tilelink_reading note
Tilelink协议
架构与信号描述
TileLink 支持多种类型的通讯代理模块,并定义了三个从简单到复杂的的协议扩展级别。每个级别定义了兼容该级别的通讯代理模块需要支持的协议扩展子集,如下图所示。最简单的是 TileLink 无缓存轻量级(Uncached Lightweight, TL-UL),只支持简单的单个字读写(Get/Put)的存储器操作。相对复杂的 TileLink无缓存重量级(Uncached Heavyweight,TL-UH),添加了预处理(hints)、原子访问和突发访问支持,但不支持一致性的缓存访问。最后,缓存相关级别 TileLink Cached(TL-C)是最复杂(完整)的协议,支持使用一致性的缓存模块。

除了 clock 和 reset 信号之外,TileLink 信号名字的组成:通道识别符(a到e)跟着一个下划线,再接一个信号名(在下面小节中一一列举)。
对于拥有多个 TileLink 接口的设备,推荐在所有 TileLink 信号名字之前加上一些描述性的标示加下划线。例如,a_opcode 变成 gpio_a_opcode。
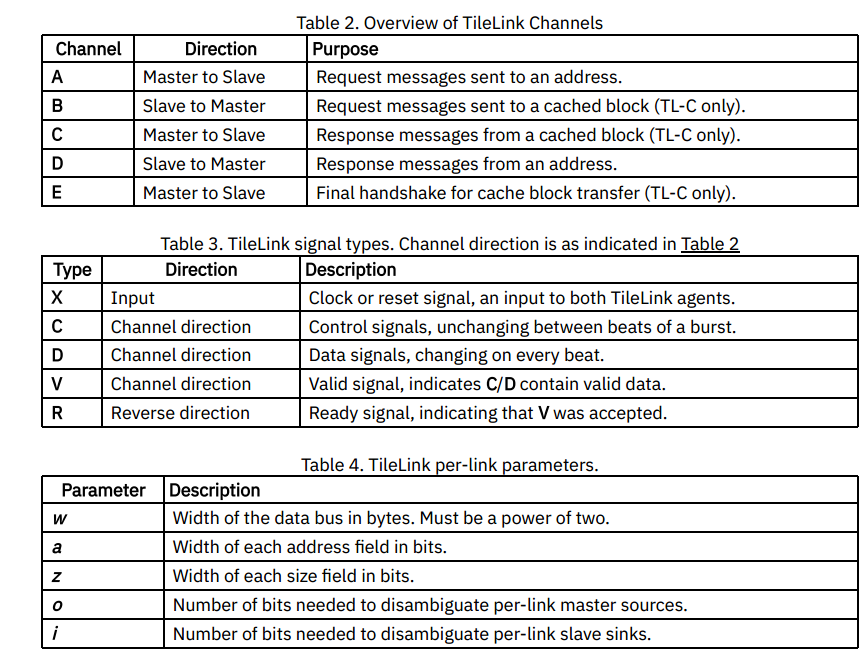
通道A
通道A从主接口流向从接口,携带发送到特定地址的请求消息。此通道由所有TileLink一致性级别使用,并且是强制性的。
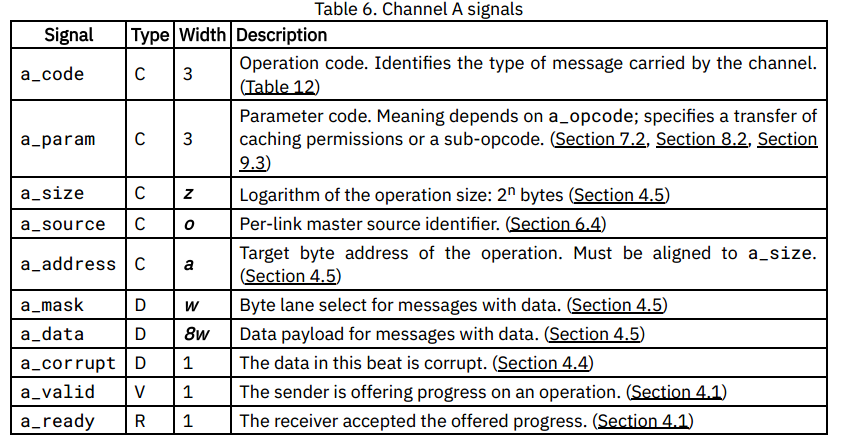
通道B
通道B从从接口流到主接口,携带发送到特定主接口保存的特定缓存数据块的请求消息。该通道由TL-C一致性级别使用,在较低级别中是可选的。
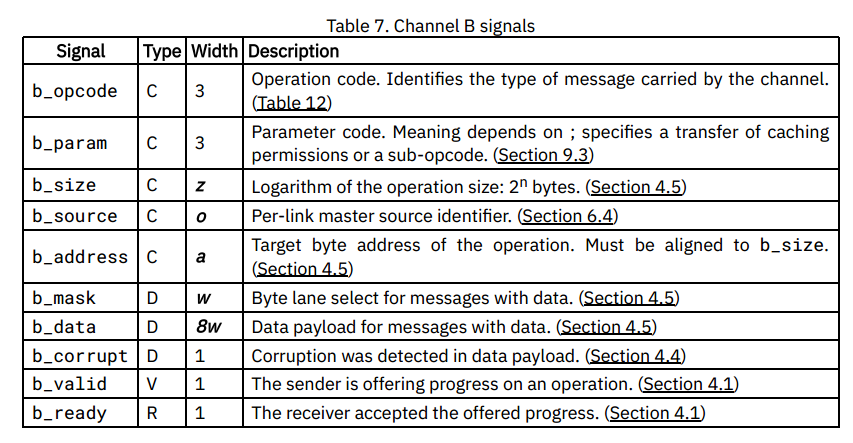
通道C
通道C从主接口流向从接口。它可以携带对发送到特定缓存数据块的通道B请求的响应消息。它还用于主动写回脏缓存数据。此通道用于TL-C一致性级别,在较低级别中是可选的。

通道D
通道D从从接口流向主接口。它携带发送到特定地址的通道A请求的响应消息。它还携带通道C自愿回写的确认。此通道由所有TileLink一致性级别使用,并且是非可选的。

通道E
通道E从主接口流向从接口,携带通道D响应消息的接收确认,用于操作序列化,该通道用于TL-C一致性级别,在较低级别可选。

序列化、死锁
Flow Control Rules
为了实现正确的ready和valid信号握手,需要遵守以下规则:
- 当ready信号为低时,接收者不能处理数据并且发送者认为该拍内的数据未被处理。
- 当valid信号为低时,接收者应当认为该数据信号并不是一个正确的TileLink数据。
- valid必须与ready信号独立,如果一个发送者希望发送一拍数据,则必须使能一 个valid信号,同时该valid信号是与接收者的ready信号独立的。
- 从ready到valid信号或者任何数据或控制信号之间不能存在任何组合逻辑路径。
- 一个低优先级的有效不能组合地依赖于一个高优先级的有效。换句话说,发送一个请求的决定不能基于在同一个周期内接收到一个响应
- 高优先级就绪可能不会组合依赖于低优先级就绪。换句话说,响应的接受可能不会取决于同一周期内接受的请求。
对于能够携带簇发的TileLink的通道,有着额外的规则约束。一个簇发一旦第一拍数据 被接收,直到最后一拍数据传输结束都认为处于传输过程中。当一个数据包处于传输过程中 时,如果valid信号为高,发送者必须满足:
- 只有同消息的簇发的一拍数据。
- 控制信号与第一拍相同。
- 数据为与之前拍数据的地址再加上按数据总线的字节宽度得到的地址所对应的数据。
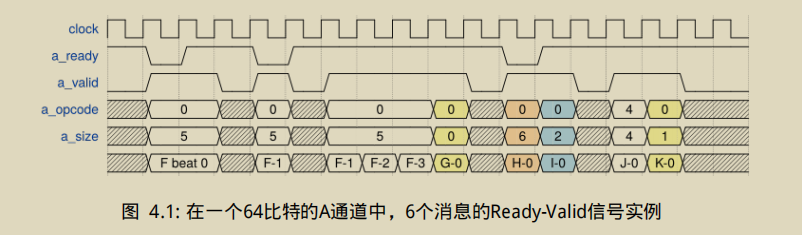
第一个信息为F,size为5,表示传输32个字节,需要四拍,opcode 0表示为PutFullData 4表示Get操作,第二个信息为G,大小为1字节,H被拒绝接受,并且下个周期控制信号改变,变为了传输4个字节的I,之后J虽然size含有16个字节,但GET操作不含数据,故一周期完成
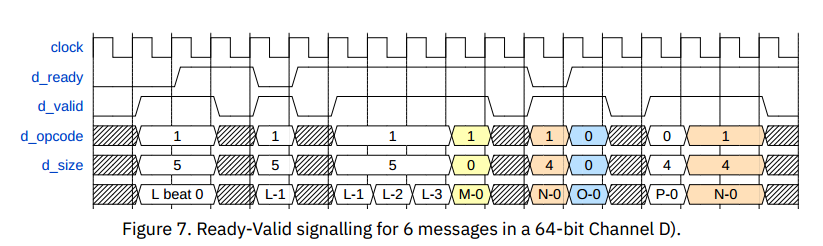
第一个信息为L,opcode为1 表示AccessAckData,含有数据,故需要4拍,之后和上面例子类似
请求响应数据排序
我们现在定义在一个具有多拍数据包的情况下,发送响应消息时的规则。在如下情况下,响应消息的第一拍可以出现在响应通道上:
- 在请求消息被接收了的同一个周期出现,但不会在这周期之前出现。
- 在请求消息的第一拍握手成功之后的任意时间
跟随在包的响应消息的第一拍后的多拍信号可以在任意延迟后出现,但与此同时,不能有来自其他消息的任一拍数据交错地插入此次传输中。
Burst Responses
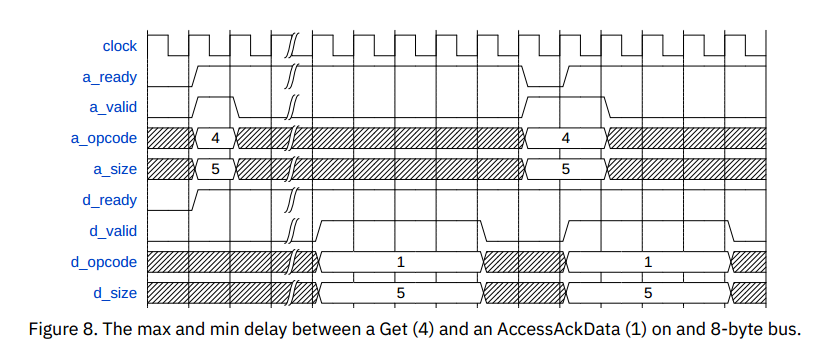
第一个请求的ack在任意延迟后出现在D通道,第二个请求在被接受的同时,d通道出现ack
Burst Requests
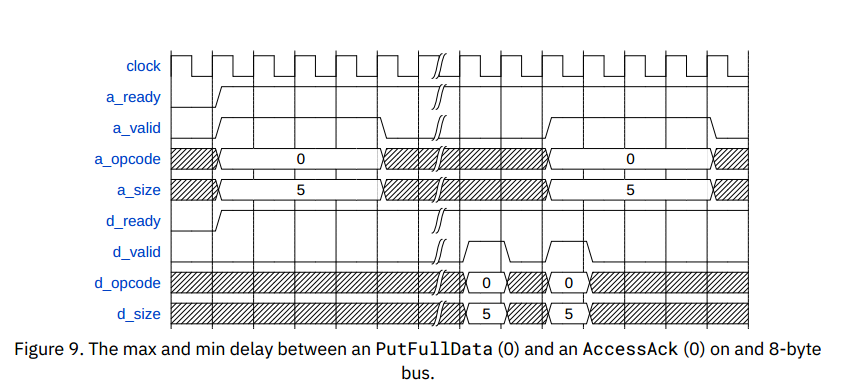
第一个AcessAck被延迟任意长时间,但请求者会发送余下的信息
第二个AcessAck在PutFullData同一拍出现,
Burst Requests and Responses
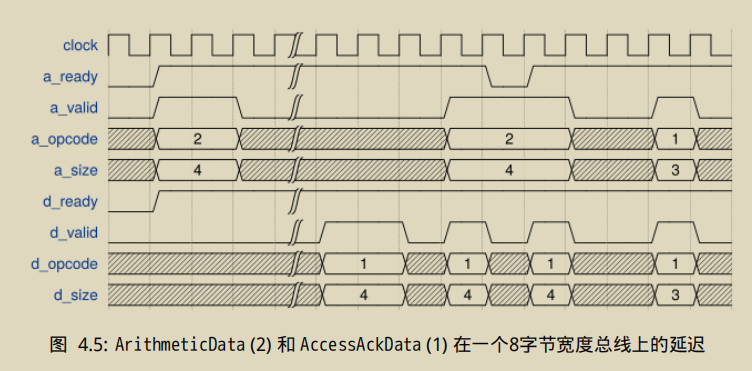
对于大小为4,16字节(2拍)的操作,要么在请求和响应消息之间存在较长的延迟,要么两者的各拍信号重叠。如果每条消息的整体都能放入一拍之中(2ˆ3=8=1beat),那么这些消息就能完全地重叠。
Byte Lanes
带有数据域的TileLink通道总是自然地以小端对齐方式运载数据载荷,一个字节通路传输的数据的地址的最低一部分总是相同的,如下图所示。

一个操作要么使用所有的数据字节通道,要么使用其中一个2的幂大小的片段。操作使用的字节通道称为活动字节通道。
在携带掩码字段的通道A和B上,所有非活动字节通道的掩码必须始终为LOW。此外,对于PutPartialData以外的所有消息,所有活动字节通道的掩码位必须为HIGH。PutPartialData可以降低掩码的各个位,并且这些位不必连续。
掩码也用于没有数据有效载荷的消息。当操作大小小于数据总线时,掩码的生成应该与携带数据有效载荷的操作相同。对于大于数据总线的无数据操作,掩码的所有位都应该为高,尽管消息仍然是单拍。例如,参见图12。
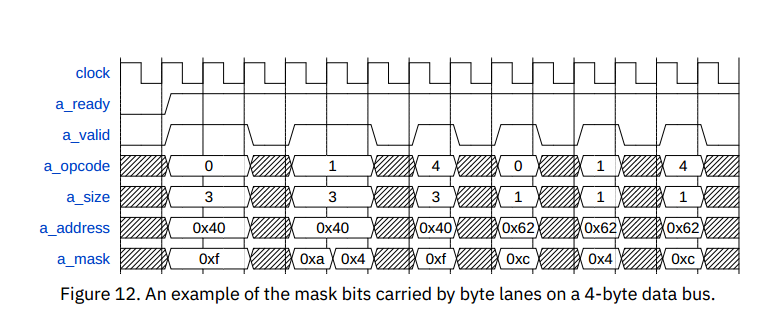
在图12中,PutFullData(0)必须将掩码的所有活动通道驱动为高。因此,第一个消息在多个节拍上具有所有节拍高。相比之下,PutPartialData(1)可以将掩码的活动通道驱动为高或低。Get(4)消息从不是多节拍的,但仍然必须将活动字节通道上的掩码驱动为高。对于小于节拍的消息,掩码的所有非活动字节通道必须被驱动为低(寻址0x62的操作中的位0和1)。
Deadlock Freedom

- 接受(accept)一拍:若发送者在某个通道上把valid信号拉高,接收者若把ready信号拉高则接受一拍。
- 拒绝(reject)一拍:若发送者在某个通道上把valid信号拉高,接收者若把ready信号拉低则接受一拍。
- 撤回(retract)一拍:若接收者拒绝一拍,发送者可以拉低valid或在下一拍修改控制或数据信号来撤回一拍。
- 呈现(present)一拍:若valid拉高且所有控制和数据信号在ready也拉高之前都保持不变,称之为呈现一拍。
- 进行中(in progress):一个消息正在进行,表示从被接受的第一拍到最后一拍被接受之间的这段时间。
- 传输中(in flight):一个消息正在进行,表示从被呈现的第一拍到最后一拍被接受之间的这段时间。
- 请求消息:需要一个对应的响应消息,所有的TileLink操作都从某个通道的请求消息开始。
- 响应消息:跟随在请求消息之后的响应。
- 已收到的(received)消息:从簇发传输的第一拍被接受开始,消息被收到。
- 已回答的(answered)消息:收到的请求被响应后,消息被回答。
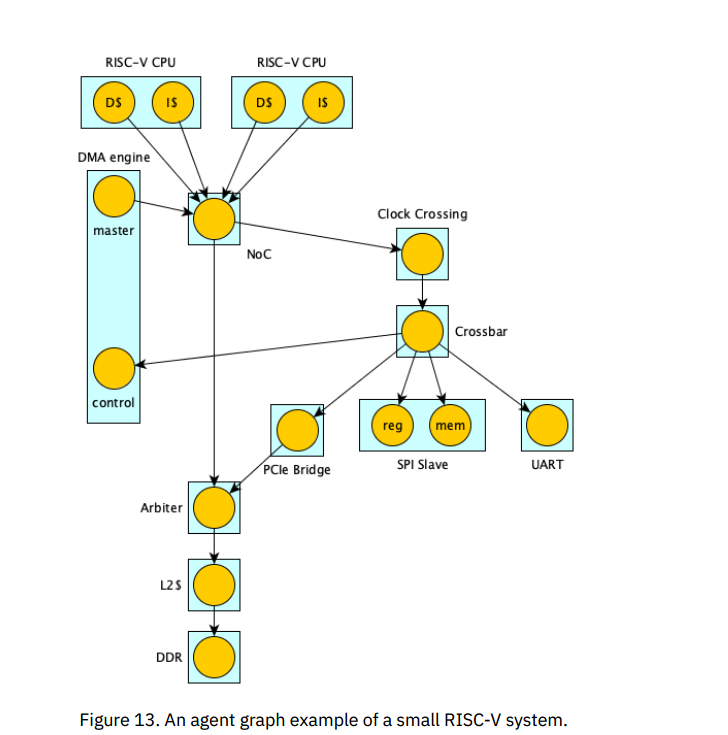
- 代理(agent):TileLink系统中的参与者,有一或多个TileLink链路。
- 优先级:一个消息的优先级与对应通道的优先级对应,响应消息的优先级总是比对应请求的优先级高,转发消息的优先级也更高。
- 最终事件:一个事件在任意长但并非无穷长之后最终发生。
- 向前推进:当所有呈现的拍最终被接受,且所有收到的请求最终被回答时,系统可以向前推进。
- 不活动的(quiescent):当没有添加新的消息时,系统处于不活动的状态,注意尽管TileLink保证不出现死锁,但仍然可能产生活锁或饥饿状态。为了限制这种情况,代理只被允许发送
n+rf个消息,包括n为该代理允许发送的新消息、r为该代理接收的消息以及f为该代理为每个收到的消息允许发送的后续消息。
Examples of agent conformance
周期性转发的主设备(不符合)
一个代理有一个主接口和一个从接口,在A通道接受请求消息,但在转发消息时只在偶数周期拉高valid信号。这个代理不符合协议要求,原因是该代理不能完整呈现转发的消息,不能保证最终回答一个收到的请求。
等待刷新(符合)
一个DDR控制器周期性地无法处理请求,在这段时间内无条件地拉低所有ready信号,但注意到该代理仍然最终可以接受呈现的拍,因此还是符合协议要求的。
等待消息被接收(不符合)
一个代理有两个用于发送消息的链路,在链路1上发起簇发传输A,并且几拍中的第一拍被接受,表明消息已被接收,但仍在传输中,然后在链路2上发起簇发传输B,此时A的传输还未结束。在恢复A之前等待B被接受是不符合协议要求的。
非常慢的仲裁器(符合)
考虑一个具有三个链路的TL-UH代理,仲裁来自两条链路的A通道请求,并转发到第三条链路的A通道,但该仲裁器的吞吐量非常低。
代理空闲时将从任一输入的A通道中选择一个valid请求,一旦选择了一个请求,就会在另一个A通道上拉低ready信号,并在所选链路和输出链路之间连接ready和valid(通道A和D)。一旦请求的所有拍都已被输出通道接受,代理在两个输入A通道上拉低ready信号,并等待响应消息的最后一拍被所选的通道接受。
该代理符合规则2,因为可以假设输入的A通道都遵守规则2,因此其输出的A通道请求将呈现接收到的请求的所有节拍,D通道也同理。
假设代理正在处理输入的一个消息,在转发链路上分别有一个未回答或进行中的消息。由于该链路的优先级高于输入的链路,因此适用规则3,并且代理可以无限期地拒绝后续提交的A通道请求。
假设代理空闲并且没有输入呈现消息,这种情况满足规则3i,因为没有消息可以接受,同时也满足规则3ii,因为只有在收到的请求被回答时,仲裁器才会再次空闲。
操作与信息
操作分类
TileLink 操作能被分为下列三组:
- Accesses (A) 在具体的地址读或写数据。
- Hints (H) 只是提供一些信息,没有实际的影响。
- Transfers (T) 在拓扑网络中改变权限或移动缓存拷贝。
不是每个TileLink代理都需要支持所有操作。取决于其的TileLink兼容级别,一个代理需要支持的操作如下表所列。

