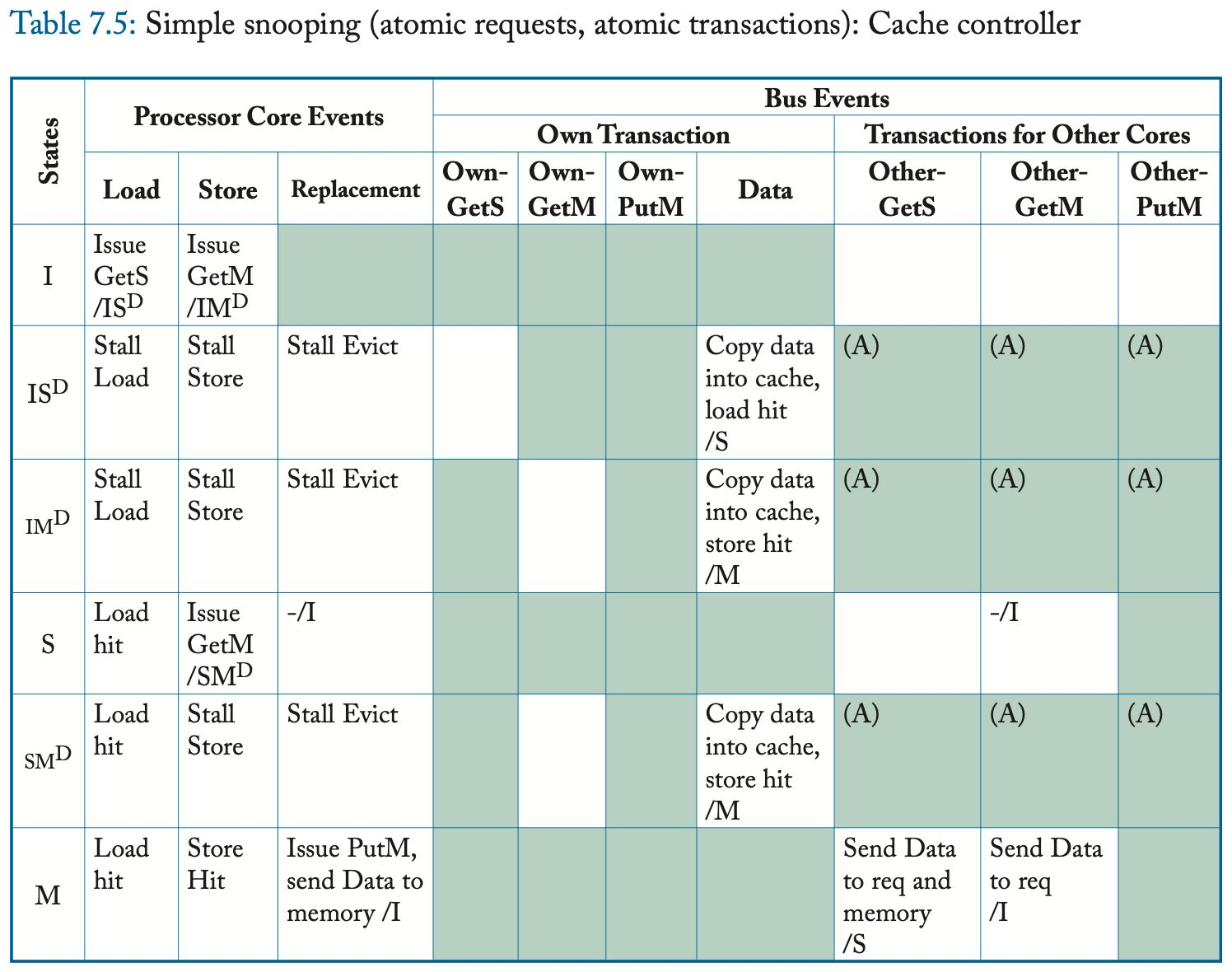
表中的阴影条目表示不可能的(或至少是错误的)转换。 例如,缓存控制器永远不应该收到它没有请求的块(即,在其缓存中处于状态 I 的块)的 Data 消息。 类似地,Atomic Transaction 约束阻止另一个核心在当前事务完成之前发出后续请求; 由于此约束,无法出现标记为“(A)”的表条目。 空白条目表示不需要任何操作的合法转换。 这些表省略了许多理解协议所不需要的实现细节。 此外,在本协议和本章的其余协议中,我们省略了另一个核心事务的 Data 对应的事件; 一个核心从不采取任何行动来响应在总线上观察另一个核心事务的 Data。
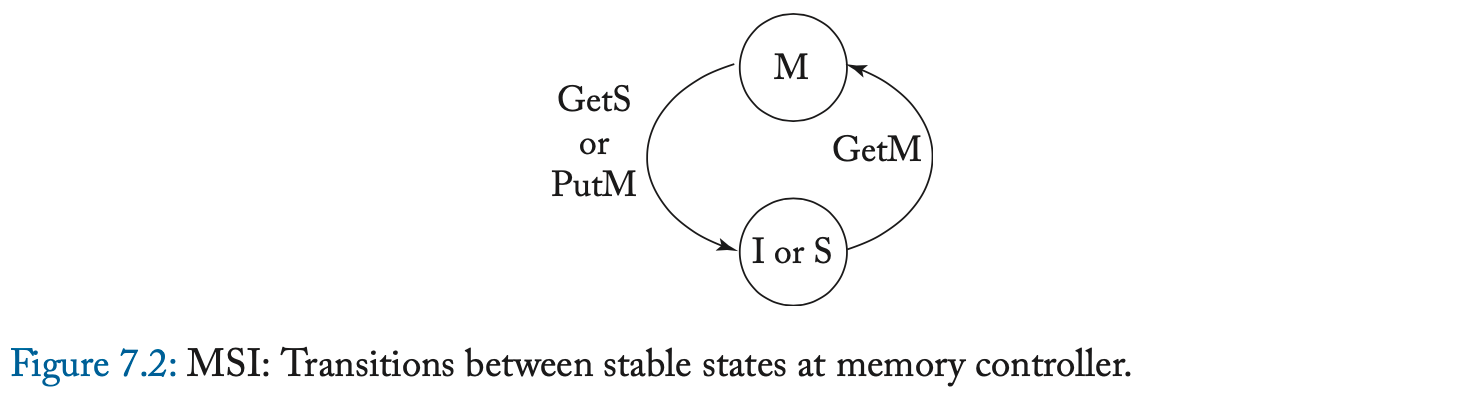
与所有 MSI 协议一样,可以在状态 S 和 M 中执行加载(即命中),而存储仅在状态 M 中命中。在加载和存储未命中时,缓存控制器分别通过发送 GetS 和 GetM 请求来启动一致性事务。 瞬间状态 IS^D、IM^D 和 SM^D 表示请求消息已发送,但尚未收到数据响应(Data)。 在这些瞬间状态下,因为请求已经被排序,所以事务已经被排序并且块在逻辑上分别处于状态 S、M 或 M。(注2) 但是,加载或存储必须等待数据到达。(注3) 一旦数据响应出现在总线上,缓存控制器就可以将数据块复制到缓存中,根据需要转换到稳定状态 S 或 M,并执行挂起的加载或存储。
数据响应可能来自内存控制器或具有处于状态 M 的块的另一个缓存。具有处于状态 S 的块的缓存可以忽略 GetS 请求,因为需要内存控制器响应,但必须使 GetM 请求上的块无效,以强制执行一致性不变量。 具有处于状态 M 的块的缓存必须响应 GetS 和 GetM 请求,发送数据响应并分别转换到状态 S 或状态 I。