消息分类
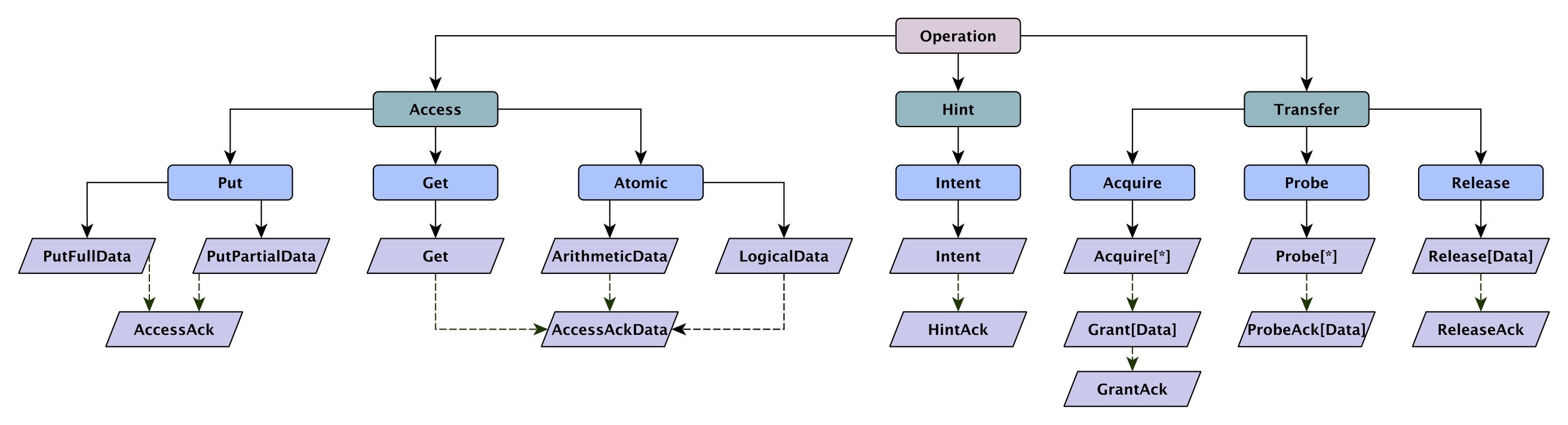
操作为蓝色,紫色为消息
在一个TileLink拓扑网络中,在任意给定时间内会有多个操作在进程中。这些操作可能以任意的顺序完成。为了确保主端能在一个操作完成后,再执行其他操作,TileLink要求从端在操作结束时及时发送一个回复消息。因此,如果处理器要确保两个写操作X和Y的顺序被其他所有代理获取时都是一致的,那么处理器发送X的PutFullData后,必须等待AccessAck回复,在此之后,才发送Y的PutFullData。
TileLink的从端,包括缓存,不能在Put操作确认前就将数据写回。唯一的约束是,一旦确认消息发出后,整个拓扑网络不能观察到过去的状态,这是因为在确认消息发出后,所有的被缓存的数据的拷贝都必须是已更新的。例如,对于一个Put操作,其他缓存要么被Probe现有的数据拷贝,要么通过PutFullData将消息前递给其他缓存,并且在确认原始的请求消息前,收集对应的回复消息。
发射回复消息的代理需要保证它们接收的操作是一个有效的序列。例如,假设一个代理接收了两个Put,X和Y,并且都没有被确认,必须选择一定的顺序,例如说是X在Y之前。如果选择了这样的顺序,必须保证只有三个状态,X与Y前的状态,X之后且Y之前的状态和X与Y之后的状态。代理不一定要以这样的顺序发射回复消息。然而,在代理已发射了一条回复之后,例如Y,如果此时接受了新的操作Z,那么Z必须排在Y之后。
这些规则确保每个代理看到的全局操作排序与主端的确认信号引导的局部排序是一致的。处理器可以等待发出的确认消息返回后再发起其他请求,来实现fence指令。这样的能力使得多处理器在TileLink的共享存储系统中,安全地同步执行操作。
这里的意思是A写入的值需要广播,以此来更新所有缓存块的状态
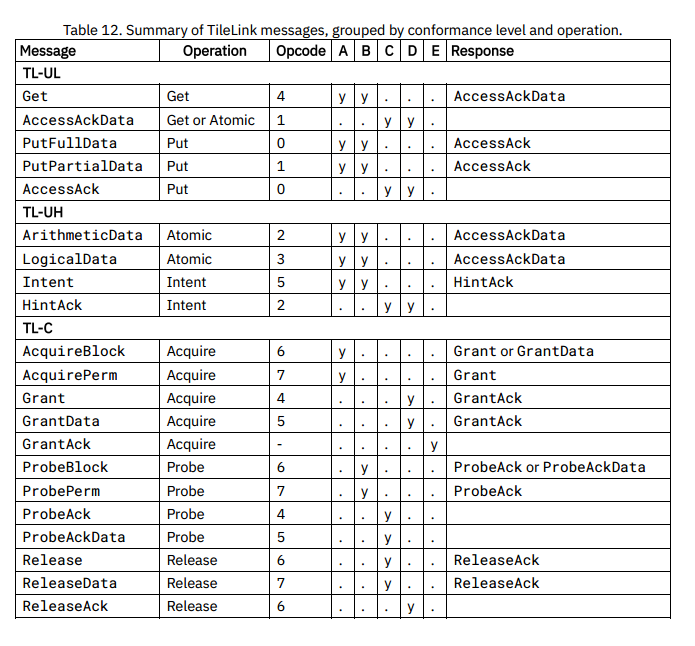
TL-UL
TileLink无缓存轻量级(TL-UL)是最简单的TileLink协议兼容级别,可用于连接低性能的外设以减小总线的面积消耗。该兼容级别的代理都支持两种存储访问操作:
- 读(Get)操作:从底层内存中读取一定量的数据。
- 写(Put)操作:向底层内存中写入一定数目的数据,写操作支持基于字节t通路掩码的部分写功能。
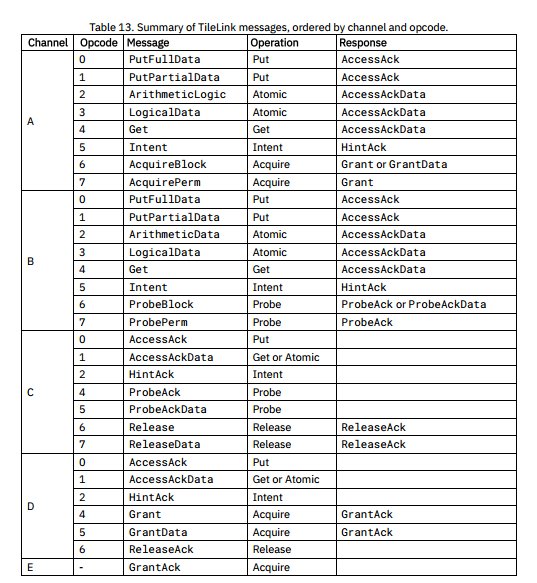
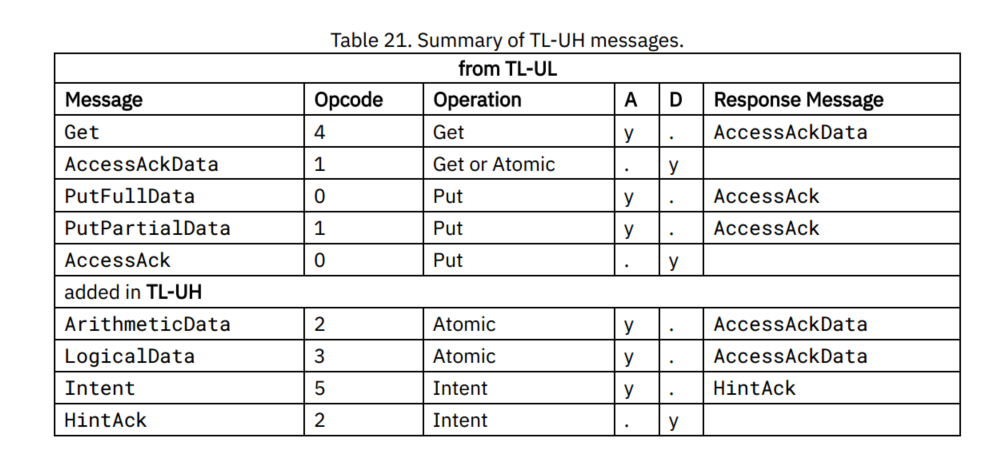
在TL-UL中,每条消息都必须放在一拍中,不支持簇发操作,TL-UL一共定义了与存储访问操作相关的三种请求消息和两种响应消息类型,下表列举了这些消息。
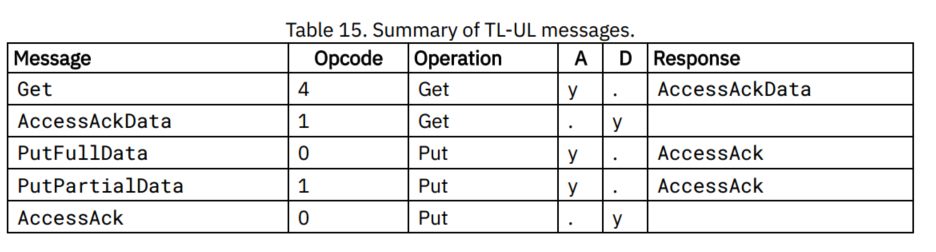
Flows and Waves
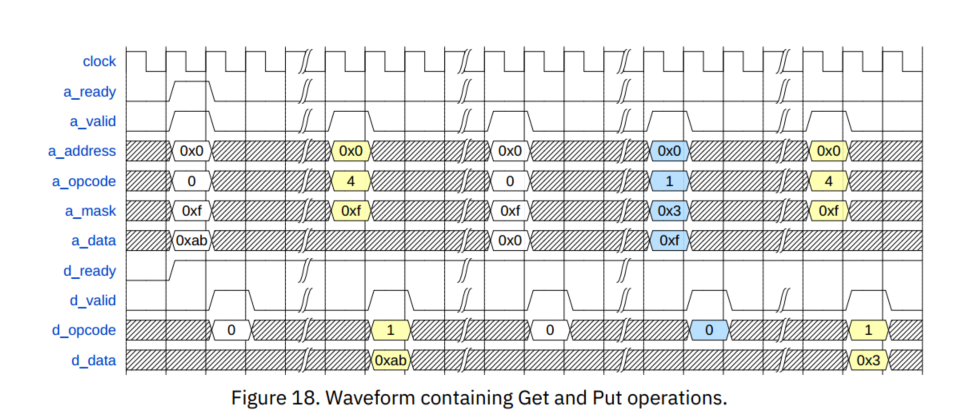
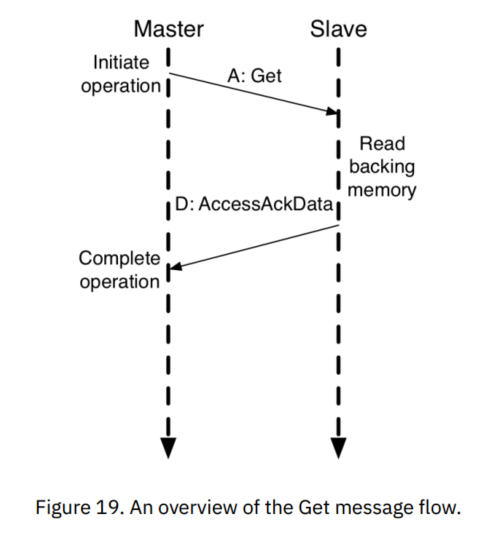
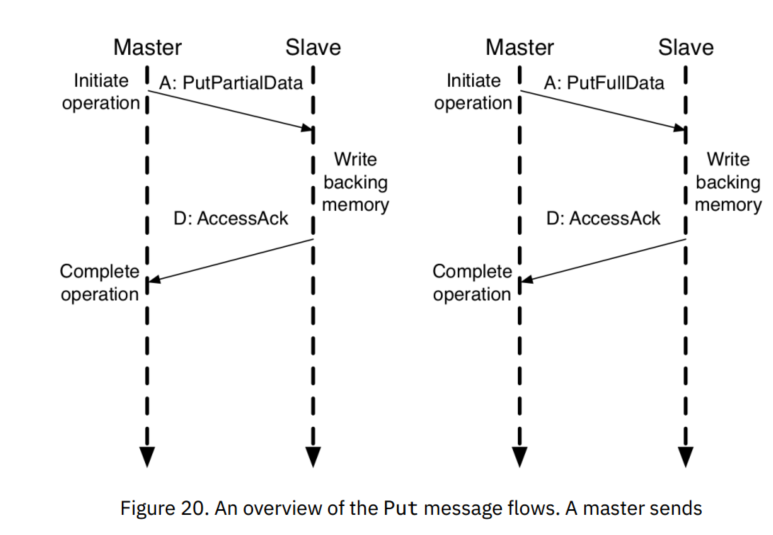
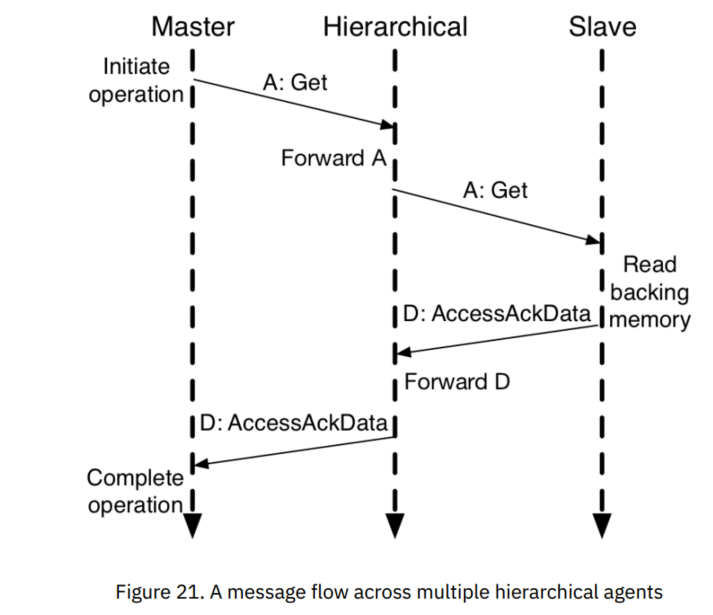
TL-UH
TileLink无缓冲重量级(TL-UH)用于最后一级缓存之外的总线,这种应用中不需要使用权限转换的操作。TL-UH建立在TL-UL的基础上,并提供一部分额外的操作,包括:
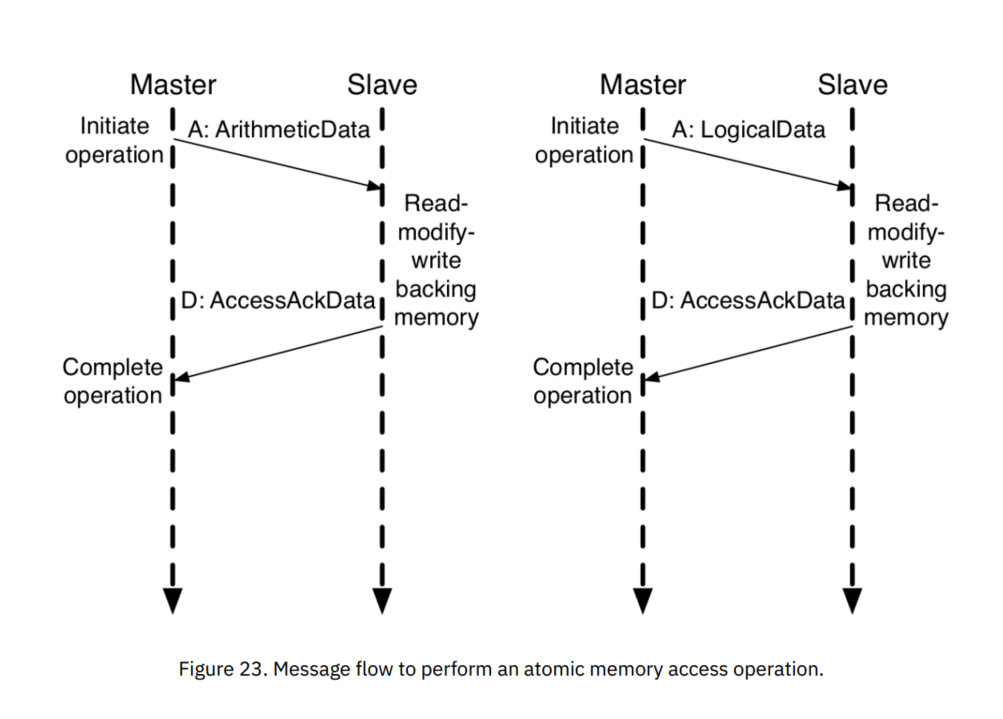
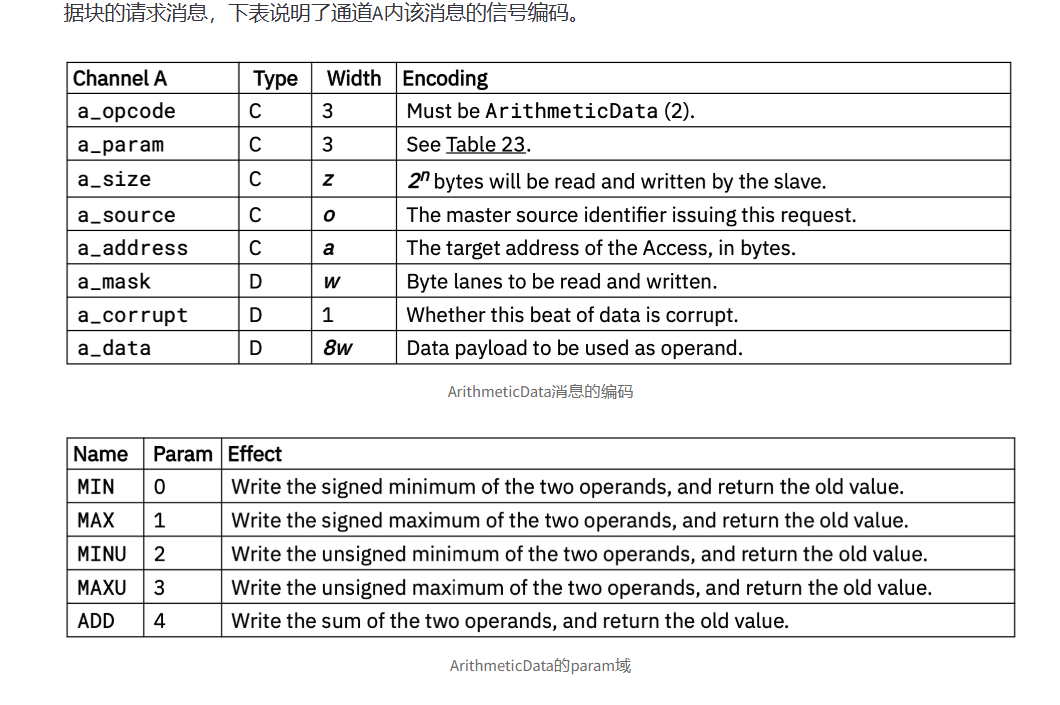
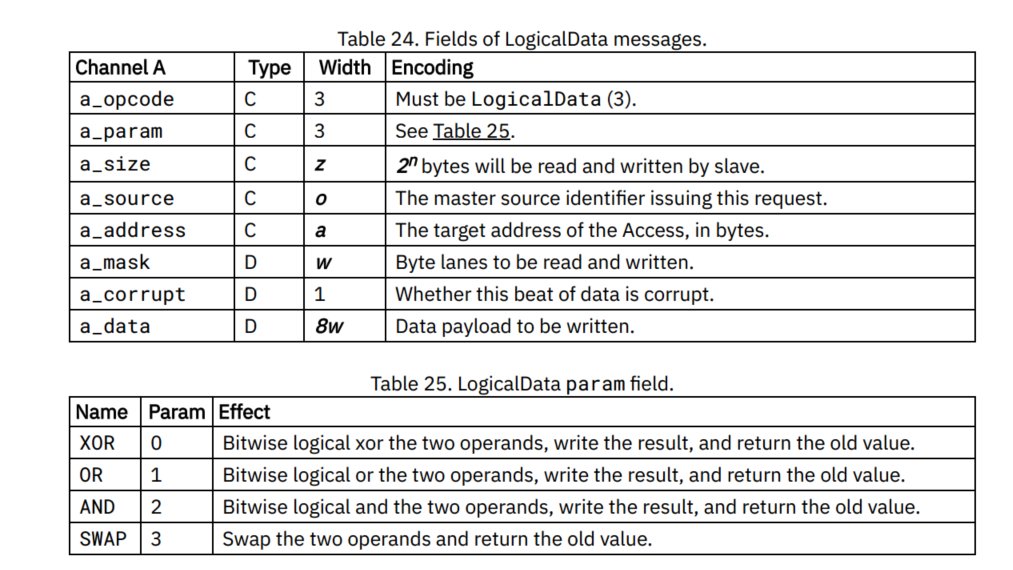
- 原子(Atomic)操作:在原子性地读取现存的数据值的同时,同步地写入一个新的值,此新值为某些逻辑和算法操作的结果。
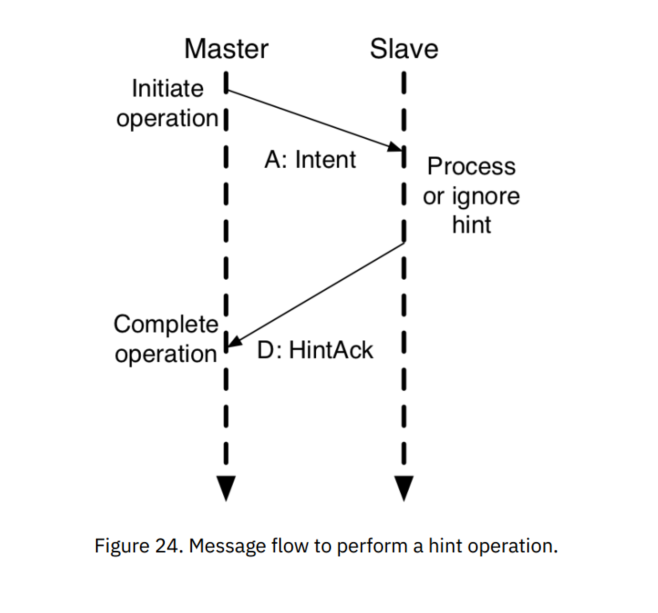
- 预处理(Hint)操作:提供了与某些性能优化相关的可选的提示性消息。
- 簇发(Burst)消息:允许带有比数据总线宽度更大的数据的消息在多个周期内作为数据包传输,应用于在Get、Put和原子操作中多种包含数据的消息。
Flows and Waves
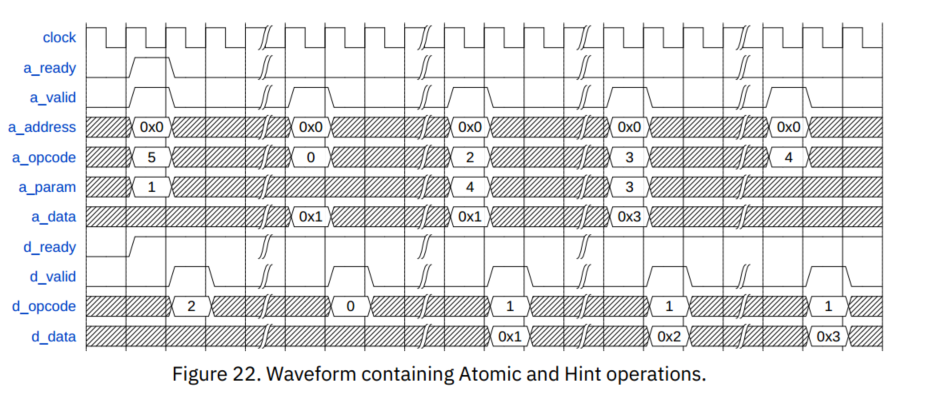
ArithmeticData
LogicalData
Intent
HintAck

TL-C
TileLink缓存支持级(TL-C)给主端代理提供缓存共享数据块副本的能力,保证缓存一致性。本章描述TL-C中缓存的数据副本上允许进行哪些访存操作,以及用来传输数据块的缓存的消息类型,实现中所定义的一致性协议描述了副本和权限如何通过具体的TileLink代理网络传输以回复所接收的存储访问操作,但具体的一致性协议描述不在TileLink协议内容范围内。
TL-C新添加了三种操作、三个通道、一个五步的消息序列模板以及十种消息类型。
新的操作transfer可以创建或者清除数据块的缓存副本。转换操作不会修改数据块的值,但是会改变他们的读写权限。转换操作可以与之前定义的TL-UL、TL-UH访存操作无缝协作,保证操作进行序列化的正确性。
可缓存性是存储地址范围的一个属性,一个TileLink的实现需保证避免无法缓存地址范围的副本出现。
Implementing Cache Coherence Using TileLink
所有基于Tilelink的一致性协议都由一系列操作组成,通过这些操作,可以完成读写数据块权限的在转变。在代理对已缓存的副本执行响应的操作之前,必须获得正确的权限。当代理希望在本地处理一个访问操作时,它必须首先使用转换操作来获得必要的权限。转换操作在网络上创建或删除副本,从而修改每个副本可以提供的权限。
代理中数据块副本的基本权限可以包括:None、Read或Read+Write。缓存架构中副本 可用的权限取决于缓存层次结构中副本的当前存在情况,如下所述。
对于任何给定的地址,在给定主端和拥有该地址范围的从端之间都只会存在一个具体的路径。在TileLink网络DAG中,所有这些路径都覆盖会形成一个树,根节点上仅有一个从端节点。对于每个地址,此树包含所有针对该地址的操作执行的路径。如果我们省略了所有不能缓存数据的代理,那么就会留下一个描述所有可能缓存该地址数据的缓存代理位置的树。
在逻辑时间的任意时刻,这些代理的某些子集真正包含缓存数据的副本。这些代理形成 了一致性树 。包容性(Inclusive)的TileLink一致性协议要求树在响应内存访问操作时进行提权(Grow)和降权(Shrink)操作。图中的每个节点都属于树中的位置,分为以下四类:
- Nothing:当前没有缓存数据副本的节点,没有读写权限。
- 主干(Trunk):在顶点(Tip)和根(Root)之间的路径上拥有缓存副本的节点,具有其副本的读权限,该副本可能包含脏数据。
- 无分支的顶点(Tip with no Branches):具有缓存副本的节点,且可以用作内存访问序列化,对其拥有的可能包含脏数据的副本具有读写权限。
- 有分支的顶点(Tip with Branches):具有缓存副本的节点,且可以用作内存写入序列化,对其拥有的可能包含过去写入的脏数据的副本具有读写权限。
- 分支(Branch):该节点由Trunk结点分出,具有只读数据缓存副本。
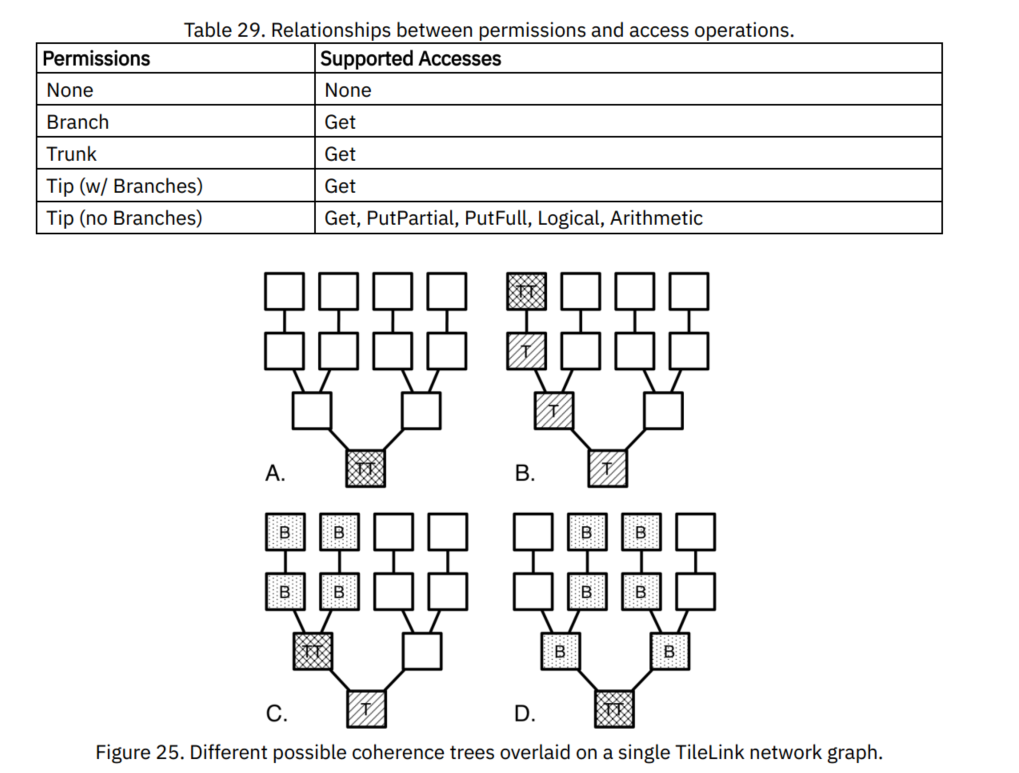
上图例举了几个覆盖在单个TileLink网络上的一致性树。在A中,树的根节点有唯一的 副本,这使得它既是树的根节点,也是树的顶端节点。在B中,主端通过提升主干的特权 (Grow),获得读写权限,直到其位于顶点处。在C中,另一个主端通过扩展一个分支获得了读权限,这意味着之前的顶点现在也是一个只读分支,且公共的父节点是主干节点。在D中,其他主端也升级为分支,进一步将尖端向根部移动,而最初的请求者已经主动修剪了其分支。
Operations
三个新操作统称为transfer操作,原因是这些操作将数据块的副本传输到内存层次结构中的新位置,包括:
- Acquire:在请求主端中创建块(或其特定权限)的新副本。
- Release:从请求的主端将块的副本(或其特定权限)释放回从端。
- Probe:强制将块的副本(或其特定权限)从主端移到发起请求的从端。
Acquire操作要么以扩展树干的形式,要么以从现存的分支或者尖端添加新的分支的形式来拓展树。在新的分支生成前,旧的主干或分支可能需要递归的Probe方法进行修剪。为了响应缓存容量冲突,可通过Release操作主动裁剪分支。
Channels
为了支持转换操作,TL-C在执行内存访问操作所需的两个基本通道上添加了三个新通道。A和D通道也被重新用于发送额外的消息,以实现转换操作。转换操作使用的五个通道
分别是:
通道A. 主端为了读取或写入缓存块副本而发起对权限的请求。
通道B. 从端查询或修改主端对缓存数据块的权限,或将内存访问前递(forward)给主端。
通道C. 主端响应通道B传输的消息,可能会释放带有任脏数据块的权限。也用于主动回写脏的缓存数据。
通道D. 从端向原始请求者提供数据或权限,授予对缓存块的访问权。也用于确认脏数据的主动写回。
通道E. 主端提供此次事务完成的最终确认消息,从端可用来事务序列化
这五个通道可分为11种消息
Permissions Transitions
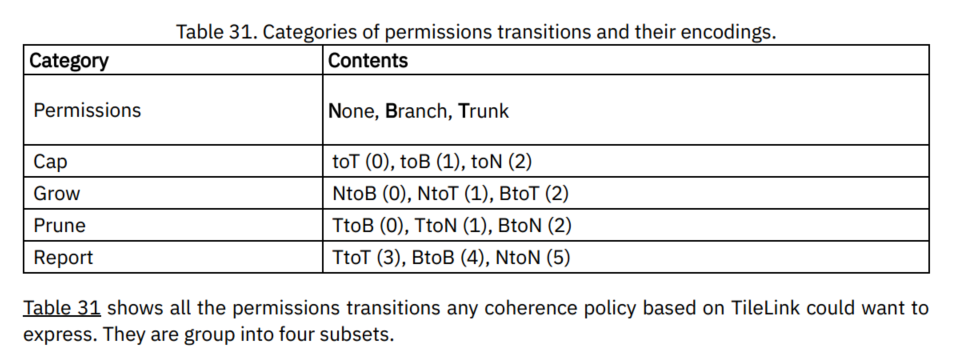
Prune: 权限降级,缩小一致性树。相比过去,完成操作之后具有较低的权限。
Grow: 权限升级,增大一致性树。相比过去,完成操作之后具有较高的权限。
Report: 包含权限保持不变,但报告当前权限状态。
Cap: 包含权限更改,但不指定原始权限是什么,而只指定它们应该成为什么。
Flows and Waves
Transfer操作引入新的事务流,这些事务流可以组成完整的缓存一致性协议事务。下图描述了三个新消息流。
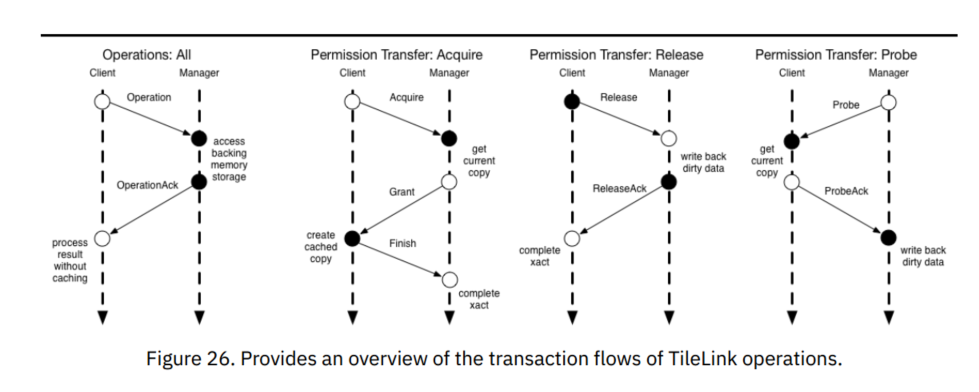
上图的消息流涵盖了三种新操作:
- 缓存主代理向从代理发送Acquire。
- 为保证给响应消息留足够空间,主代理主动发送Release,即写回操作。(替换脏数据)
- 从代理访问存储结构,以完成写操作。
- 从代理通过ReleaseAck确认写回操作已完成。
- 从代理向其他主代理发送必需的Probe。
- 从代理等待所有被Probe的主代理返回ProbeAck。
- 若有需要,从代理还需访问存储结构。
- 从代理向原请求设备发送Grant。
- 原主代理以GrantAck说明此次事务成功完成。
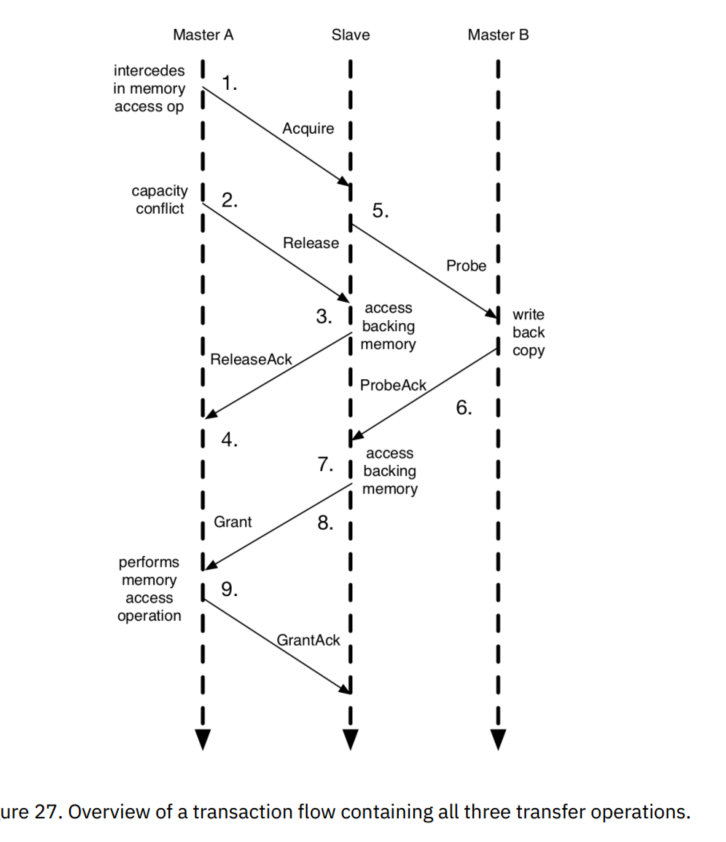
虽然这三个流程构成了所有涉及缓存块传输的TileLink事务的基础,但是当它们临时地重叠或分层地组合时,会出现一些边界情况。现在我们将讨论TileLink如何管理并发性,并分散到各主从代理之间。
TileLink假设消息并不完全是点到点的有序的传递,来自高优先级通道的消息必须能够在网络中先于较低优先级的消息处理,从端充当连接到它的所有主端的一个同步节点。由于每个事务都必须通过发送给从端的一条Acquire消息作为初始消息,因此从端可以轻松对事务进行排序。一个非常安全的实现方式是一次只接受一个事务,但是这种方式对性能影响巨大,而且事实证明我们可以在继续提供正确的序列化的同时增加并发性。尽管事务有着天然的分布式属性,对代理的行为施加一些限制,仍能够保证事务间的有序性。下图描述了每种操作并发的一些限制。
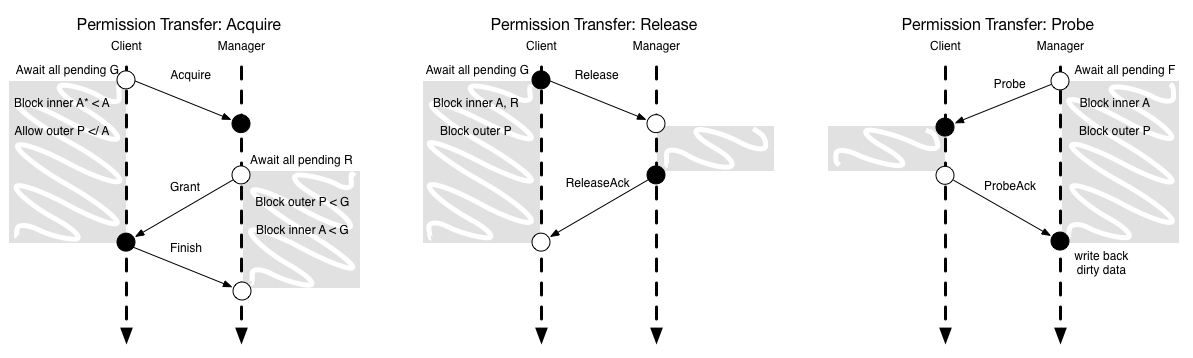
对TileLink代理上的并发限制在发射或阻塞请求消息方面最容易理解。所有请求消息都会引发响应消息,并且响应消息保证最终产生向前推进的效果,但是在某些情况下,在收到还未处理的响应消息之前,不应该发出针对同一块的递归请求消息。我们按照请求消息类型来对这些情况分类:
- Acquire:如果在块上有一个pending的Grant块,主端就不应发射一个Acquire。一旦Acquire被发出,主端不应该在该块发出进一步的Acquire,直到它收到一个Grant。
- Grant:在块上有一个pending的ProbeAck时,从端不应该发射Grant。一旦发出了一个Grant时,从端不应该在该块上发射Probe,直到它收到一个GrantAck。
- Release:在块上有一个pending的Grant时,主端不应该发射一个Release。一旦发出了一个Release后,主端不能发射ProbeAck,直到它收到来自从端确认写回操作完成的ReleaseAck。
- Probe:在块上有一个pending的GrantAck时,从端不应该发射一个Probe。一旦发射了一个Probe,从端不能进一步发射Probe,直到它收到一个ProbeAck。
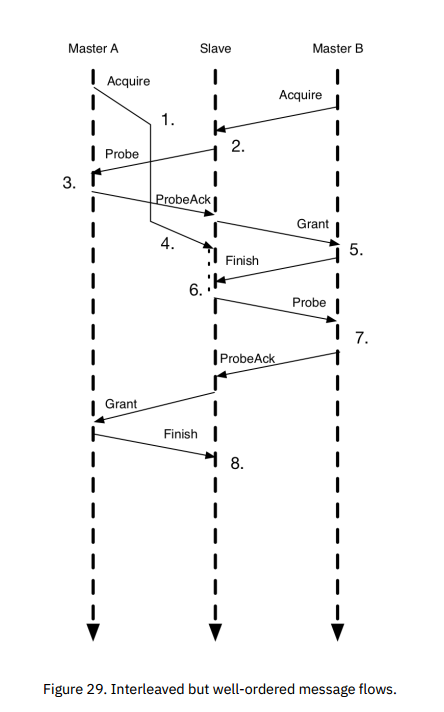
上图展示了一个消息流,包含了Grant和Probe,具体如下:
- 主代理A先发送Acquire,但由于网络延迟,后到从代理。
- 主代理B后发送Acquire,但先到达从代理,被序列化在A的前面。
- 从代理向A发送Probe,即使A还在等待Grant,也必须先处理Probe。
- 从代理接收到A的ProbeAck后,向B发送Grant。
- 从代理接收到A的Acquire,但由于正等待B的GrantAck,所以现在还不能处理这个请求。
- 一旦接收到B的GrantAck,A的事务就可以正常处理了。
- 从代理向B发送Probe,但这个操作被在上一个Grant之后。
- 从代理向A发送合适类型的Grant(包括数据副本),说明A在Acquire后被Probe过。
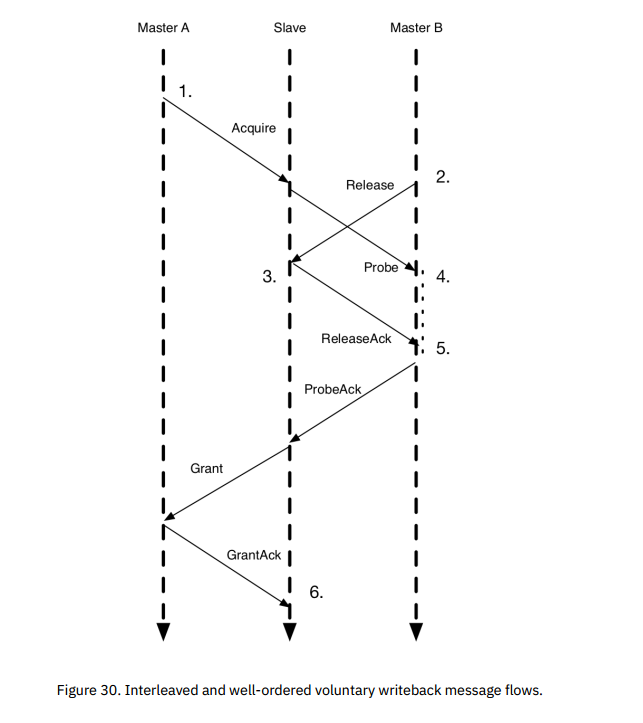
上图展示了一个消息流,包含了Release和Probe,具体如下:
- 主代理A向从代理发送Acquire。
- 与此同时,主代理B通过Release主动剔除相同的数据缓存块。
- 从代理向B发送Probe。
- 从代理等待每个发送出的Probe,但可以处理主动发起的Release。从代理发送ReleaseAck确认主动写回的操作完成。
- B在接收到写回确认前不处理Probe。
- 在从代理接收到B的ProbeAck后,A的事务就可以正常执行了。
TL-C Messages
权限转换新增的三个通道有六个新消息,另外新增了一个通道A消息、三个通道D消息。新的通道是B、C和E,新的消息类型是Acquire、Probe、ProbeAck[Data]、Release[Data]、ReleaseAck、Grant[Data]和GrantAck。
AcquireBlock
AcquireBlock消息是主代理计划在本地缓存数据块的副本时,发起的请求消息类型,主代理还可以使用这种消息类型来升级他们已缓存块上的权限(例如,获得只读副本的写权限),与Get消息一样,Acquire消息本身不包含数据,下表说明了通道A内该消息的信号编码。