LLC/内存有两种稳定状态,M 和 IorS,以及一种瞬间状态 IorS^D。 在状态 IorS 中,内存控制器是所有者并响应 GetS 和 GetM 请求,因为此状态表明没有缓存具有状态 M 的块。在状态 M 中,内存控制器不响应数据,因为缓存处于状态 M 是所有者并且拥有数据的最新副本。 但是,状态 M 中的 GetS 意味着缓存控制器将转换到状态 S,因此内存控制器还必须获取数据、更新内存并开始响应所有未来的请求。 它通过立即转换到瞬间状态 IorS^D 并等待直到它从拥有它的缓存中接收到数据来做到这一点。
当缓存控制器由于替换决定而驱逐一个块时,这会导致协议的两种可能的一致性降级:从 S 到 I 和从 M 到 I。在这个协议中,S-to-I 降级在该块被从缓存中逐出,而不与其他一致性控制器进行任何通信。通常,只有在所有其他一致性控制器的行为保持不变时,才有可能进行静默状态转换;例如,不允许无声地驱逐拥有的区块。 M-to-I 降级需要通信,因为块的 M 副本是系统中唯一有效的副本,不能简单地丢弃。因此,另一个一致性控制器(即内存控制器)必须改变其状态。为了替换处于状态 M 的块,缓存控制器在总线上发出 PutM 请求,然后将数据发送回内存控制器。在 LLC,当 PutM 请求到达时,块进入状态 IorS^D,然后在 Data 消息到达时转换到状态 IorS。(注4) Atomic Request 属性简化了缓存控制器,通过在 PutM 在总线上排序之前阻止可能降级状态的干预请求(例如,另一个核心的 GetM 请求)。类似地,Atomic Transaction 属性通过阻止对块的其他请求,直到 PutM 事务完成并且内存控制器准备好响应它们来简化内存控制器。