AcquirePerm
AcquirePerm消息是主代理计划升级缓存数据块的权限,且无需提供数据副本时,发起的请求消息类型,下表说明了通道A内该消息的信号编码。

ProbeBlock
ProbeBlock消息是从代理用来查询或修改由特定主代理存储的数据块的缓存副本的权限的请求消息,从代理响应另一个主代理的Acquire或主动发起,可以取消主代理对一块缓存块的权限,下表说明了通道B内该消息的信号编码。

ProbePerm
ProbePerm消息是从代理用来查询或修改由特定主代理存储的数据块的缓存副本的权限的请求消息,从代理响应另一个主代理的Acquire或主动发起,可以取消主代理对一块缓存块的权限,不过和ProbeBlock不同的是,ProbePerm要求不需要提供数据副本就可以发起请求,下表说明了通道B内该消息的信号编码。

ProbeAck
ProbeAck消息是主代理用来回复Probe的消息,下表说明了通道C内该消息的信号编码。

ProbeAckData
ProbeAckData消息是主代理使用的响应消息,用于确认接收到Probe,并写回发送请求的从代理所需的脏数据,下表说明了通道C内该消息的信号编码。

Grant
Grant消息是一个响应也是一个请求消息,从代理使用它来确认接收到一个Acquire,并提供访问缓存块的权限给原始发送请求的主代理,下表说明了通道D内该消息的信号编码。

GrantData
GrantData消息既是响应也是请求消息,从代理使用它向原始请求主代理提供确认消息以及数据块副本,下表说明了通道D内该消息的信号编码。

GrantAck
GrantAck响应消息被主代理用来提供事务完成的最终确认消息,同时也被从代理用来确 保操作的全局序列化,下表说明了通道E内该消息的信号编码。

Release
Release消息是主代理用来主动降低其对一个缓存数据块的权限的请求消息,下表说明了通道C内该消息的信号编码。

ReleaseData
ReleaseData消息是主代理发起的请求消息,用于主动降低对一块缓存数据块的权限,并将脏数据写回从代理,下表说明了通道C内该消息的信号编码。

ReleaseAck
ReleaseAck消息是一个从代理发起的响应消息,用来响应Release[Data],用于确保从代理的操作的全局序列化,下表说明了通道D内该消息的信号编码。