比较目录协议和监听协议的基本操作是有启发性的。在目录协议中,目录维护每个块的状态,缓存控制器将所有请求发送到目录。目录要么响应请求,要么将请求转发给一个或多个其他一致性控制器然后响应。一致性事务通常涉及两个步骤(单播请求,随后是单播响应)或三个步骤(单播请求,K >= 1 个转发请求和 K 个响应,其中 K 是共享者的数量)。一些协议甚至还有第四步,因为响应是通过目录间接进行的,或者因为请求者在事务完成时通知目录。相比之下,监听协议将块的状态分布在可能的所有一致性控制器上。因为没有对这种分布式状态的中央总结,所以必须将一致性请求广播到所有一致性控制器。因此,监听一致性事务总是涉及两个步骤(广播请求,随后是单播响应)。
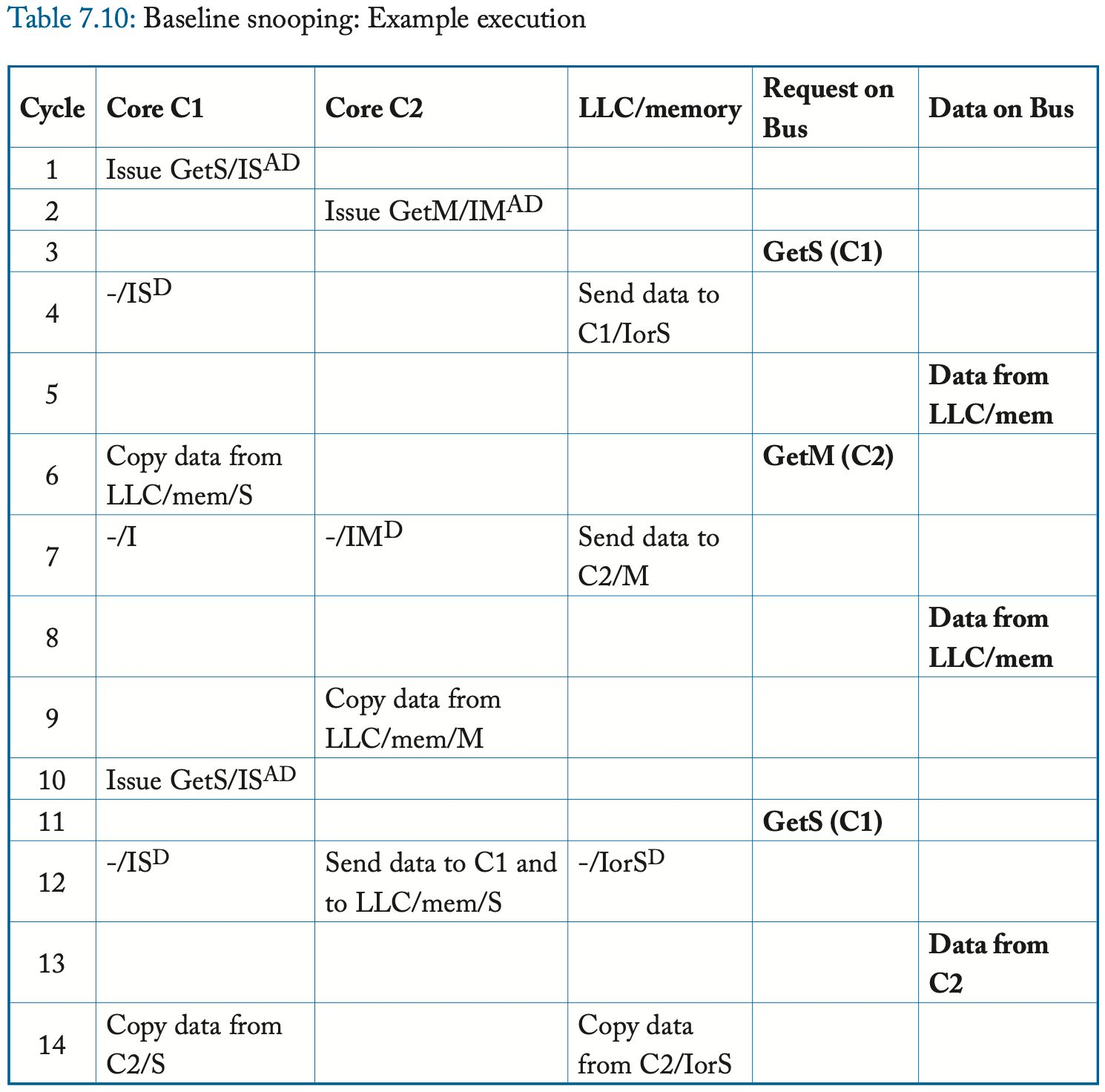
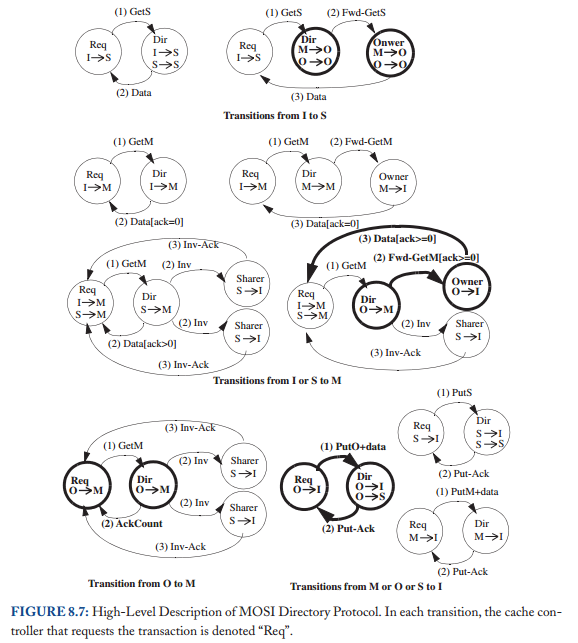
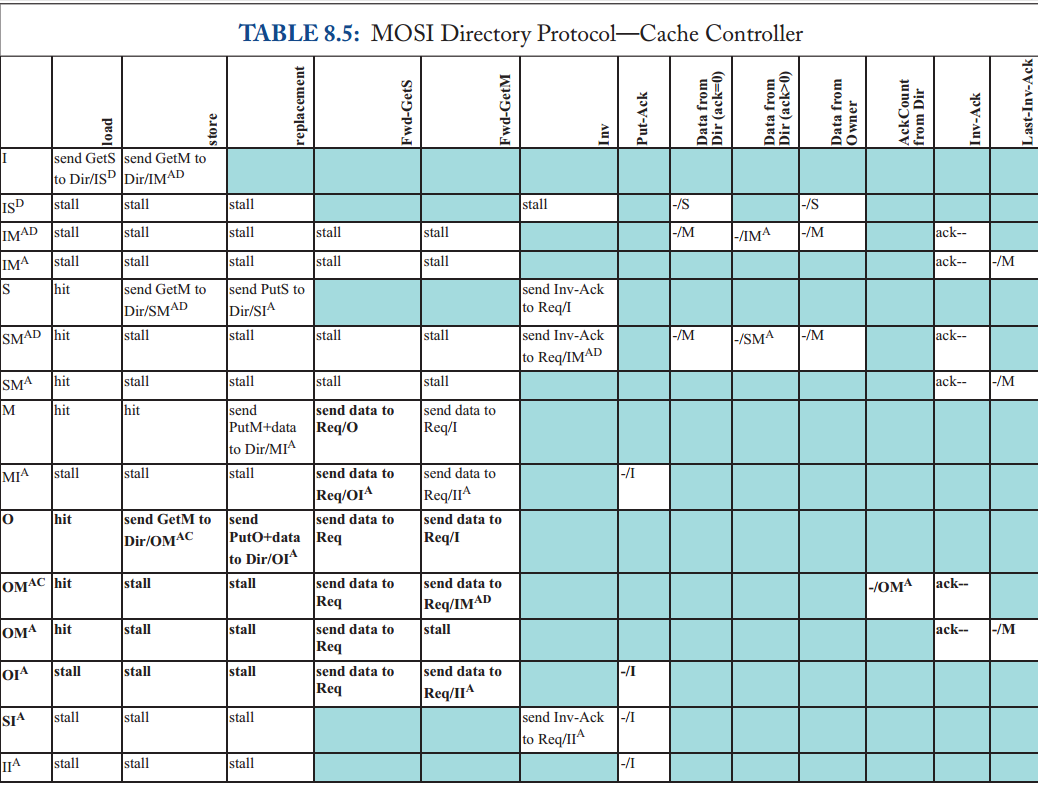
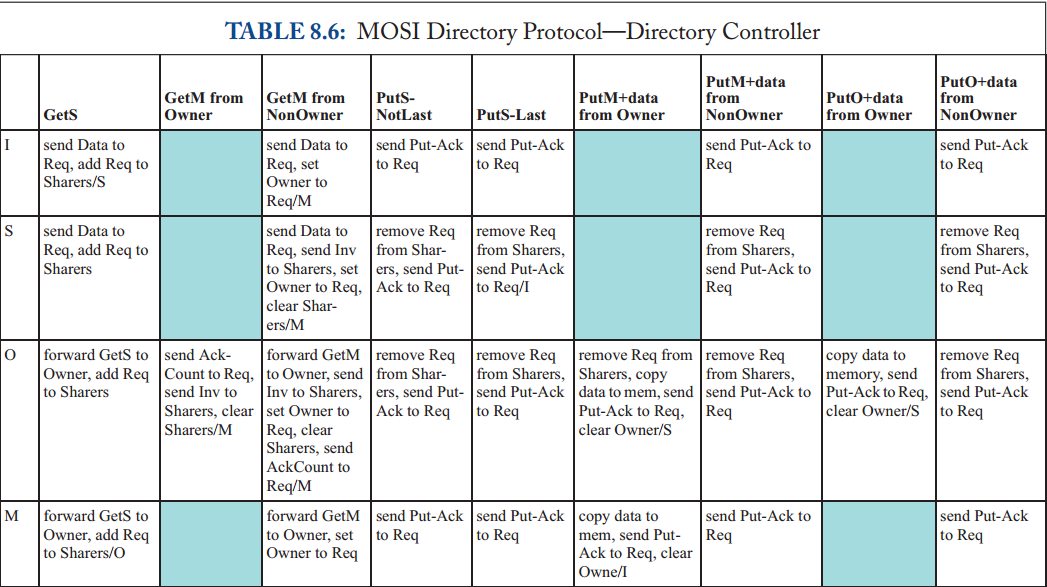
在介绍详细规范之前,我们首先说明协议的更高层次的抽象,以了解其基本行为。 在图 8.3 中,我们展示了缓存控制器发出一致性请求以将权限从 I 更改为 S、I 或 S 更改为 M、M 更改为 I 以及 S 更改为 I 的事务。与上一章中的监听协议一样,我们使用以缓存为中心的符号指定块的目录状态(例如,目录状态 M 表示存在一个缓存,该块处于状态 M)。 请注意,缓存控制器可能不会静默地驱逐共享块; 也就是说,有一个明确的 PutS 请求。 我们将讨论具有静默驱逐共享块的协议,以及静默与显式 PutS 请求的比较,直到第 8.7.4 节。
大多数事务都相当简单,但有两个事务值得在这里进一步讨论。第一个是当缓存试图将权限从 I 或 S 升级到 M 并且目录状态为 S 时发生的事务。缓存控制器向目录发送 GetM,目录执行两个操作。首先,它用包含数据和“AckCount”的消息响应请求者; AckCount 是块当前共享者的数量。目录将 AckCount 发送给请求者,以通知请求者有多少共享者必须确认已使他们的块无效以响应 GetM。其次,目录向所有当前共享者发送无效 (Inv) 消息。每个共享者在收到 Invalidation 后,会向请求者发送 Invalidation-Ack (Inv-Ack)。一旦请求者收到来自目录的消息和所有 Inv-Ack 消息,它就完成了事务。收到所有 Inv-Ack 消息的请求者知道该块不再有任何读者,因此它可以在不违反一致性的情况下写入该块。
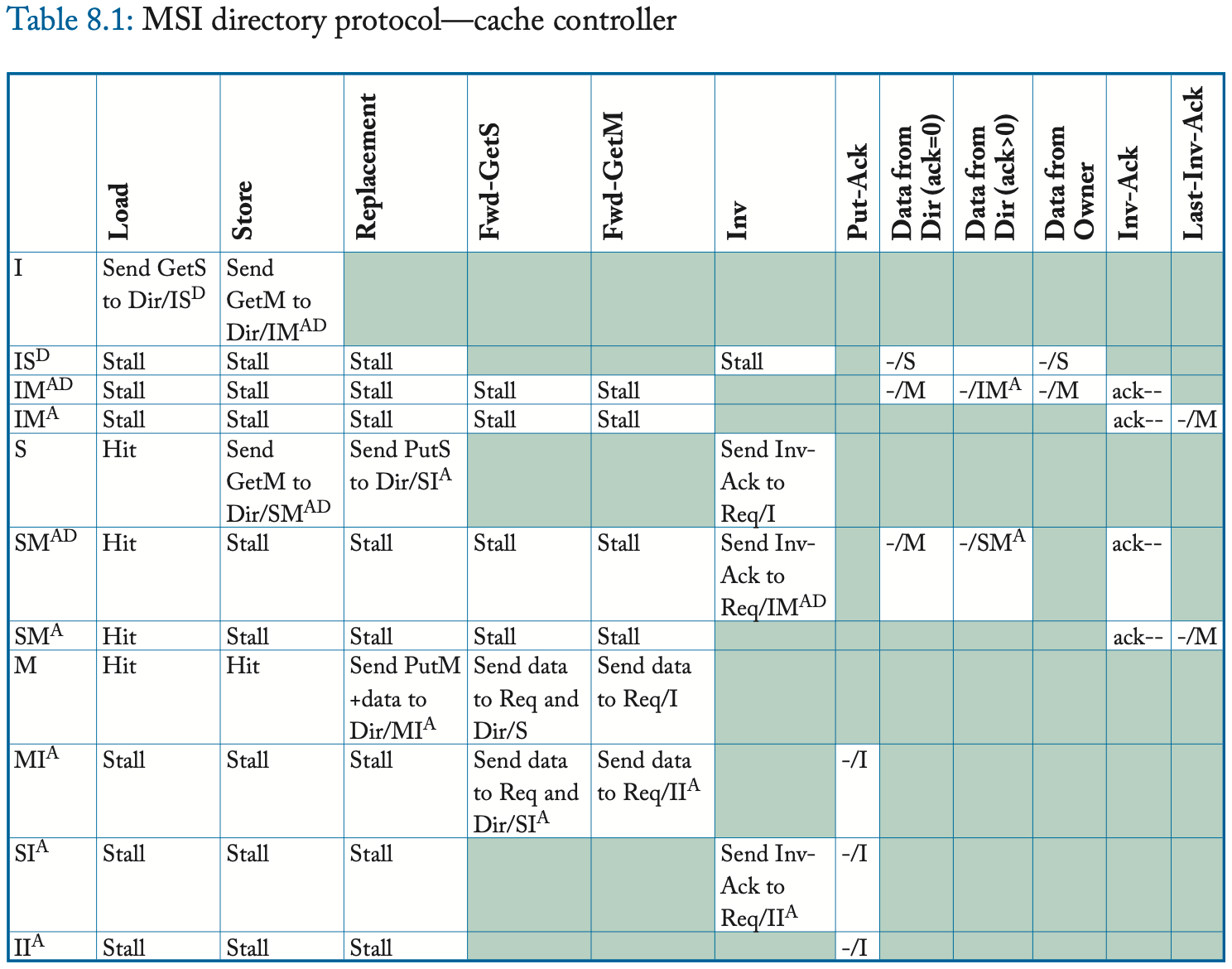
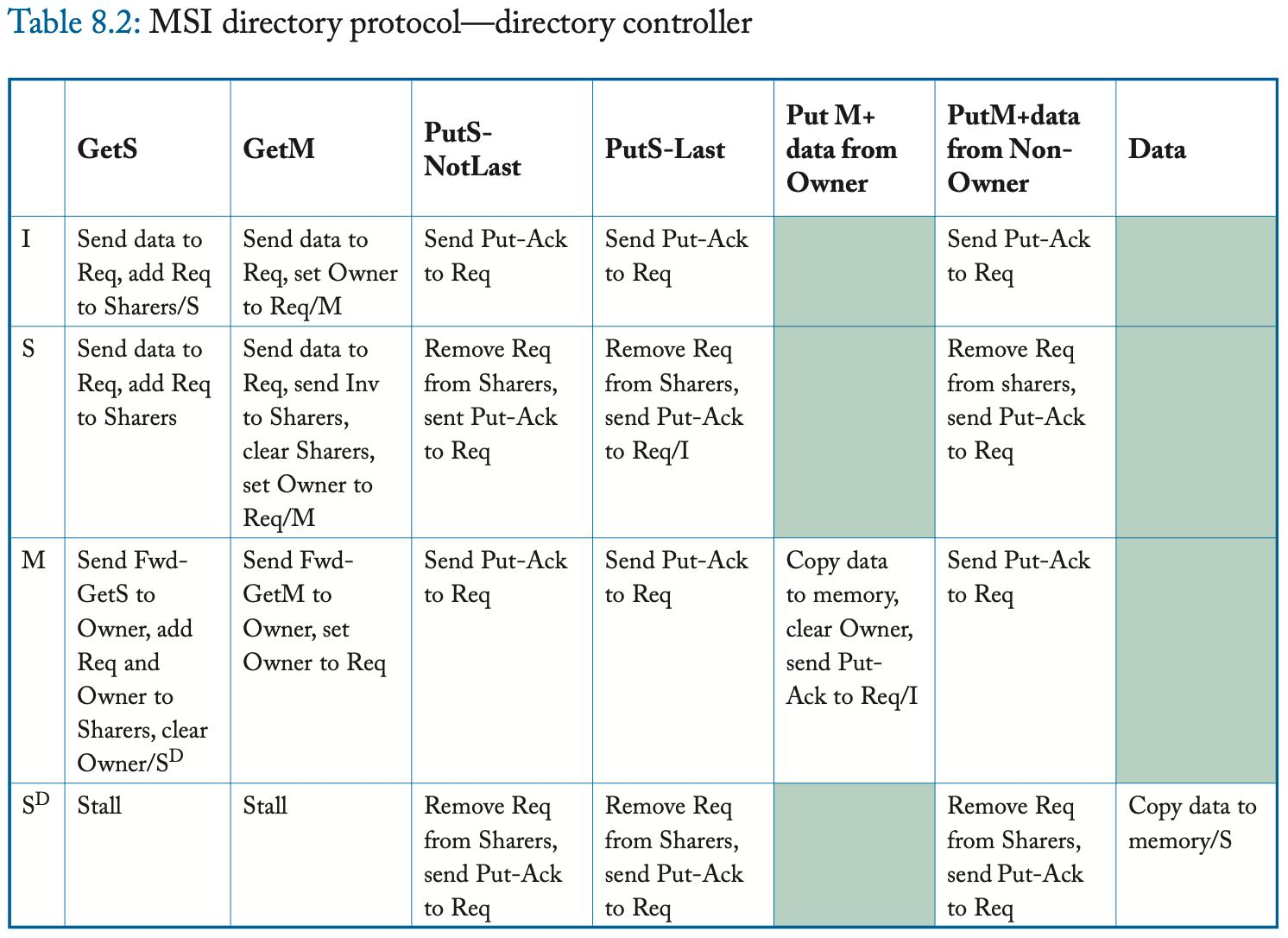
我们在表 8.1 和 8.2 中提供了详细的协议规范,包括所有瞬间状态。与第 8.2.2 节中的高层次描述相比,最显着的区别是瞬间状态。一致性控制器必须管理处于一致性事务中的块的状态,包括缓存控制器在将其一致性请求发送到目录和接收其所有必要的响应消息之间接收来自另一个控制器的转发请求的情况,包括数据和可能的 Inv-Ack。缓存控制器可以在未命中状态处理寄存器 (miss status handling register, MSHR) 中维护此状态,核心使用该寄存器跟踪未完成的一致性请求。在符号上,我们以 XY^AD 的形式表示这些瞬间状态,其中上标 A 表示等待确认,上标 D 表示等待数据。 (这种表示法不同于监听协议,其中上标 A 表示等待请求出现在总线上。)