TL-UL and TL-UH Messages on Channel A and Channel D
TL-C规定了TL-UL和TL-UH现有消息的权限转换:
- Get操作隐式地将权限Cap为None(Invalid)。
- PutFullData、PutPartialData、ArthmeticData、LogicalData隐式地将权限Cap为非Read+Write(主干或顶点),即None(Invalid)或Read(分支)。
TL-UL and TL-UH messages on B and C
MEEK 代码阅读
NOC部分
参数定义
NOC部分的参数定义在/Hardware/little/subsystem/Configs.scala,然后NOC的全局参数定义在MEEK/Hardware/little/guardiancouncil/GH_GlobalParams.scala
1 | object GH_GlobalParams { |
然后GAGG和GHM参数定义,第一个参数为小核心的个数,第二个参数为发送包的长度,第一个参数就是找到所有tile的最大值,以此获得小核心的个数,注意hartid是从0开始的
1 | case GHMCoreLocated(InSubsystem) => Some(GHMParams(((site(TilesLocated(InSubsystem)).map(_.tileParams.hartId).max+1)-1), GH_GlobalParams.GH_WIDITH_PACKETS)) |
还有GHT参数定义,该参数不使用cde,而是手动输入参数
1 | case class GHTParams( |
GHT_FILTER_PRFS解读
一开始是IO信号以及一些寄存器
指令解码如下,解码完成后送入寄存器寄存
1 | inst := Mux(io.ght_ft_newcommit_in, io.ght_ft_inst_in, 0x0.U) |
解码的同时ght_ft_cfg_in也会送入u_ght_ftable,这个是一个查找表,但目前并不了解这个具体作用
ght的数据从大核传入,主要为配置信息
1 | val u_ght_ftable = Module (new GHT_FTABLE(GHT_FTABLE_Params ())) |
之后读出结果dp_sel和inst_idx,进入大核处理阶段(params.use_prfs=true),首先得出大核的指令类型,然后根据解码的数据发送转发信号,FTQ转发需要是ret指令,prf转发不能是ret指令(ret不写入寄存器)
目前暂时不清楚这个dp_sel如何选择,dp_sel由软件写入,inst_idx同理
1 | io.ght_prfs_forward_ldq := MuxCase(0.U, |
最后就是故障注入,这里采用了fi_counter,fi_counter_tiny来控制故障注入的频率,使用end_of_fi控制注入是否完成,然后fi信号就是故障注入信号,fi_dpx数据就是注入的故障数据
注意:这里必须开启fi_mode才会故障注入
1 | val fi = Mux(incr_fi_counters.asBool && !end_of_fi.asBool && fi_counter_tiny === 31.U, true.B, false.B) |
最后即使根据dp_sel_reg来选择最后的数据包
1 | io.packet_out := MuxCase(0.U, |
这里从new_commit信号开始读出数据,需要两个周期完成数据包送出
第一个周期:GHT_FTABLE读出数据
第二个周期:通过各种选择信号将数据送入io.packet_out
之后该数据会被送入GHM
GH_FIFO
主要解释status_fiveslots为还有五个空位
1 | io.status_fiveslots := Mux(num_contentReg >= ((params.depth).U - 5.U), |
GHT_FILTERS_PRFS
这个模块主要就是连线逻辑
- 连接过滤器
- 入队逻辑
- 出队逻辑
这里主要讲解FSM,FSM启动信号就是buffer有数据,或者rsu_merging,此时进入下一个状态,
考虑fsm_send_first跳转情况,如果ght_stall为false,会跳转到fsm_first_nxt_state,此时主要考虑以下情况:
- buf1有数据,此时跳转到fsm_send_second
- buf1没数据,但buf2有数据,此时跳转到fsm_send_thrid
- buf1,buf2都没数据,buf3有数据,此时跳转到fsm_send_fourth
- 如果都没数据,并且此时不满足buffer有数据,或者rsu_merging,跳转到fsm_reset
这里FSM最多处理四个周期:4-width boom,buf下标从0开始
1 | val fsm_reset :: fsm_send_first :: fsm_send_second :: fsm_send_third :: fsm_send_fourth :: Nil = Enum(5) |
然后就是几个输出信号,core_hang_up就是揭示buffer快满了,或者filter停了
1 | // Outputs |
filter_stall信号是看s_delay_counter_reg是否为0,不为0说明filter空间不够,
s_not_enough_filter_width如果不为1且core_hang_up不为1,说明filter正在输出数据,并且buffer位置充裕,当core_hang_up为1,说明buffer空间不足,这时s_delay_counter_reg不变,也就是等待buffer有空位再递减
这里的意思是检测filter是否有空间,空间不足就需要停止,停止的周期就是s_delay_counter的值
1 | s_num_packets := Cat(zeros_2bits, io.ght_ft_newcommit_in(0)) + Cat(zeros_2bits, io.ght_ft_newcommit_in(1)) + Cat(zeros_2bits, io.ght_ft_newcommit_in(2)) + Cat(zeros_2bits, io.ght_ft_newcommit_in(3)) |
GHT解读
GHT是在大核和小核都部署的部件,
模块例化位置:MEEK/Hardware/big/common/tile.scala和MEEK/Hardware/little/tile/RocketTile.scala
该模块主要讲解之前没有的信号
配置路径如下,通过输入的低三位来说明
目前并不知道cfg传入的是什么cfg是通过GHE解码后传入的信号,cfg_in也就是ROCC指令的rs1的值(a1),cfg_valid也就是解码的指令为CFG指令
1 | val ght_cfg_in_ft_filter = WireInit(0.U(32.W)) |
执行路径主要就是输出转发信号到ldq,stq,ftq
然后就是mapper部分,这里主要就是将shared_CP_CFG解码,下面的代码是对cfg的解码,
同样,shared_CP_CFG并不知道包含什么,且不知道inst_arfs和inst_c是干什么的
shared_CP_CFG从大核传入,inst_arfs最后送入GHM
1 | val u_ght_mapper_arfs = Module (new GHT_MAPPER(GHT_MAPPER_Params(params.totaltypes_of_insts, params.totalnumber_of_ses))) |
之后来到GHT_SE部分,这个部分的输入也用到了cfg_in,首先se首先例化GHT_STABLE,将下面信号做一个寄存(感觉这里可以使用Reg_enable)
1 | val u_ght_stable = Module (new GHT_STABLE(GHT_STABLE_Params ())) |
然后还有一个SCH部分,这里个人目前理解c后缀的代表commit,core_s代表checker 的id,core_d代表目的checker
这个的功能就是得出目的checker的id?然后io.cpuna没有用到
注意,这里io.sch_hang始终为0
1 | val u_sch_p = Module (new GHT_SCH_PIN(GHT_SCH_Params (params.totalnumber_of_checkers))) |
再回到GHT,Scheduler Engines得到core_d_all,core_d_all_arfs,也就是调度的core id
注意,这里的sch_hang总是为0
然后到AGG Configuration,这里也是用到了ght_cfg_in
GHT在大核的作用
下面的核心信号只要是bridge出去的信号都和cmdrounter有关,其他信号使用了diplomacy的Node
目前暂时还没看cmdrounter,数据全部从cmd_counter传入
为什么大核送入GHT的rsu_merging为0
1 | ght.io.ght_mask_in := (ght_bridge.io.out | (!if_correct_process_bridge.io.out)) |
核心信号连接,主要连接了从大核来的pc_addr,inst,commit信号。以及alu数据
1 | for (w <- 0 until gc_core_width) { |
GHE
接下来解读rocc,因为大核内部除了GHT就是rocc和cmdcounter连接,rocc实际上为GHE,GHE主要就是解码器,对输入的ROCC指令解码
首先要明确ROCC指令的格式
GHE的作用类似于中间层,去处理rocc指令,然后通过cmdrounter路由
rocc指令
1 | #define CUSTOMX(X, xd, xs1, xs2, rd, rs1, rs2, funct) \ |
rd,rs1,rs2分别代表目的寄存器,源寄存器1,源寄存器2的标号,xd,xs1,xs2分别代表是否使用这些寄存器,然后funct指示了func,最后还有X(op_code),指示指令属于custom_x
之后分别解读各个信号:
下面的解释将LW作为读取作用的指令(含有rd的),
doCheck:funct为0x00,在软件中为ghe_status
doSorR: funct为0x1,在软件中为ghe_asR,ghe_asG
doEvent: (funct ===0x40.U) || (funct ===0x41.U) || (funct ===0x42.U) || (funct ===0x43.U),在软件中分别为ghe_go,ghe_complete,ghe_release,0x42暂时没有找到
doCheckBigStatus:funct为0x07,为LW,在软件中为ghe_checkght_status
doCheckAgg:funct为0x10,为LW,在软件中为ghe_agg_status:
doInitialised:funct为0x50||0x51,软件中为ghe_initailised,这个函数有一个if_initailised输入,来选择执行funct为0x50的指令还是0x51的指令
doCopy:funct为0x60,并未找到0x60的函数
doCheckRSU:funct为0x61,软件中为ghe_rsur_status
1 | // 0b00: idle |
doDeqELU:funct为0x63,软件中没有这个
doRecordPC:funct为0x64,软件中没有
doCoreTrace:funct为0x69,软件中没有
好像只是没有封装为函数
doBigCheckComp:funct为0x06,软件中很多0x6的
1 | ght_get_status:LW |
doMask:满足的软件函数很多 funct 从0x30-0x38
0x30-0x34:ght_set_status,通过输入index选择执行不同的指令,其他暂时没有实现
doCritical:0x39:暂时没有找到
doCheckCritial:0x49,暂时没有找到
doPID_Cfg:0x16,软件中为ght_set_satp_priv,ght_unset_satp_priv
doGHT_Cfg:0x06并且rs2_val==2||3||4,软件中对应的是
1 | ght_cfg_filter |
doGHTBufferCheck:0x08,为LW,软件中为ght_get_buffer_status
doBigCheckIni:0x1b,为LW,软件中为ght_get_initialisation
doSetActivatedCheckers:0x1c,软件中为ght_set_numberofcheckers
doDebug_bp_checker:0x1d,为LW,软件中为debug_bp_checker
doDebug_bp_cdc:0x1e,为LW,软件中为debug_bp_cdc
doDebug_bp_filter:0x1f,为LW,软件中为debug_bp_filter
doDebug_Reset_bp:0x2d,软件中为debug_bp_reset
doICCTRL
doSetTValue
doStoreFromChecker
doStoreFromMain
doRecord
上面的均未使用函数封装
doPerfCtrl:funct为0x76,软件中为ghe_perf_ctrl
doPerfRead:0x77,LW,软件中为ghe_perf_read
rd写入
下面介绍需要写入rd的操作
首先是doCheck,写回值为Cat(channel_full, channel_empty),2-bits
1 | // 0b01: empty; |
doCheckBigStatus,写回值为ghe_status_in,从GHM传入
doCheckAgg,写回值为Cat(zeros_62bits, io.agg_buffer_full, zeros_1bit),
此处只会检查full,但不检查error
1 | // 0b01: empty; |
doBigCheckComp,写回值为Cat(bigComp, rs1_val(15, 0)),bigComp为ghm传入,rs1_val为寄存器读出
doBigCheckIni,写回值为bigInialised,该信号为ghm传入
doGHTBufferCheck:写回值为Cat(zeros_62bits, io.ght_buffer_status),该信号为ght传入
doCheckCritial:写回值为ght_critial_reg(也就是rs1_val(1,0)的寄存器)
doCheckRSU:写回值为Cat(io.rsu_status_in, zeros_3bit),从rocketchip传入
doDebug_bp_checker:写回值为io.debug_bp_checker,从ght传入
doDebug_bp_checker -> io.debug_bp_checker,
doDebug_bp_cdc -> io.debug_bp_cdc,
doDebug_bp_filter -> io.debug_bp_filter,
这三个和上面同理
doPerfRead写回值来自io.elu_data_in(63,0),由Boom传入
1 | rd_val := MuxCase(0.U, |
输出信号
ghe_event_out:Cat(0.U, ghe_initialised_reg, ghe_event_reg, channel_warning),传输了ghe_initialised_reg,ghe_event_reg,这两条信息分别与doInitialised和doEvent有关
ght_mask_out:~(ght_status_reg(0)),与doMask有关
ght_status_out:Cat(0.U, num_activated_cores, ght_status_reg(22,0)),与doSetActivatedCheckers和doMask有关
ght_cfg_out,ght_cfg_valid:Mux(doGHT_Cfg, rs1_val(31,0), 0.U),Mux(doGHT_Cfg, 1.U, 0.U),与doGHT_Cfg有关
debug_bp_reset:Mux(doDebug_Reset_bp, 1.U, 0.U),与doDebug_Reset_bp有关
agg_packet_out,report_fi_detection_out,agg_core_status_out,ght_sch_na_out,fi_sel_out:与输入直连
ght_sch_na:channel_sch_na:控制信号由channel_nearfull和ght_sch_refresh(GHM传入)控制
ght_sch_dorefresh:恒为0
if_correct_process:Mux((define_monitor_target ===1.U), 1.U, (hit_satp_ppn & hit_privi & has_monitor_target))
1 | define_monitor_target := Mux((doPID_Cfg && (rs1_val === 1.U)), 1.U, 0.U) |
t_value_out:t_Value和doSetTValue有关
RoccCommandRouterBoom也就是cmdrounter,内部加入了MEEK的信号,目前暂时不知道这些信号含义
目前该模块虽然得知各个信号代表什么,但怎莫用,如何去用还需研究
GHM
ghm和gagg都是在顶层定义的,然后在这个文件中定义了GBUS,MEEK/Hardware/little/subsystem/BusTopology.scala,主要用于外设的访问
文件位置:MEEK/Hardware/top/System.scala中的ChipyardSystem
其中DigitalTop继承了这个类
GHM主要就是将大核数据送入小核
NOC节点定义与连接
位于MEEK/Hardware/little/subsystem/HasTiles,主要在该trait定义了Ephemeral节点,且指定了数据类型,然后这个trait只能被BaseSubsystem或者其子类继承
1 | trait HasGHnodes extends InstantiatesTiles { this: BaseSubsystem => |
这里是trait CanAttachTile内部的一个连接函数,主要作用是将tile信号传送到总线上,并且经过跨时钟域处理
1 |
|
大核流程
大核首先将rocc的cmd送入rocc,rocc模块处理完成后会将处理完成的信号送入cmdrouter,
1 | rocc.module.io.cmd <> cmdRouter.io.out(i) |
大核会去和ght以及ghe交互
大核和rocc
GHE与GHT交互信号
只要是rocc指令,均为GHE传入
然后与GHT有关的信号会送入GHT处理,具体的
ght_mask_in:rocc指令
use_fi_mode:rocc指令
ght_cfg_in:rocc指令中rs1的值
ght_cfg_valid:rocc指令中rs1的(1,0)
debug_bp_reset:rocc指令
if_correct_process:相对比较复杂的ROCC指令
ght_buffer_status:看ght buf的空满,2 bit 信号,其中高位为1是满,低位为1是空
debug_mcounter:debug_icounter:没有找到任何实现,且在GHT赋值为0
debug_bp_checker:由软件读出
debug_bp_cdc:同由软件读出
debug_bp_filter:同
大核与GHT交互信号
主要获取核的状态:pc,inst,commit,alu
是否prfs_rd,是否为rvc
解释ght是否准备好
1 | for (w <- 0 until gc_core_width) { |
大核与GHE交互
i说明是输入core的信号
o说明是输出core的信号
icctrl:i :rocc指令,输出值为rs1(3,0)
t_value:i:rocc指令,输出值为rs1(14,0)
if_correct_process:i:rocc:该信号同时也会传入GHT
num_of_checker:i:rocc:GHE的ght_status_out(30,23)
debug_perf_ctrl:i:rocc:rs1(4,0)
core.io.ptw.ptbr.ppn:o:rocc,GHE的ght_satp_ppn信号,和GHE的if_correct_process信号有关
core.io.ght_prv:o:rocc,GHE的ght_sys_mode信号,和上面一个信号共同影响if_correct_process
debug_perf_val:o:rocc,GHE的elu_data_in信号,软件读出
大核与GHM交互
clear_ic_status_tomain:i:GHM的clear_ic_status_tomain信号,从小核的clear_ic_status传入
icsl_na:i:GHM的icsl_na信号,从小核lsl_highwatermark传入
ic_counter:o:在ghm中连接如下,最后连接到小核的ic_counter
1 | for (i <- 0 to params.number_of_little_cores - 1) { |
debug_maincore_status:o,在GHM对应信号为debug_maincore_status,和上面信号同时组成了icsl_counter
GHM与GHE交互
ghe_packet_in:ghe_status_ini:ghm的ghm_packet_outs信号,大核不连接GHE,也就是大核不接受ghe数据,大核只发出数据
ght_status_out:o:在GHM中为ghm_status_in
agg_packet_out:一直送入GAGG的agg_packet_in,大核没有使用
bigcore_comp:i:为GHM的传入bigcore_comp
ght_sch_dorefresh_out:大核没有使用
GHT与GHM,GAGG交互
ght_packet_out:o:送入GHM的信号就是packet ghm_packet_in
Cat(ght.io.arfs_dest, ght.io.ght_packet_dest):送入GHM为ghm_packet_dest信号
ghm_agg_core_id:o:ghm_agg_core_id_SKNode:送入GAGG的信号为agg_core_id
debug_bp:i:在GHM信号为debug_bp
ght_stall:i:在GHM中信号为bigcore_hang
总结
大核的命令先送入GHE处理,然后根据GHE来展开接下来的操作,首先,大核的数据会送入GHT,GHT首先过滤请求,加工数据(与ic_crnt_target和cfg有关),并且向大核发出forward请求,然后处理完数据后,送入GHM,经过CDC送入小核
小核心流程
小核心与GHE交互
arfs_if_CPS:i:所以该信号需要s_or_r以及arfs_in:
首先为s_or_r,为GHE的s_or_r_out传入
arfs_in:i:由GHM的core_r_arfs_c传入
packet_arfs:i:由下面代码看到这个信号和arfs_if_CPS类似
packet_lsl:i:该信号的组成为s_or_r,+GHM的ghm_packet_outs信号,该信号也就是从大核经CDC传入的数据
packet_lsl1:i:该信号和上面类似
arf_copy_in:i:从GHE传入的arf_copy_out
s_or_r:i:为GHE的s_or_r_out传入
if_correct_process:i:GHE传入的if_correct_process
record_pc:i:GHE传入record_pc
elu_deq:i:GHE传入的elu_deq_out
elu_sel:i:GHE传入的elu_sel_out
debug_perf_ctrl:i:debug_perf_ctrl
record_and_store:i:record_and_store_out
rsu_status:o;rsu_status_in:软件读出
elu_status:o;GHE并未找到使用
core_trace:i:core_trace_out
ptw.ptbr.ppn:o;
ght_prv:o;
上面两个信号共同影响if_correct_process
elu_data:o;elu_data_in:由软件读取
1 | val packet_in_superset = outer.ghe_packet_in_SKNode.bundle |
小核心与GHM,GAGG交互
本节不介绍前一节介绍过的
首先介绍下面两个:
1.送入GHM的信号为ghe_event_in
2.送入GHM的信号为ghe_revent_in
1 | outer.ghe_event_out_SRNode.bundle := Cat(cdc_ack, (ghe_bridge.io.out | Cat(core.io.packet_cdc_ready, zeros_4bits) | Cat(zeros_4bits, core.io.lsl_near_full))) |
ic_counter:i:icsl_counter:GHM
clear_ic_status:o;clear_ic_status:GHM
GHE与GHM,GAGG交互
GHE信号:(i or o):GHM or GAGG
ghe_status_in:i:ghm_status_outs:该信号需要软件读出
ght_status_out:o;ghm_status_in
agg_packet_out:在GHE中赋值为0
report_fi_detection_out:未在小核心使用
agg_buffer_full:i:agg_buffer_full:软件读取
agg_core_status:o;agg_core_status,注意该信号还使用到了其他模块的信号
1 | outer.agg_core_status_SRNode.bundle := Mux(!s_or_r.asBool, cmdRouter.get.io.agg_core_status_out, core.io.icsl_status) |
ght_sch_na:o;sch_na_in
ght_sch_refresh:i:sch_refresh_out
ght_buffer_status:恒为0,软件读取
总结
小核心接受从GHM传入的数据包,根据GHE的指令来选择对应的操作
软件执行流程
以TC_OverTaking为例子,大核首先执行r_ini,进行初始化,首先设置小核心数目,ght_set_numberofcheckers(num_checkers);当大核心执行这条ROCC指令,cmd送入GHE,然后GHE将信息通过ght_status_out送出,然后num core会送入大核内,还会有一部分传入GHM,
然后会执行ght_cfg_filter
参数有index,func,opcode以及sel_d,大核执行完ROCC指令会将s1送出GHE,之后会送入GHT,如果rs1的(3,0)==2,说明是filter配置,送入GHT_filter,然后congruentFTABLE,之后运行的指令都会去查询这个表,得出dp_sel
然后之后会执行ght_cfg_se,
hart0执行main 以及hart1执行_main可以在libgloss内找到
小核心在此时会去执行checker,具体的:
首先去执行ghe_asR,然后会在GHE解码得到s_or_r_out(rs1(1,0)),该信号会送入core,且会控制其他的信号
之后会去执行ght_set_satp_priv,该函数进入GHE为doPID_Cfg,设置当前的ppn以及mode,然后还会去发出if_correct_process送入小核心
执行ghe_go,该函数在GHE对应doEvent,然后会将funct写入寄存器ghe_event_reg
执行ghe_initailised,该函数在GHE对应doInitialised,会将funct写入ghe_initialised_reg寄存器
执行ghe_perf_ctrl,在GHE对应debug_perf_ctrl,将rs1的前4位写入,最后送入核内
执行下列指令
ROCC_INSTRUCTION (1, 0x75); // Record context
ROCC_INSTRUCTION (1, 0x73); // Store context from main core
ROCC_INSTRUCTION (1, 0x64); // Record PC
这三个信号在仿真阶段被优化了
大核部分
大核的数据传输主要在LSQ,ROB,FTQ,以及prf和csr
LSU部分
LSU直接读HAED部分的数据,head总是最近提交的数据
1 | //===== GuardianCouncil Function: Start ====// |
FTQ部分
入队信号
1 | val gh_ftq_idx = Input(Vec(coreWidth, UInt(log2Ceil(ftqSz).W))) |
该部分信号全部被优化掉
ROB部分
信号定义
1 | //===== GuardianCouncil Function: Start ====// |
其中gh_stall可以将rob停止提交,can_commit_withoutGC为原始的commit信号,
r_next_pc为指令的pc,这里使用的是uop的debug_pc
gh_effective_alu_out会输出jmp指令的target
这里有个疑问,为什么需要输出jmp指令的target
core部分
信号定义
1 | //===== GuardianCouncil Function: Start ====// |
该部分的输出信号均来自commit阶段,读取prf是加入了corewidth个读端口去读出数据
这个算是运行时数据,为何要记录
1 | //===== GuardianCouncil Function: Start ====// |
ght_prv从csr读出系统的mode状态
ic_incr,指出本周期提交指令个数,然后arfs和farfs分别记录int和fp寄存器堆的状态
1 | val ic_incr = arch_valids_extended.reduce(_ + _) |
R_IC模块解读
信号定义
ic_run_isax,ic_exit_isax,ic_syscall,ic_syscall_back均与icctrl有关,该控制信号由rocc读入
core_trace信号也由ROCC传入
1 | val ic_run_isax = Input(UInt(1.W)) |
R_IC主体为一个状态机
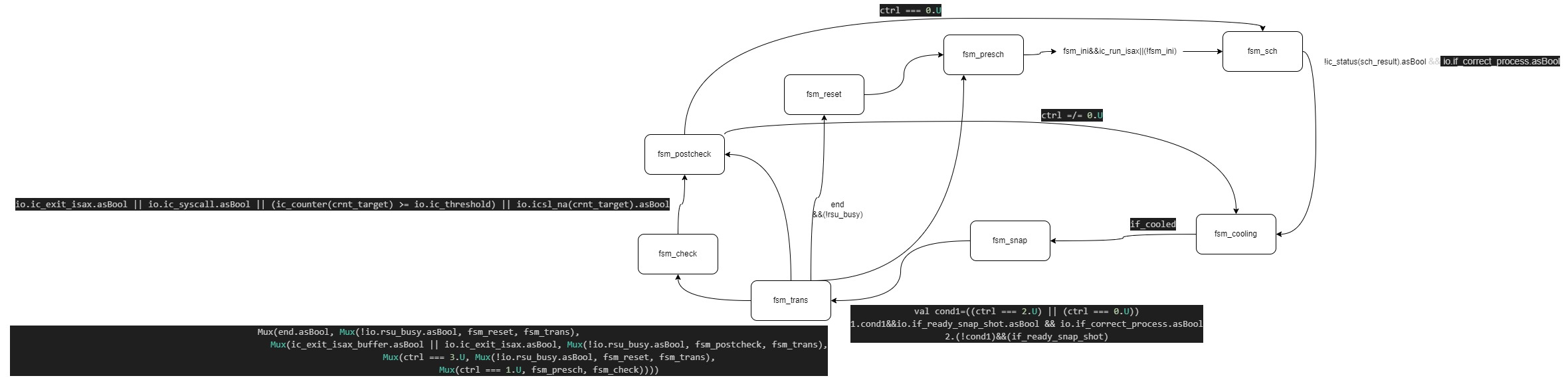
1 | val fsm_reset :: fsm_presch :: fsm_sch :: fsm_cooling :: fsm_snap :: fsm_trans :: fsm_check :: fsm_postcheck :: Nil = Enum(8) |
- 定义了 8 个状态:
fsm_reset:复位状态。fsm_presch:预调度状态。fsm_sch:调度状态。fsm_cooling:冷却状态。fsm_snap:快照状态。fsm_trans:转换状态。fsm_check:检查状态。fsm_postcheck:后检查状态。
a. fsm_reset
1 | is (fsm_reset) { |
- 功能 :初始化所有寄存器和状态。
- 状态转移 :进入
fsm_presch状态。
b. fsm_presch
1 | is (fsm_presch) { |
- 功能 :
- 重置流水线停滞标志。
- 根据
io.ic_run_isax决定是否进入调度状态。 - 状态转移 :如果
io.ic_run_isax有效,进入fsm_sch,否则保持当前状态。
c. fsm_sch
1 | is (fsm_sch) { |
- 功能 :
- 更新目标核心
nxt_target。 - 根据
io.if_correct_process和核心状态决定状态转移。 - 状态转移 :
- 如果
sch_result的状态为空闲且io.if_correct_process有效,进入fsm_cooling。 - 否则保持当前状态。
d. fsm_cooling
is (fsm_cooling) {
- 功能 :
- 如果冷却完成,进入快照状态。
- 否则保持冷却状态。
- 状态转移 :进入
fsm_snap。
e. fsm_snap
1 | is (fsm_snap) { |
- 功能 :
- 根据控制信号
ctrl和io.if_ready_snap_shot决定下一步操作。 - 更新核心状态。,此时会选择检查核心,然后置高ic_status
- 状态转移 :进入
fsm_trans。
f. fsm_trans
1 | is (fsm_trans) { |
- 功能 :
- 根据
end和io.rsu_busy决定是否复位。 - 根据
ic_exit_isax_buffer和io.ic_exit_isax决定状态转移。 - 状态转移 :
- 如果
end有效,且io.rsu_busy无效,进入fsm_reset。 - 否则保持当前状态。
g. fsm_check
1 | is (fsm_check) { |
- 功能 :
- 更新控制信号
ctrl。 - 根据条件更新过滤标志和流水线停滞。
- 更新核心计数器。
- 状态转移 :
- 如果满足退出条件,进入
fsm_postcheck。(system call,指令達到阈值,小核心lsl满了) - 否则保持当前状态。
在该阶段有三个退出check的条件
h. fsm_postcheck
1 | is (fsm_postcheck) { |
- 功能 :
- 更新核心计数器。
- 根据控制信号
ctrl决定状态转移。 - 状态转移 :
- 如果
ctrl === 0.U,进入fsm_sch。 - 否则进入
fsm_cooling。
输出信号
crnt_target:为crnt_mask,只有在fsm_snap阶段才会赋值为Cat(ctrl, crnt_target)
if_pipeline_stall:该信号可以停止ROB提交,在fsm_check阶段会去根据三个条件置为高,其他阶段均和if_correct_process有关(除reset)
if_dosnap:快照信号
ic_counter:计数提交的指令
ic_status:正在运行核心的状态
shared_CP_CFG:Cat(one, cp_bitmap, core_bitmap),这个个人理解就是得出现在调度核与下一个要调度的核心
R_RSU解读
RSU主要作用就是去维护一个快照状态
记录快照状态
1 | when (doSnapshot === 1.U) { |
merge逻辑
主要看merge_counter,该cnt指示要去传什么idx的arf,0-31传fp和int寄存器,32传pc和fcsr
1 | if (GH_GlobalParams.IF_THERE_IS_CDC){ |
在merge期间需要置高core_hang_up
rsu_bsy揭示了rsu的忙状态
core与rsu,ic交互
core与rsu和ic交互主要就是stall信号,两模块均可阻塞rob提交,其他信号就是来自外部的配置信号,以及送入外部的配置信号
小核部分
信号定义
1 | val arfs_if_CPS = UInt(1.W).asInput |
new_commit使用的是从csr来的valid,实际上也是wb阶段的valid经过处理得到的
1 | io.pc := wb_reg_pc |
R_RSUSL解读
信号定义
1 | val arfs_out = Output(UInt(params.xLen.W)) |
packet入队逻辑
当if_RSU_packet信号为高,说明有有效的packge,此时接授arfs和farfs,同时告诉外界开始接受snapshot(starting_CPS),并且将snapshot信息写入arfs_ss和farfs_ss,注意pc是最后一个包
1 | if_RSU_packet := Mux(io.arfs_if_ARFS.asBool && io.arfs_if_CPS.asBool, 1.U, 0.U) |
保存checker状态
record_and_store信号来自ROCC,该保存状态逻辑和之前大核类似,只不过将寄存器堆变为了sram
1 | when (io.record_context.asBool && !recording_context) { |
应用snapshot状态
通过设置计数器来达到每周期恢复2个寄存器(int,fp),paste_arfs来自ROCC指令
1 | apply_snapshot_memdelay := apply_snapshot |
输出检查信号
该模块根据do_cp_check置高检查do_check,之后根据checking_counter_memdelay来输出if_cp_check_completed,同时当RSU工作时需要停止core,该信号送入icsl
1 | // Faking ELU data |
R_ICSL解读
FSM转化条件
从 fsm_reset 到 fsm_nonchecking :
初始化所有寄存器。
设置 clear_ic_status 为 1。
设置 icsl_checkermode 为 0。
设置 if_rh_cp_pc 为 0。
转移到 fsm_nonchecking 状态。
从 fsm_nonchecking 到 fsm_checking :
如果 icsl_run 有效,转移到 fsm_checking 状态。
否则保持在 fsm_nonchecking 状态。
从 fsm_checking 到 fsm_postchecking :
如果 if_instants_completion 或 if_slow_completion 有效,并且 something_inflight 无效,转移到 fsm_postchecking 状态。
否则保持在 fsm_checking 状态。
从 fsm_postchecking 到 fsm_reset :
如果 returned_to_special_address_valid 有效,转移到 fsm_reset 状态。
否则保持在 fsm_postchecking 状态。
在checking阶段,sl_counter会根据提交指令增加,当sl_counter>=ic_counter_shadow,说明完成该代码段的执行if_instants_completion,
这里给出了检查完成信号,
1 | val if_instants_completion = Mux((io.if_correct_process.asBool && io.new_commit.asBool && ((sl_counter + 1.U) >= ic_counter_shadow) && ic_counter_done.asBool), 1.U, 0.U) |
当在fsm_postchecking状态,if_rh_cp_pc置高,表示完成执行,如果此时returned_to_special_address_valid为高,也就是执行最后一条返回指令,此时完成检查整个流程
输出信号介绍
icsl_if_ret_special_pc:当rsu发出完成检查信号并且目前位于checkmode,此时发出icsl_if_ret_special_pc信号,表示icache下一次取指令的为pc_special
if_rh_cp_pc:表示完成检查,准备返回
icsl_stalld:停止流水线,这个主要在检查后阶段执行
if_overtaking:这个信号个人理解是杀去一些div和fpu指令
然后该阶段设置了一系列性能计数器
1 | ic_counter_shadow := io.ic_counter(params.width_of_ic-2,0) + 1.U // The checker core requires to run one more insts due to the custom jump |
R_LSL解读
ldst入队
入队信号如下,我们保证两个通道的fifo数据量一样,所以设置scala_ptr,该信号当来2笔数据时值不变,只有来1笔数据值才会改变,
scala_num_reqs为送入的数据数目
scala_ptr指示要写入哪个fifo
然后channel_enq_valid只有在有数据送入,如果scala_num_reqs为2,两个channel的enqvalid均为高,若为1,只有在scala_ptr=0时才会去置高,enq_data同样如此
1 | has_data := io.m_st_valid.asBool || io.m_ld_valid.asBool || io.m_st_valid1.asBool || io.m_ld_valid1.asBool |
ldst出队
出队逻辑同样含scala_ptr_core,不过由于小核心为标量,故每次最多传输1笔
if_lsl_empty根据scala_ptr_core值来选择输出哪个channel
resp_data和resp_addr根据scala_ptr_core选取对应的channel,最后的replay信号发生在输入有效但lsl没数据,输入有效,但该请求被kill
channel_deq_ready信号根据scala_ptr_core设置ready信号,前提lsl不能为空并且req_kill不为高
最后ld_deq,st_deq根据cahnnel和cmde是否置高
1 | val if_lsl_empty = Mux(scala_ptr_core === 0.U, channel_empty, channel_empty1) |
CSR入队出队和LDST类似,故不作解释
最后会输出LDST的channel是否满了,只有当四个CHANNEL全部为空,这时候if_empty才为空
1 | io.resp_data_csr := Mux((scala_ptr_core_csr === 0.U), csr_channel_deq_data, csr_channel_deq_data1) |
其中lsl_highwatermark,lsl_near_full最终会送往大核,来指示LSL状态
R_ELU解读
该模块主要就是检查ld和st是否错误,对于ld,只需检查地址,而st需要检查地址和数据
1 | err_ld := Mux(ld_valid && (req_addr_reg(11,0) =/= io.lsl_resp_addr(11,0)), true.B, false.B) |
如果发生错误,会将错误信息写入fifo
1 | err_log_ld := Cat(io.wb_pc, resp_data_wire, useless_ones, io.lsl_resp_addr, req_addr_reg) // load data is not compared |
最后FIFO的出队逻辑elu_deq来自软件的ROCC指令
这里的elu_data和elu_status都没使用,elu_status传入了GHE但没使用
检测到错误如何进行之后操作
数据传输源码修改部分
大核:
MEEK/Hardware/big/common/tile.scala
MEEK/Hardware/big/exu/core.scala
MEEK/Hardware/big/exu/rob.scala
MEEK/Hardware/big/ifu/fetch-target-queue.scala
MEEK/Hardware/big/lsu/lsu.scala
top:
MEEK/Hardware/top/System.scala
MEEK/Hardware/top/CustomBusTopologies.scala
MEEK/chipyard/generators/chipyard/src/main/scala/Subsystem.scala
MEEK/Hardware/top/config/RocketConfigs.scala
小核:
MEEK/Hardware/little/tile/BaseTile.scala
MEEK/Hardware/little/rocket/RocketCore.scala
MEEK/Hardware/little/rocket/CSR.scala
MEEK/Hardware/little/r
MEEK/Hardware/little/guardiancouncil
MEEK/Hardware/little/subsystem/HasTiles.scala
MEEK/Hardware/little/tile/RocketTile.scala
MEEK/Hardware/little/tile/LazyRoCC.scala
MEEK/Hardware/little/subsystem/BusTopology.scala
MEEK/chipyard/generators/rocket-chip/src/main/scala/subsystem/Configs.scala
在移植过程中,会有很多目前不兼容的case,不过都可以通过报错的backtrace解决
随笔
发现PRF大核传输不是用的CDC而是直接node传过去的
- 需要做CDC,考虑和load store一个通道(+所有控制信号都得CDC),做CDC转换时,需要去考虑控制信号的延迟问题,
prf传输是独立的,只有在prf传输完成,才可以进行校验,在这个期间大核仍然可以提交指令,但不会在小核心执行
- GHT_filter需要去做参数化,并且入队逻辑和出队逻辑需要优化
- snapshot记录的PC是rocc指令 go的PC,是否需要去给出下一个PC?(+4?)
ght——filter要做的事情就是将大核心commit的数据每个周期传输一个包,但可能有的buffer没有有效包,这里的设计和ibuf理念仍然一样:
有n个不定的输入,1个输出,如何去输出数据
GHT的rsu_merging是否真正有用?外部被置为0,ght_filters_ready也没用到
ght_debug_filter_width什么意思?会导致大核暂停
CDC反压会导致调度混乱,系统卡死,需要在GHT作出对应反压信号的,cdc反压,GHT不能读出数据,个人设计错误
CDC入队条件比较弱,考虑更改
新的buf前端卡死了,GHT 的buf位宽比较混乱,需要修正位宽
寄存器传输需要多8bit,因为需要状态位+idx
- 小核心tile只判断了低半部分ptype_fg
这里每次传输都是2个包,所以可以只判断低位
- 小核心使用的Chisel,考虑将chisel换为chisel3,旧版本不会检查未初始化的输出信号
- cdc ready 条件比较弱?
目前可配置数据可以泡通,但是时间比之前长,具体就是csr的lsl经常满,(相对之前来说,可能是CDC少打了一拍?)
- 目前lsl高水位设置比较保守?是否去修改
- csr 存在带宽浪费?
- 有一个大问题,即使我设计出错,也会跑完整个流程,是否需要加入difftest
性能计数器如何添加?
1.延迟如何计算?
2.slowdown如何计算?
3.数据吞吐如何添加?
只要进入checkmode,就记录cycle?然后记录发出的包?
但只有ldst才会存入这个包?
对于数据输入:大核可以统计ld和stcommit的数据,也就是包的总数,但CDC只要ready就可以发送?
从哪个时间开始测试:
这些性能事件可以通过csr直接读取
- CDC跨时钟域的复位如何解决?
- 各个tile的复位是一起复位的吗?,需要去协调每个tile的reset和clock(如果四个rocket是同步时钟,那么不需要去协调?)
一种设计思路:根据此次调度来存入不同的CDC FIFO
假设4个CDC FIFO:每个CDC入队时钟域为boom的时钟域,出队时钟域为各个rocket的时钟域,入队时根据不同的调度信息写入不同的FIFO
如果这样做:
- if_no_inflight_packets依据CDC FIFO是否为空设置,这个如何去解决?
- CDC FIFO并未直接引入 empty和full,且异步fifo的空满信号和同步的判断不太一致
- CDC 后端的ready信号如何设置
CDC路线:
1.先对数据信号CDC
2.在对控制信号CDC
3.重新整理入队出队信号
- 目前dest信号从GHT中取得,实际可以直接从RIC取出,节省了逻辑
LSL的high——water会导致大核调度下一个核心,也是小核心无法接受数据的信号
下游何时可以接受数据:
1.调度信号为该核心,
下游如何去打断上游?
下游送入high water时,已经是两个周期后,此事CDC模块可能被写入了数据,这个如何解决?
小核心送入的控制信号必须为单周期信号
CDC需要考虑的情况
数据传输:
全部得反压,且目前设置的不可配置
小核心切换:
情况1:
1.小核心lsl将近满
2.此时小核心通过该CDC将控制信号传入大核心,(这里会延迟几个周期(CDC必须消耗的周期),所以可能导致这个真空期会有大核数据存入CDC FIFO)
3.大核接收到high water信号,准备切换checker和状态,切换完成向小核心发出ack(为了将真空期写入的数据读出)
- 这里有一个问题是:大核发出的icsl_na_ack可能会因为FIFO满而导致写入失败,(反压?)
4.ack信号经过CDC传入小核心,此时小核心会去检查CDC FIFO是否有数据(也即是真空期大核是否写入数据),如果有数据,需要读完这些数据,没数据可以直接进入postcheck,然后清空ic_status,向大核发出clear_ic_status请求
这种做法会导致小核心状态延迟被消除,这个是因为CDC引入了真空期
需要注意的是,小核心的cdc_ready需要和high water区分,至少留出余量,防止真空期写满导致数据丢失,(好像这里不用做出区分,如果满了,CDC FIFO会暂存),还有一个可能不常见的情况:CDC也满了,这样会导致数据丢失?
- 如果CDC的写入端valid但并未ready,说明FIFO满,此时会发生错误,这时候好像只需要不让大核的R IC模块状态停止转换就可以?(必须要考虑的情况)
小核心检查cdc是否空时,有没有可能出现假空?
不大可能:大核心的ack传入小核心需要CDC,此时如果之前有数据写入,数据CDC FIFO已经读到正确的idx了(写指针已经同步到读端口),所以不会出现问题
最新做法:
小核心lsl满可以向大核心发出反压信号,大核心收到信号后会去停止执行,然后直接发送ic_cnt回来,小核心只需要执行到这个ic cnt就可以退出这个模式了
情况2:
1.小核心执行到目的的指令数目,和来自大核的ic_cnt对比,此时也会有真空期(大核的ic_cnt仍然在计数)
2.然后对比完成,转换状态,给出大核清除信号,大核此时去清除ic_status,注意此时大核可能执行的指令已经超过指令阈值,所以可能发生状态切换,导致错误
解决办法
1.所以小核心不应该去做ic_cnt对比,需要当大核心指令超过阈值,向小核心发出信号,小核心读取到信号后,需要对大核心的信号做出回应,执行完所有指令(cdc fifo空,lsl空,且pipeline无指令),然后大核心接到回应后切换状态,这样就可以去除CDC造成的真空期
- 但是这样做的话:如果小核心执行超过大核心,大核心无法感知到
2.继续原来的做法,也就是向小核心送入大核的cnt,然后根据这个cnt来得到stall(由于cdc存在延迟,所以不会出现问题),当大核心达到阈值的时候,向小核心发出done,此时小核心得到done(延迟几个周期,但不会出现问题),执行完成后,向大核发出clear
此时大核可能已经开始执行指令,但是不会出问题:
因为每个ic_status和cnt是独立的
- ic counter done的信号需要去维持,(不需要)
同理,大核心发生ecall,执行退出命令,也是这样的做法
也就是checker切换分为两种情况:
1.小核心lsl满,此时的CDC造成的真空期不可忽视,必须为小核心的LSL留出一定余量(其实也可以不用,反正都存在CDC FIFO),小核心执行完成后才会向大核心发出clear_status请求
2.其他情况,均和大核的执行状态有关,大核需要去向小核发出终止信号,小核心读取到信号必须向大核心信号做出回应,大核接受到回应才会去切换状态,改情况无真空期,但如果采用做法2,其实可以和1归为1类,和情况1的区别就是没有真空期
为什么需要对控制信号留出余量(depth>3)?
大核心写的太快,此时小核心读的慢,导致控制信号丢失,所以必须去暂存控制信号
必须反压或者采样
为什么控制信号不连续(主要出现在l2b)?
小核心写入太慢,大核心读取太快,导致FIFO经常空
-
需要增加FIFO深度,具体需要根据时钟频率考虑
这里也导致一个问题,控制信号不连续,需要做出对应处理?
1.为控制信号加入valid,只有fire的信号才是真正的控制信号
2.传输的控制信号必须要是单周期的信号,这样读出的信号才会是单周期的,否则可能出现不连续的情况,但是某些信号本来就不是单周期的,比如lsl high water
小核心的icsl状态转换处理?
当lsl满的时候,小核心需要去进入一个新的状态,也就是cdc_clear状态,当收到ack转换到该状态,然后如果cdc空了,且流水线执行完成,进入下一个状态)
其他情况时,(大核发生的事件导致小核心去切换),此时也要进入cdc_clear,cdc空后,且流水线执行完成,进入下一个状态
cdc_clear,也算是check状态,他的作用就是把CDC转化的真空期数据清空
为什么csr lsl满的很快?
- 必须对快时钟域的信号采样,否则fifo必满,但是如果采样的话,大核心的ic_cnt就不再准确,所以必须反压
解决方法:
当小核心执行到最后一条指令时,停止执行,看大核心是否已经完成这个的执行,如果完成执行,向小核心发出信号,然后小核心完成执行
目前需要解决的问题:
- 大核控制信号反压(高优先级),目前暂时不用。控制信号很零散
- 小核心控制信号反压(高优先级)。目前暂时不用。控制信号不会反压
- 大核arfs反压(高优先级)
- 小核最后一条指令停止执行(可能之后还要执行其他的指令),仍然需要小核心去维护一个cnt,只不过这个cnt仅仅去计数,等到cnt为设置的阈值-1时,这时候去停止小核心执行,然后询问大核心情况,大核如果此时执行完成,向小核心发送信号(目前只是完成coding,但是无法去验证正确)
目前通过overtaking重新去重启取pc
CDC FIFO 只采样控制信号的高电平(高电平写入)小核心的信号只在小核心计算,然后结果传到大核心,(一些debug信号)(低优先级)
需要传输ic——cnt:大核提交指令不定,可能超过阈值,所以当收到请求后,需要传入大核的cnt
单bit的控制信号必须触发为单周期
目前的做法先对传输的信号采样,之后会加入反压机制
为什么stall小核心,但指令仍然提交
目前stall只stall id之前,所以需要提前4条指令开始就发出检查speed,然后stall信号需要去sl——cnt+num——pipe<= inst_num+2,防止提交大于cnt
需要去精确的停止在最后一个指令,此时需要去kill其他指令,且不能取指令
目前未暂停取指令(低优先级)(否则可能导致检查点出错)
去除GHT多余的arf pdst信号(低优先级)
加入检查机制
修复指令阈值很少时大核发出的检查点时间点问题:大核执行完这个程序片段,然后小核心还没执行(低优先级)
2025/4/10
为什么检查指令很短的时候会出错?
check speed在最后会出现问题
因为最后可能没有那么多指令,且大核可能执行没有小核心快,所以ic_cnt还是要传输,只不过需要三周期传一次,
解决办法:
- ic_cnt三周期采样一次,需要保证小核心不能超过大核心,如果小核心的sl_cnt+num_pipe>ic——cnt,停止掉小核心(也就是之前方法+采样)
为什么最后全部程序片段执行完成大核没有停止?
大核需要咨询小核心是否完成,最后信号传入大核为bigComp_reg,之前为wire变量,但由于目前基于采样,只能使用寄存器存储起来
如何反压检查点和数据的传输?
检查点的传输会依赖大核的dest,如果反压,就直接将dest置为0,这样大核就停止传输数据
反压数据可以停止大核提交
目前性能:
原来:81900
加入cdc,将指令改为3000:82155
加入cdc,将指令改为2:610325
2025/4/17
简化逻辑
GHT的转发是没必要的,在commit阶段其实可以直接传输数据了
- 需要给buf加入cdc的反压
- 目前小核数目变为不可配置(RSU)
问题:
新的逻辑给fence也转发了,导致逻辑出错,(fence竟然也是use_stq)
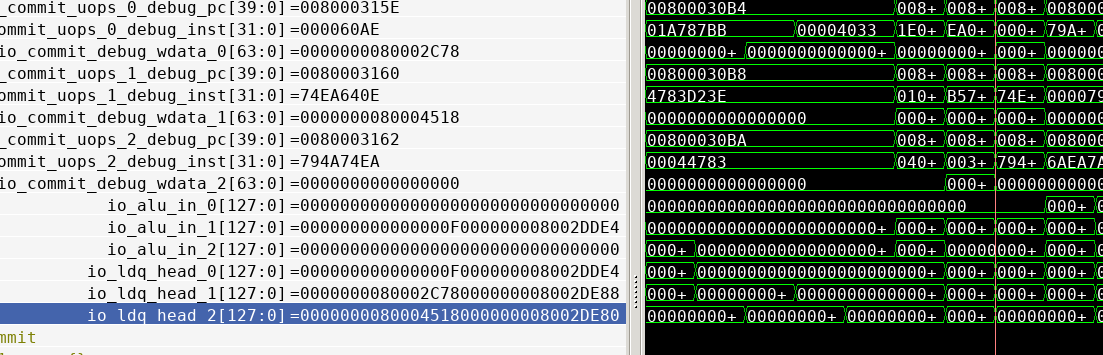
这个lsu的header好像有问题?
这里连续提交了三条指令,但是只有两条在header出现,ldq/stq_head指针溢出了,导致出错
目前可以跑通一轮coremark:
未校验:21sec
校验:27sec
大概下降30%
不过coremark好像是计算密集型,可以很好的利用多发射的优势,导致大核早执行完成,但小核才刚开始跑,TC_Overtaking算是一直执行load/store(程序局部性差),即使大核也无法去利用其多发射的优势
小核调度情况