8.2.5 协议操作
该协议使缓存能够获取处于状态 S 和 M 的块,并将块替换到处于这两种状态中的目录中。
I to S (common case #1)
缓存控制器向目录发送 GetS 请求并将块状态从 I 更改为 IS^D。 目录接收到这个请求,如果该目录是所有者(即当前没有缓存在 M 中拥有该块),则该目录以 Data 消息响应,将块的状态更改为 S(如果它已经不是 S),并且 将请求者添加到共享者列表 (sharer list)。 当数据到达请求者时,缓存控制器将块的状态更改为 S,完成事务。
I to S (common case #2)
缓存控制器向目录发送 GetS 请求并将块状态从 I 更改为 IS^D。 如果目录不是所有者(即存在当前在 M 中具有块的缓存),则目录将请求转发给所有者并将块的状态更改为瞬态 S^D。 所有者通过向请求者发送 Data 并将块的状态更改为 S 来响应此 Fwd-GetS 消息。现在的先前所有者还必须将 Data 发送到目录,因为它正在放弃对目录的所有权,该目录必须具有块的最新副本。 当数据到达请求者时,缓存控制器将块状态更改为 S 并认为事务完成。 当 Data 到达目录时,目录将其复制到内存中,将块状态更改为 S,并认为事务完成。
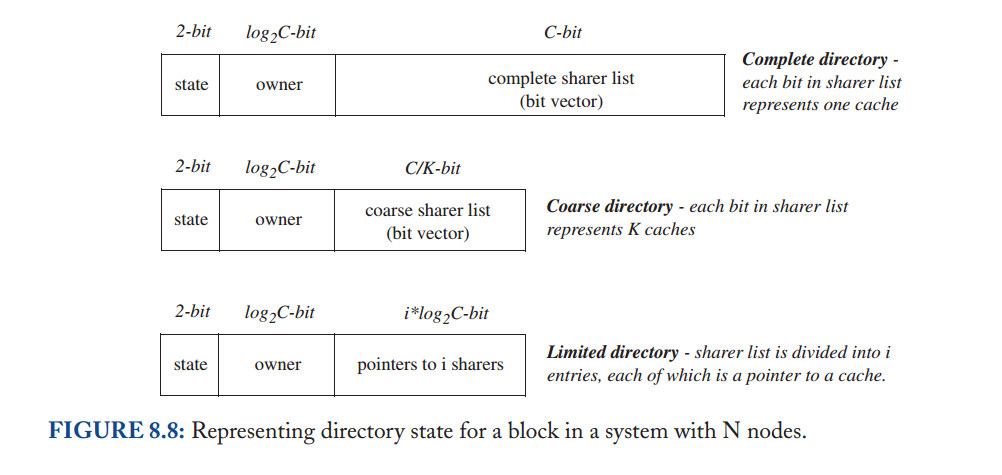
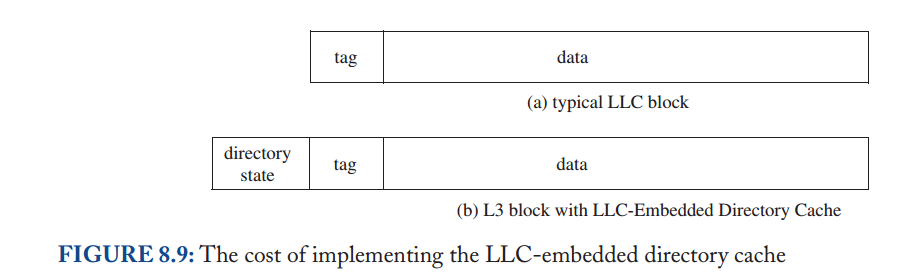
在前面的小节中,我们假设了一个完整的目录;也就是说,目录维护每个块的完整状态,包括(可能)具有共享副本的完整缓存集。然而,这个假设与目录协议的主要动机相矛盾:可扩展性(scalability)。在具有大量缓存的系统中(即,一个块的大量潜在共享者),维护每个块的完整共享者集需要大量的存储空间,即使使用紧凑的位向量表示也是如此。对于具有适度数量的缓存的系统,能够维护这个完整的集合可能是有原因的,但是大型系统的架构师可能希望有更可扩展的解决方案来维护目录状态。有许多方法可以减少目录为每个块维护的状态量。这里我们讨论两种重要的技术:粗目录和有限指针(coarse directories and limited pointers.)。我们单独讨论这些技术,但注意到它们可以结合使用。我们将每个解决方案与基线设计进行对比,如图8.8顶部条目所示。
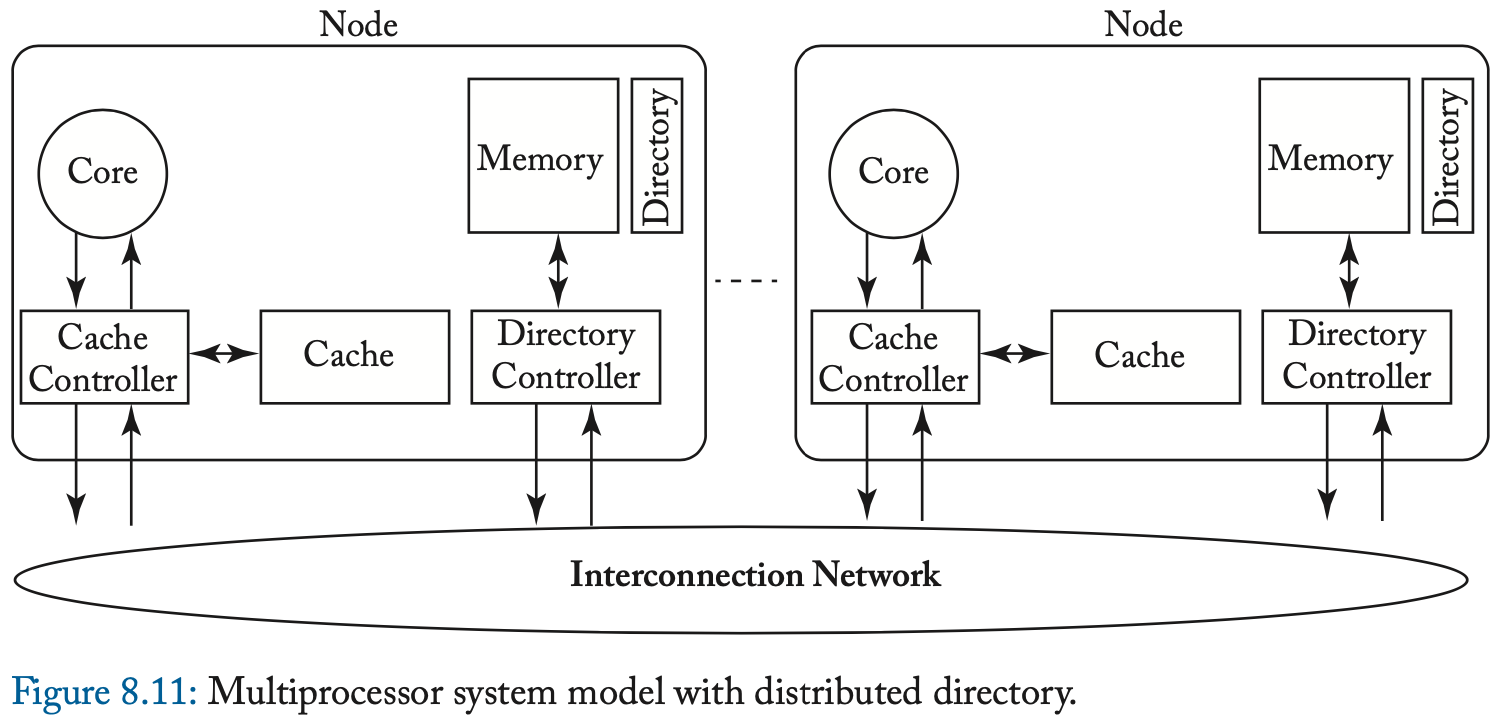
在较旧的具有 N 个节点的多芯片多处理器中(每个节点由多个芯片组成,包括处理器核心和内存),每个节点通常具有与其关联的内存的 1/N 以及相应的目录状态的 1/N 。
我们在图 8.11 中说明了这样一个系统模型。 节点的内存地址分配通常是静态的,并且通常可以使用简单的算术轻松计算。 例如,在具有 N 个目录的系统中,块 B 的目录项可能位于目录 B 模 N 处。每个块都有一个主目录,即保存其内存和目录状态的目录。 因此,我们最终得到一个系统,其中有多个独立的目录管理不同块集的一致性。 与要求所有一致性流量通过单个中央资源相比,拥有多个目录可以提供更大的一致性事务带宽。 重要的是,分发目录对一致性协议没有影响。
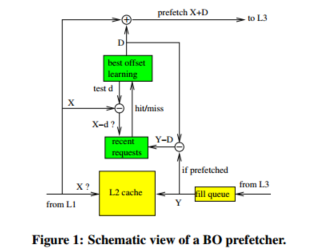
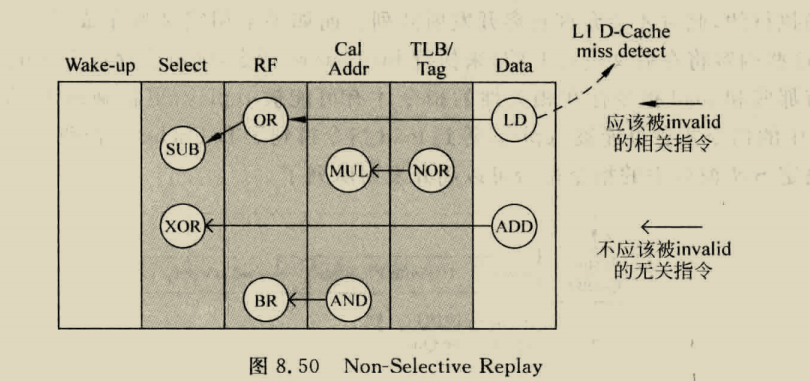
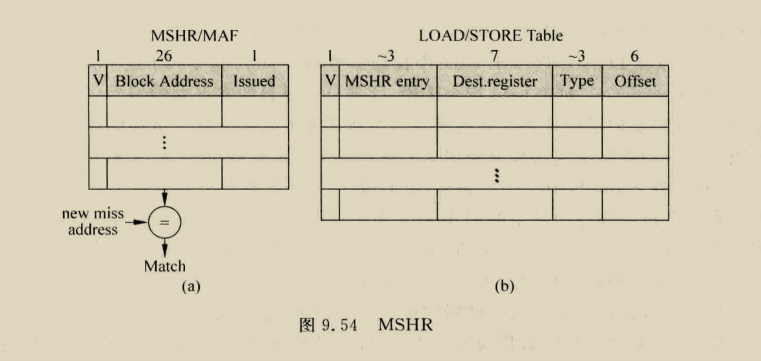
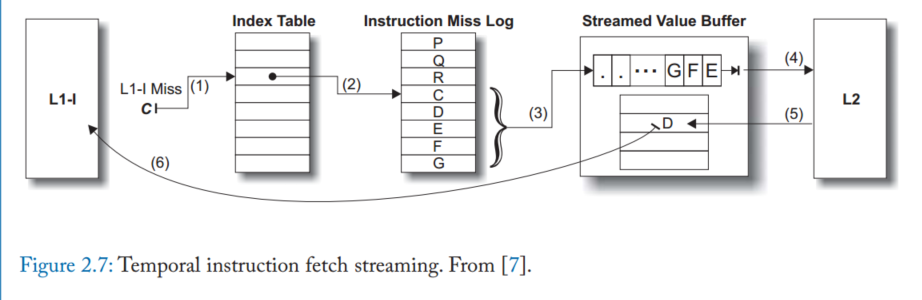