小核大核执行速度比较

前一个LD的包和下一个LD的包一起发送,导致一个包送入两个地方?

需要去判断两个包的目的核
10轮结果
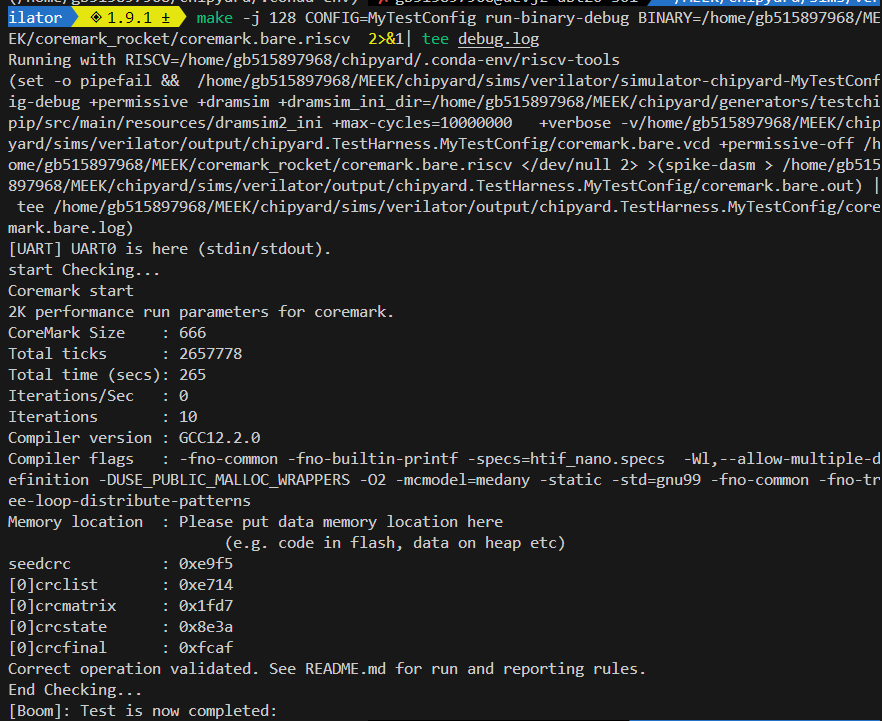
20轮结果
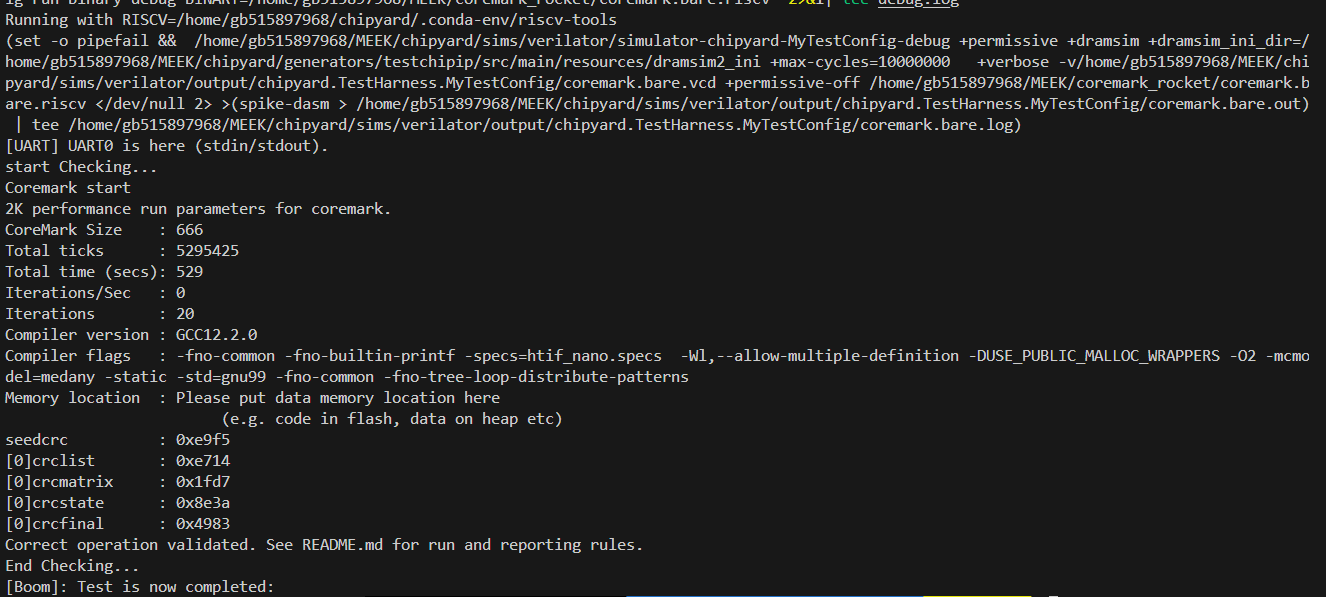
30轮
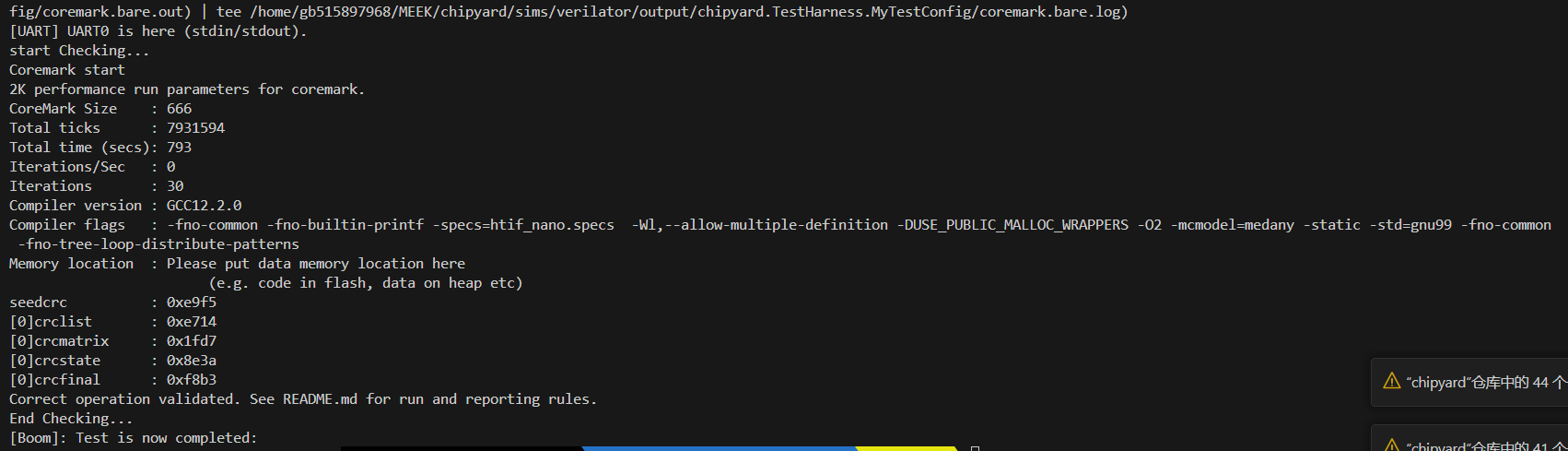
1轮dhrystone
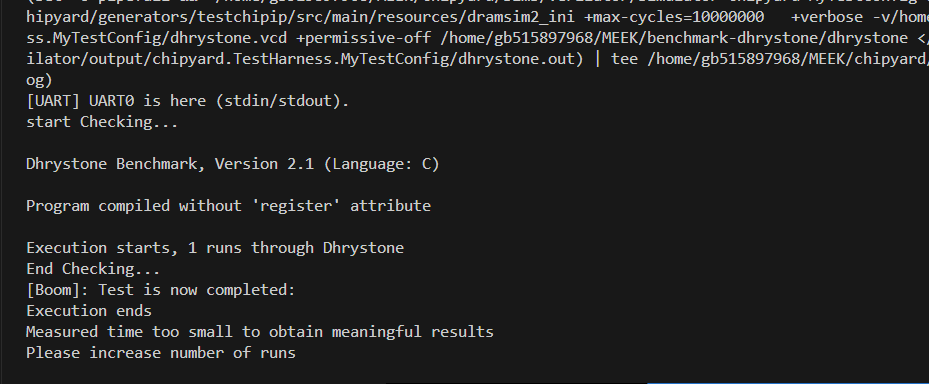
出现了之前跑50轮的错误,(好像是内存满了)