他依赖两个预测,首先就是必须预测缓存块何时失效,这个事件可以通过code correlation [51, 54, 62], or time keeping发现,代码相关预测就是识别缓存快被移除之前访问缓存的最后一条指令,也就是,在该快变为死块之前访问,代码相关性依赖于每次缓存快进入缓存,他们往往会被相同的load和store序列访问,从分配块的初始丢失,到访问序列,最后到块失效时的最后一次访问。
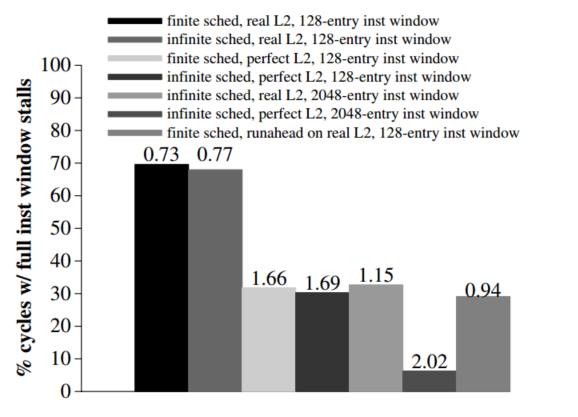
CPU任何时候都可以进入runahead,本论文在l2cache miss,并且该内存操作到达指令窗口的头部时(也就是最老的指令)进入提前执行.提前执行时的pc得存起来,以便退出runahead恢复archstate,IW中所有指令都被标记为runahead inst,在这个模式中取到的指令也是No updates to the checkpointed register file are allowed during runahead mode.runahead的执行与内存通信和无效结果的传播有关,一些规则:
Invalid bits and instructions.
Propagation of INV values. 进入runahead的第一条无效指令为load或者store(引起这个问题的原因),若为load,则rf的INV拉高,若为store,则runahead cache分配一个表项,并且将dest 的byte置为无效Any invalid instruction that writes to a register marks that register as INV after it is scheduled or executed. Any valid operation that writes to a register resets the INV bit ofits destination register.
Runahead store operations and runahead cache.之前的工作runahead load之前有runahead store(raw)被视为无效指令并被删除我们认为转发是必要的,如果两个指令都在IW中,直接通过store buffer获取指令,如果指令伪退休了, 我们将其存入runahead cache,其目的是转发数据和状态,被替换的dirty行不会存入下一级存储器,而是会直接删除(正常模式的指令无法访问该cache)store buffer 和runahead cache的每个字节都有对应的INV,而runahead cache 中还有STO为,指示store是否写入该字节,只有访问该cache中的STO和valid 之高的line,才不会miss,规则如下:
Execution and prediction of branches.在runahead模式的分支指令预测失败后不会恢复****训练策略runahead 时就训练BHT,这样其训练效果好不能再runahead训练BHT,这样可能导致分支预测不太行,导致runahead遇见分支性能下降只能在runahead训练BHT,正常模式通过fifo访问BHT两种模式有不同的表
Instruction pseudo-retirement during runahead mode. runahead模式退休和正常差不多,区别在于:runahead如果检测ROB有inv指令,直接退休,两种模式均会更新RAT