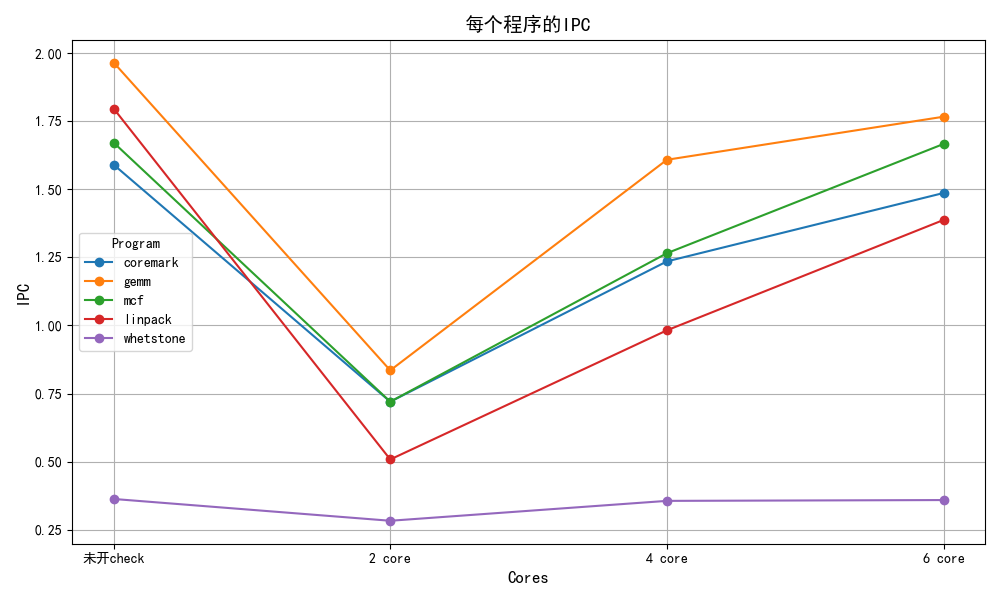
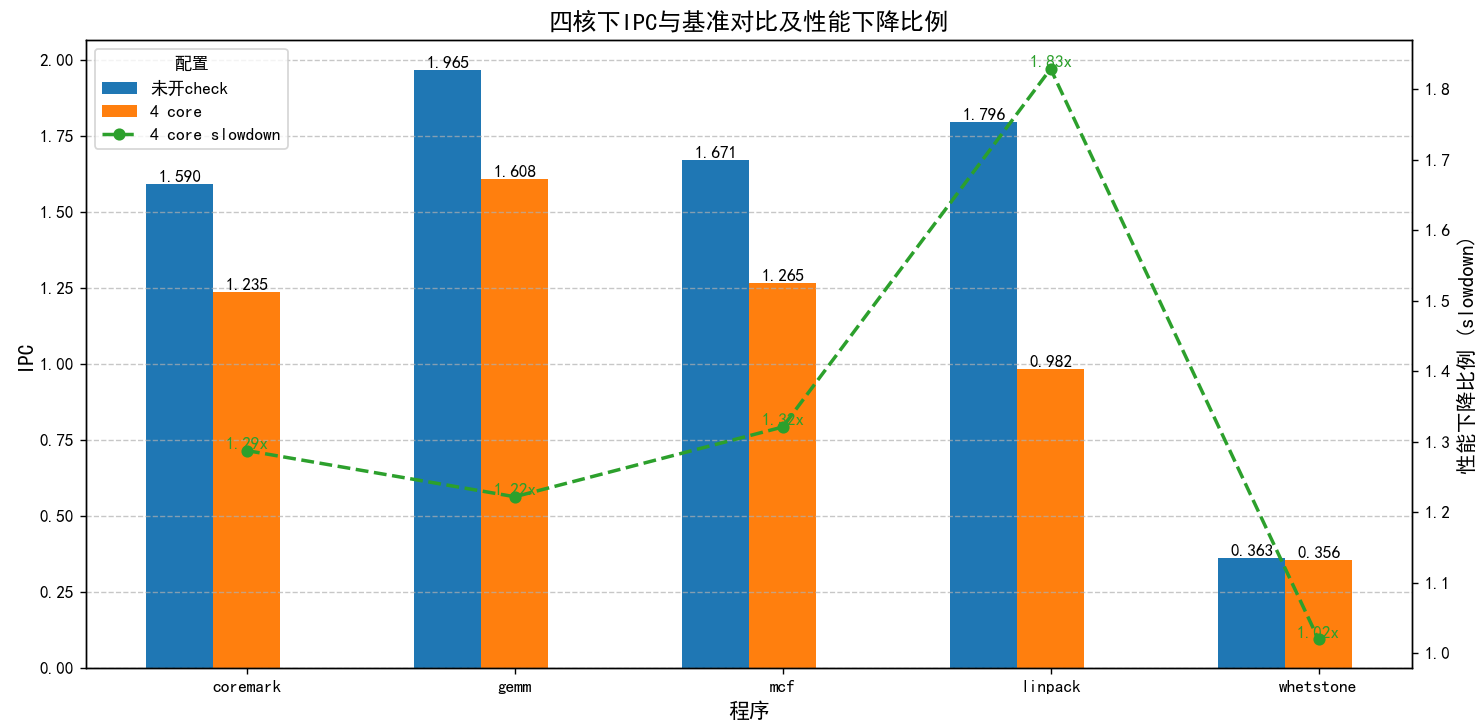
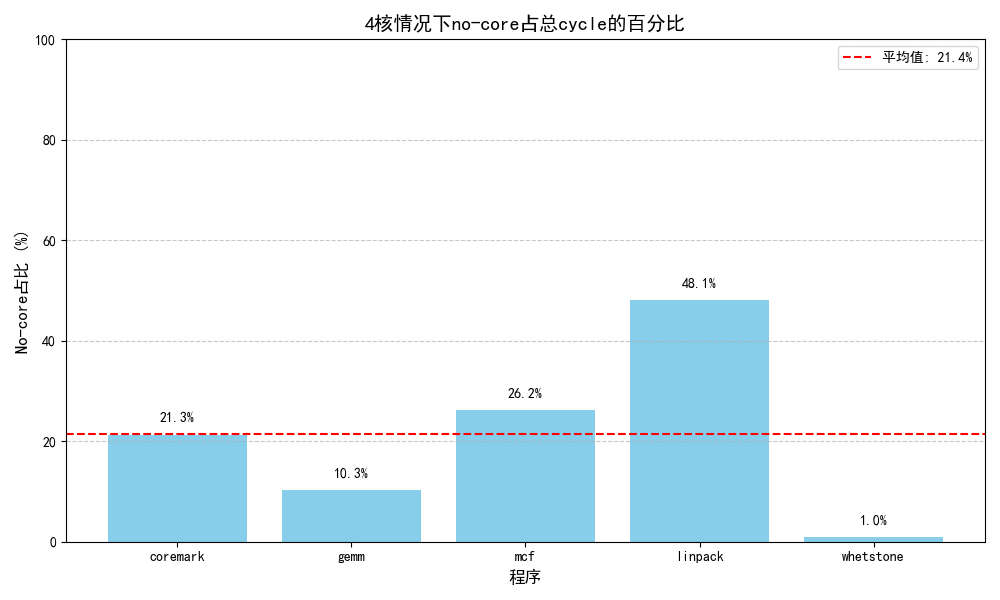
coremark一轮性能:
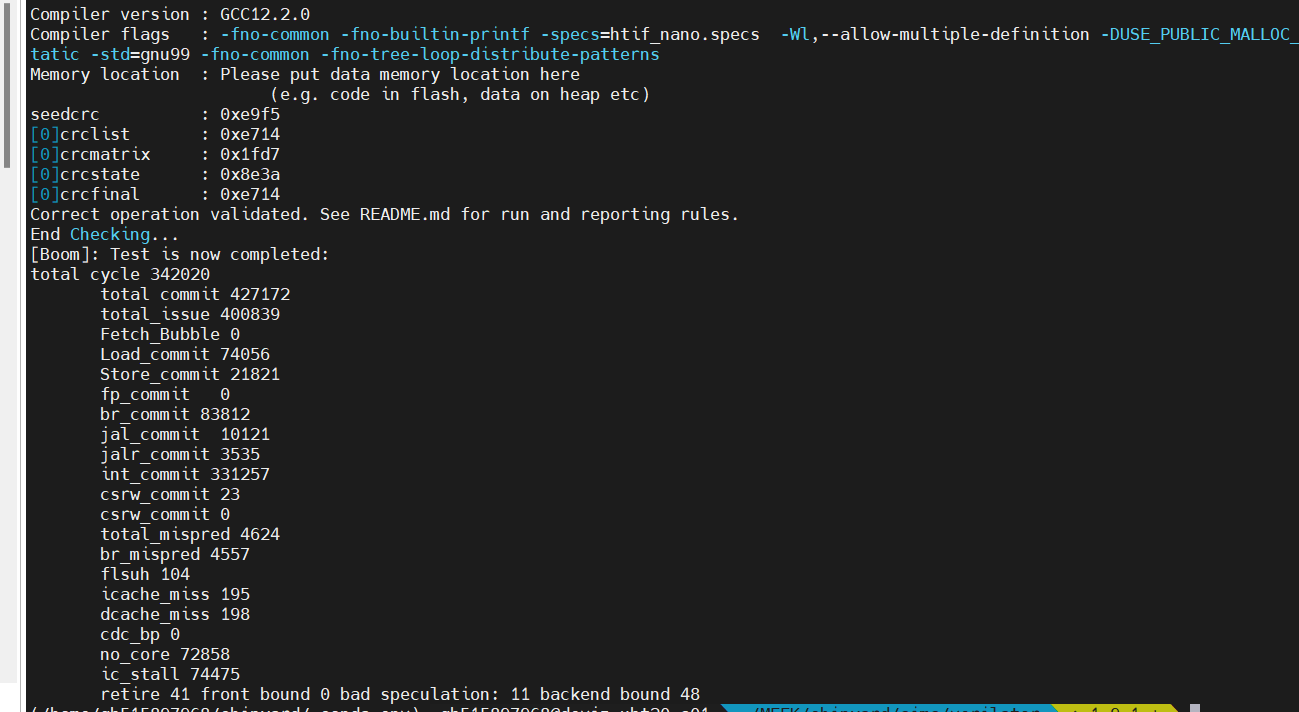
没开check
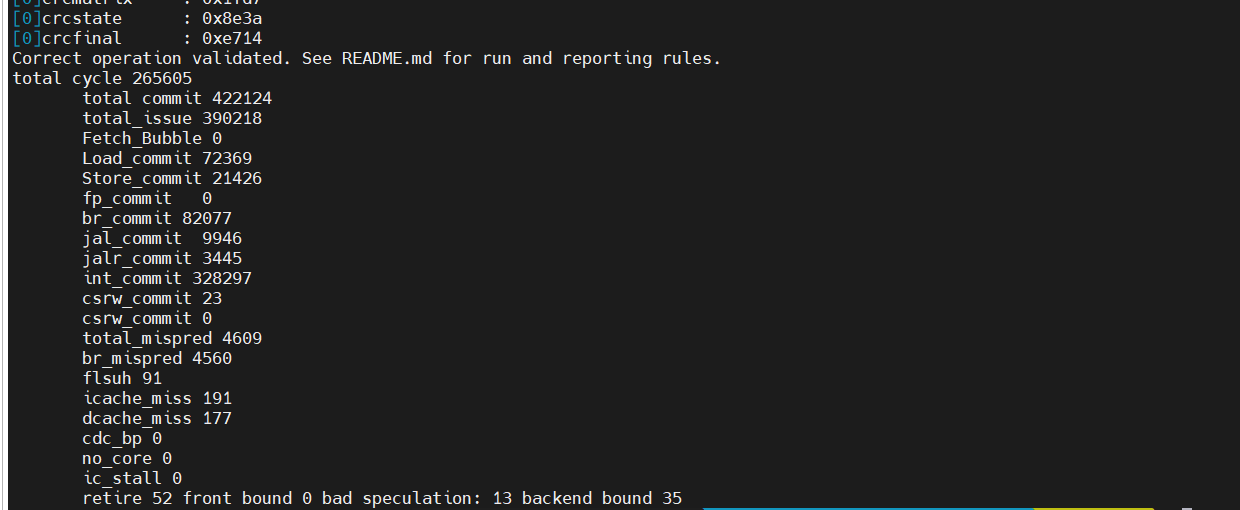
| IPC | total cycle | cdc_bp | no_core_avaliable | ic_stall | ||
|---|---|---|---|---|---|---|
| 未开check | 1.59 | 265605 | 0 | 0 | 0 | |
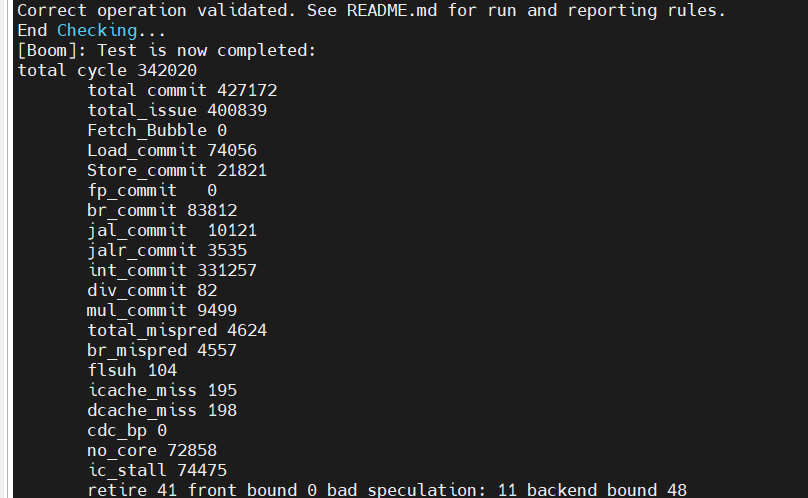
| 开check | 1.235 | 342020 | 0 | 72858/21.3%/97.8% | 74475/21.7% |
| Load | Store | br | jal | jalr | int | |
|---|---|---|---|---|---|---|
| 指令总数/占比 | 72369/17.1% | 21426/5.1% | 82077/19.4% | 9946/2.4% | 3445/0.8% | 328257/77.8% |
总体性能下降:22.3%
slowdown:1.287
其中,no_core_avaliable占据了性能下降的最大部分(21%/95.5%)
5.6数据
四个小核执行
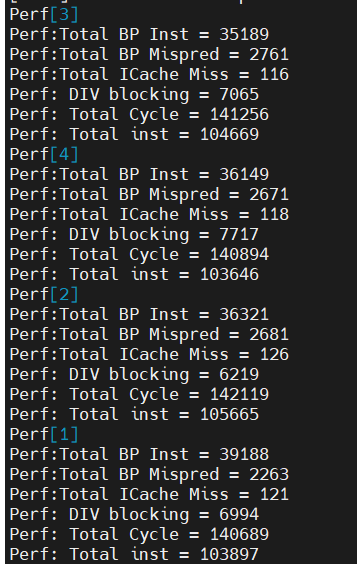
大核数据
| Load | Store | br | jal | jalr | div | mul | |
|---|---|---|---|---|---|---|---|
| 指令总数/占比 | 72369/17.1% | 21426/5.1% | 82077/19.4% | 9946/2.4% | 3445/0.8% | 82/0.02% | 9499/2.2% |
小核IPC
| core1 | core2 | core3 | core4 | avag | |
|---|---|---|---|---|---|
| IPC | 0.73 | 0.745 | 0.744 | 0.734 | 0.74 |
| 分支误预测 | 5.8% | 7.4% | 7.8% | 7.4% | 7.1% |
| ICache缺失率 | 0.1% | 0.1% | 0.1% | 0.1% | 0.1% |
| DIV Block | 5.0% | 4.4% | 5.5% | 4.4% | 5.0% |
由于小核频率是大核一半,故小核在大核频率下的IPC约为0.37,
2 core
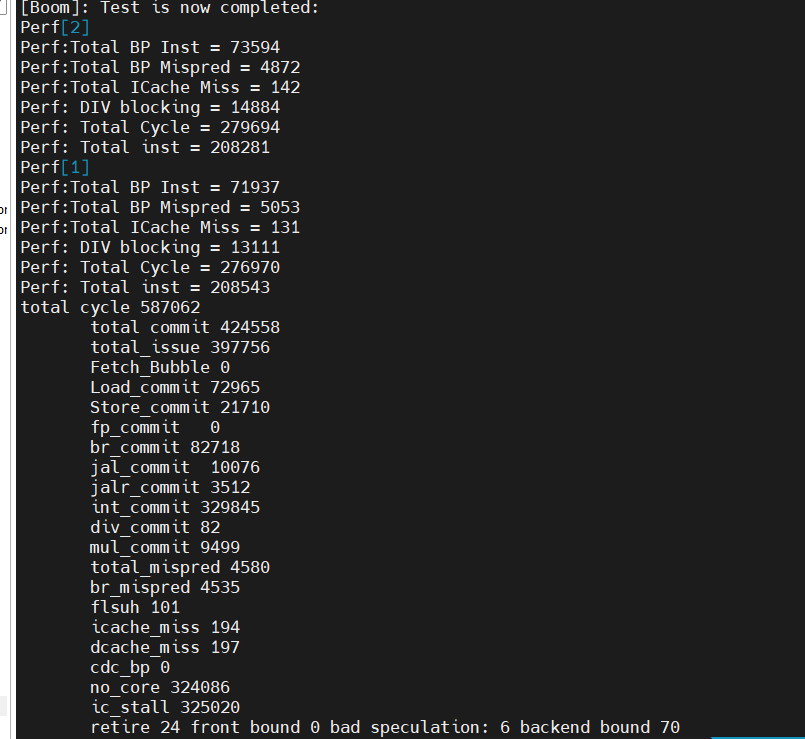
开启check:
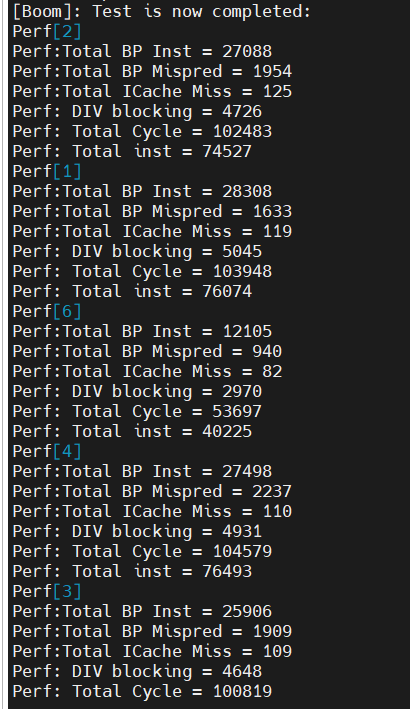
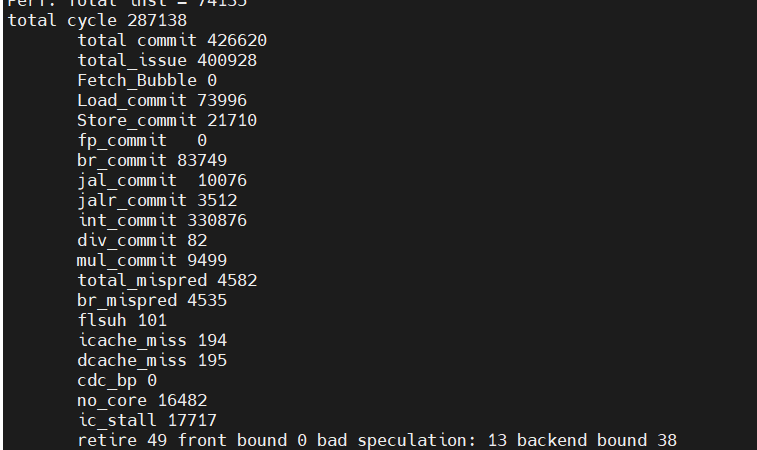
6 core:
| IPC | total cycle | cdc_bp | no_core_avaliable | ic_stall | ||
|---|---|---|---|---|---|---|
| 未开check | 1.59 | 265605 | 0 | 0 | 0 | |
| 2 core | 0.72 | 587062 | 0 | 324086/55.2%/99.7% | 325020/55.3% | |
| 4 core | 1.235 | 342020 | 0 | 72858/21.3%/97.8% | 74475/21.7% | |
| 6 core | 1.486 | 287138 | 0 | 16482/5.7%/93% | 17717/6.2% |
gemm
| IPC | total cycle | cdc_bp | no_core_avaliable | ic_stall | ||
|---|---|---|---|---|---|---|
| 未开check | 1.965 | 182857 | 0 | 0 | 0 | |
| 2 core | 0.835 | 429344 | 0 | 230183/53.7%/100% | 230434/53.7% | |
| 4 core | 1.608 | 223510 | 0 | 72858/21.3%/97.8% | 23046/10% | |
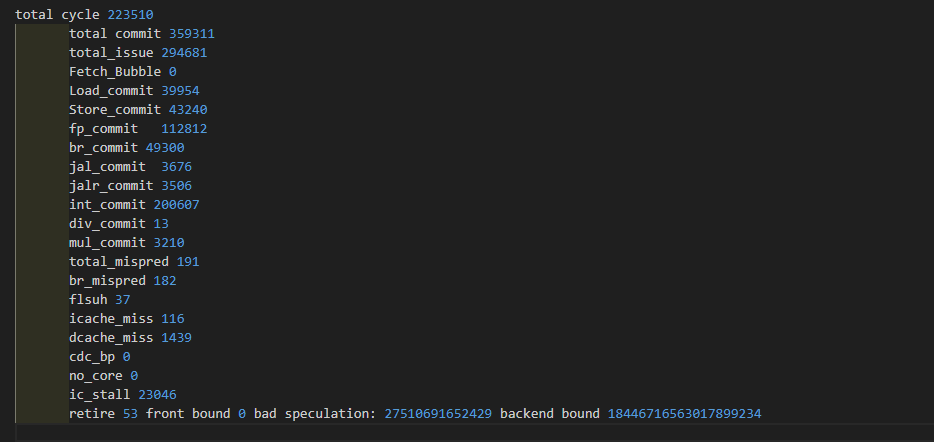
| 6 core | 1.766 | 203488 | 0 | 913/4.5%/45.1% | 2025/1% |
| core1 | core2 | core3 | core4 | avag | |
|---|---|---|---|---|---|
| IPC | 0.86 | 0.85 | 0.86 | 0.84 | 0.855 |
| 分支误预测 | 0.9% | 1.1% | 0.8% | 1.1% | 1% |
| ICache缺失率 | 0.04% | 0.01% | 0.05% | 0.06% | 0.04% |
| DIV Block | 0.67% | 0.83% | 0.81% | 0.82% | 0.78% |
mcf
| IPC | total cycle | cdc_bp | no_core_avaliable | ic_stall | ||
|---|---|---|---|---|---|---|
| 未开check | 1.671 | 1906116 | 0 | 0 | 0 | |
| 2 core | 0.72 | 4869315 | 0 | 3015365/55.2%/99.7% | 3021601/55.3% | |
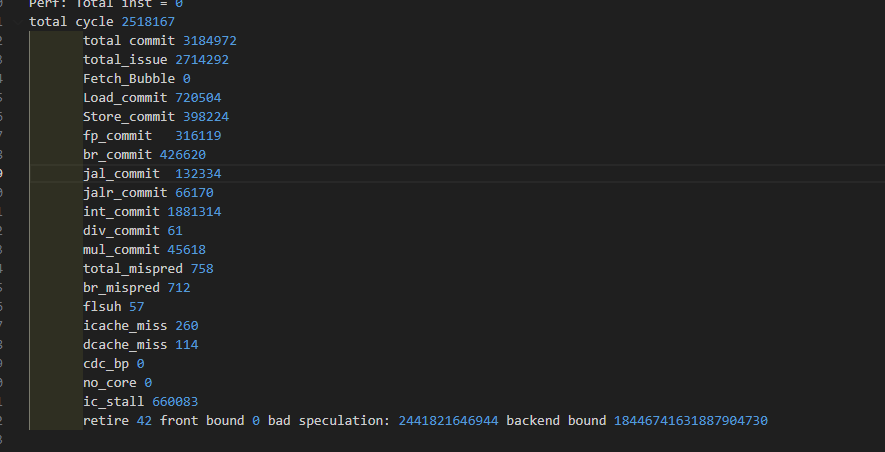
| 4 core | 1.265 | 2518167 | 0 | 72858/21.3%/97.8% | 660083/21.7% | |
| 6 core | 1.666 | 1912461 | 0 | 8211/0.4%/37.8% | 21735/1.1% |
| core1 | core2 | core3 | core4 | avag | |
|---|---|---|---|---|---|
| IPC | 0.74 | 0.67 | 0.7 | ||
| 分支误预测 | 5.5% | 6.7% | 6% | ||
| ICache缺失率 | 0.02% | 0.03% | 0.02% | ||
| DIV Block | 1.4% | 1.2% | 1.3% |
linpack
| IPC | total cycle | cdc_bp | no_core_avaliable | ic_stall | ||
|---|---|---|---|---|---|---|
| 未开check | 1.796 | 243676 | 0 | 0 | 0 | |
| 2 core | 0.508 | 868162 | 0 | 632489/72.9%/100% | 633141/72.9% | |
| 4 core | 0.982 | 445532 | 0 | 214406/48.1% | ||
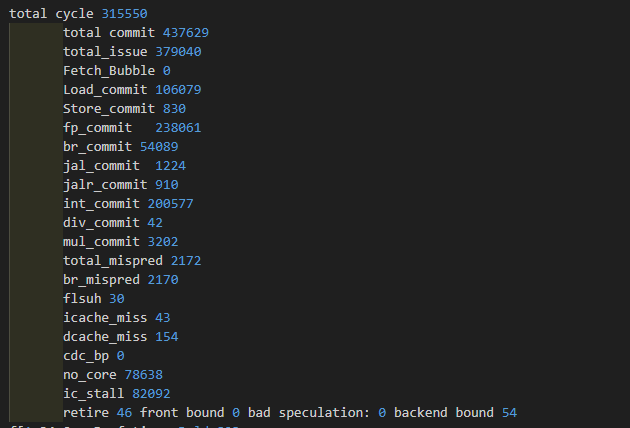
| 6 core | 1.387 | 315550 | 0 | 78638/24.9%/95.8% | 82092/26.0% |
| core1 | core2 | core3 | core4 | avag | |
|---|---|---|---|---|---|
| IPC | 0.52 | 0.53 | 0.527 | ||
| 分支误预测 | 7.6% | 7.7% | 7.6% | ||
| ICache缺失率 | 0.03% | 0.03% | 0.03% | ||
| DIV Block | 0.81% | 0.66% | 0.74% |
whetstone
| IPC | total cycle | cdc_bp | no_core_avaliable | ic_stall | ||
|---|---|---|---|---|---|---|
| 未开check | 0.363 | 180812 | 0 | 0 | 0 | |
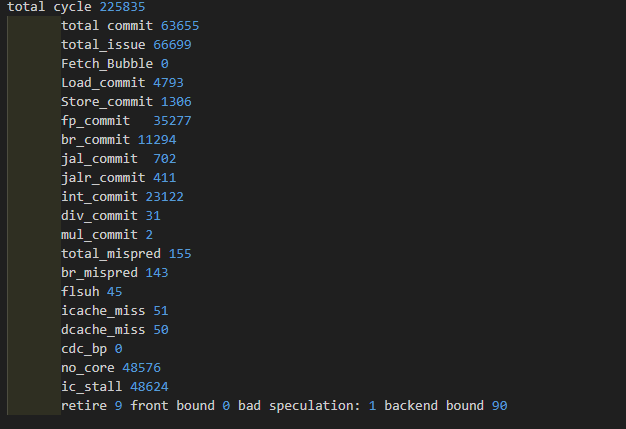
| 2 core | 0.283 | 225835 | 0 | 48576/21.5%/100% | 48624/21.5% | |
| 4 core | 0.356 | 181373 | 0 | 1728/1% | ||
| 6 core | 0.359 | 180019 | 0 | 2/0%/1% | 213/0.01% |
| core1 | core2 | core3 | core4 | avag | |
|---|---|---|---|---|---|
| IPC | 0.374 | 0.376 | 0.274 | 0.348 | |
| 分支误预测 | 2.1% | 3.2% | 1.9% | 2.5% | |
| ICache缺失率 | 0.2% | 0.03% | 0.2% | 0.03% | |
| DIV Block | 0% | 0% |
firesim代码调试
出错的地方小核执行的片段很少,应该是进入异常了,并且此时小核并未去写入2号寄存器,所以怀疑ECP转发有问题
根本问题:
在进入syscall时,需要退出检查模式,所以此时需要去给出相应的ecp
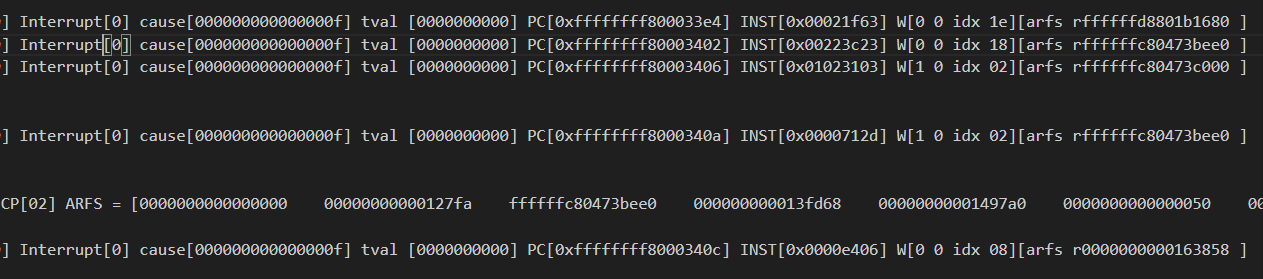
syscall只会持续12个周期左右,之后如果ECP没传过去,很有可能就是ECP出错(被异常程序复写)
这里发了两次ECP
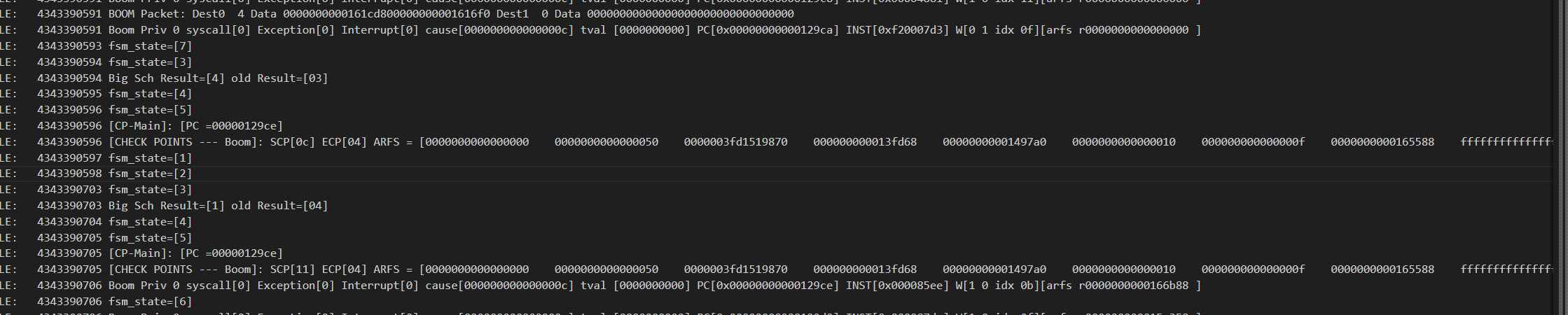
这个trans阶段直接跳到fsm_presch暂时不清楚?
CYCLE: 2109544445 C1: 377667396 [1] pc=[00000000000a84c4] W[r 1=0000000000107990][1] R[r 2=0000003fd64c7a00] R[r 0=0000000000000000] inst=[000070a2] DASM(000070a2)
异常处理程序好像会写入寄存器,导致寄存器SCP发送出错?
应该是上下文恢复,但看了之前的a0寄存器值为1,但恢复上下文写入了31?
根本原因就是异常处理程序一开始也会去更新寄存器,之后才是进入保存上下文
比如他会先执行csrrw x4, sscratch, x4,导致x4被修改
所以修改状态机是最合理的方法,
一个做法:
- 正常模式传ECP是SCP和ECP一块传,而进入异常需要只传ECP,需要立即传输,否则会遇到ECP不正确,
感觉得去独立SCP和ECP,但可能面积剧增
或者就是进异常处理后直接停止stall,直到ECP发出去
GHE的PID——CFG是什么意思,U模式的satp不一定一成不变吧,如果页表修改了,那么会触发什么呢,如何处理跨页的?
发现核1,2,4无响应,只有核3在
CYCLE: 1325299707 C1: 376960845 [1] pc=[00000000000139a4] W[r10=0000000000000000][1] R[r 0=0000000000000000] R[r 0=0000000000000000] inst=[c200452b] priv[0],没有正确进入检查模式
CYCLE: 1325294905 [C1] Paste PC [0000084aca]
CYCLE: 1325295441 [C1] ECP idx[1f] arfs 0000000000000003 farfs 0000000000000000
这个bug就是在处理异常中ECP发了过来,导致RCU status变为3,退不出循环
想到一个问题,小核心的信号会去修改大核
在ctrl c时,可能造成FPGA板子断开连接,具体原因是linux把PCI对应口给卸载了,可以让他重新扫描一遍
echo 1 | sudo tee /sys/bus/pci/rescan
无法跑多个workload
需要在退出时清空CDC,但reset信号或上自己的信号是否为一个正确的做法?
dcacheArbPorts具体含义?是否影响整体
Chisel exception caught when instantiating ghm within DigitalTop at (generators/rocket-chip/src/main/scala/guardiancouncil/GHM.scala:393:28)
Chisel exception caught when instantiating system within ChipTop at (generators/chipyard/src/main/scala/ChipTop.scala:27:35)
Caused by: chisel3.package$ChiselException: Error: No implicit clock.
新版本的chipyard必须加入wrapper,要不会显示没有隐式时钟
diplomacy赋值node时,必须用val,使用var会导致node错误赋值,或者多次赋值
Could not find or load main class chipyard.Generator
将.classpath_cache文件夹删除
new chipyard.config.WithTileFrequency(500, Some(4)) ++
这个单纯只是把tile加入了id后缀,如果你的tile不是tile结尾,这里会出错的
这个和你的tile的 val baseName = “rockettile”
val uniqueName = s”${baseName}_$tileId”
有关,建议直接改为tile,这样就不用去修改WithTileFrequency函数
GHM会接入gemini的核心,导致小核的核心+1,从而需要修改GHM的配置
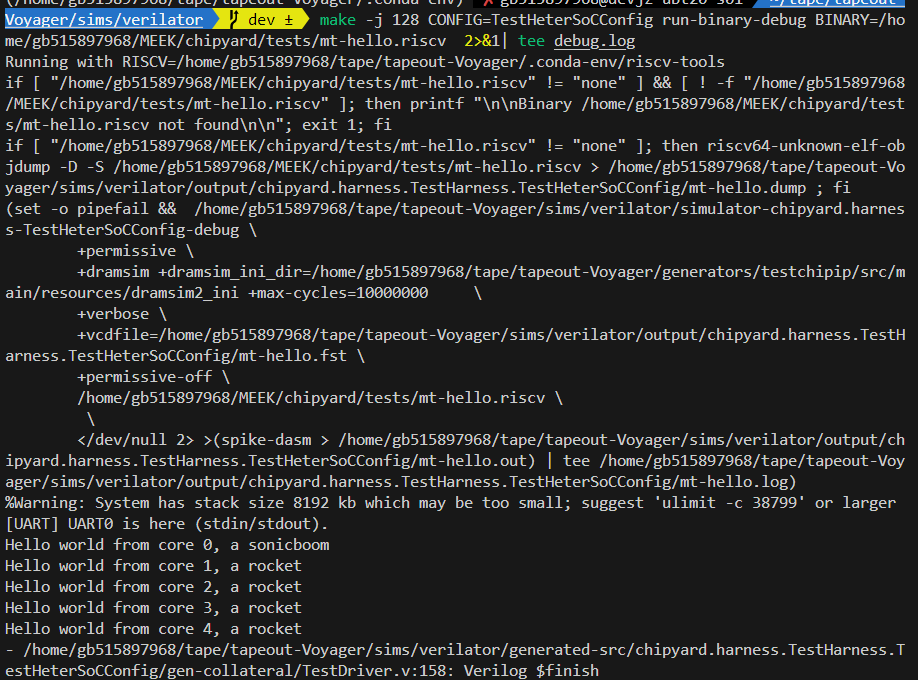
这个遇到bug,准备先停止,完成
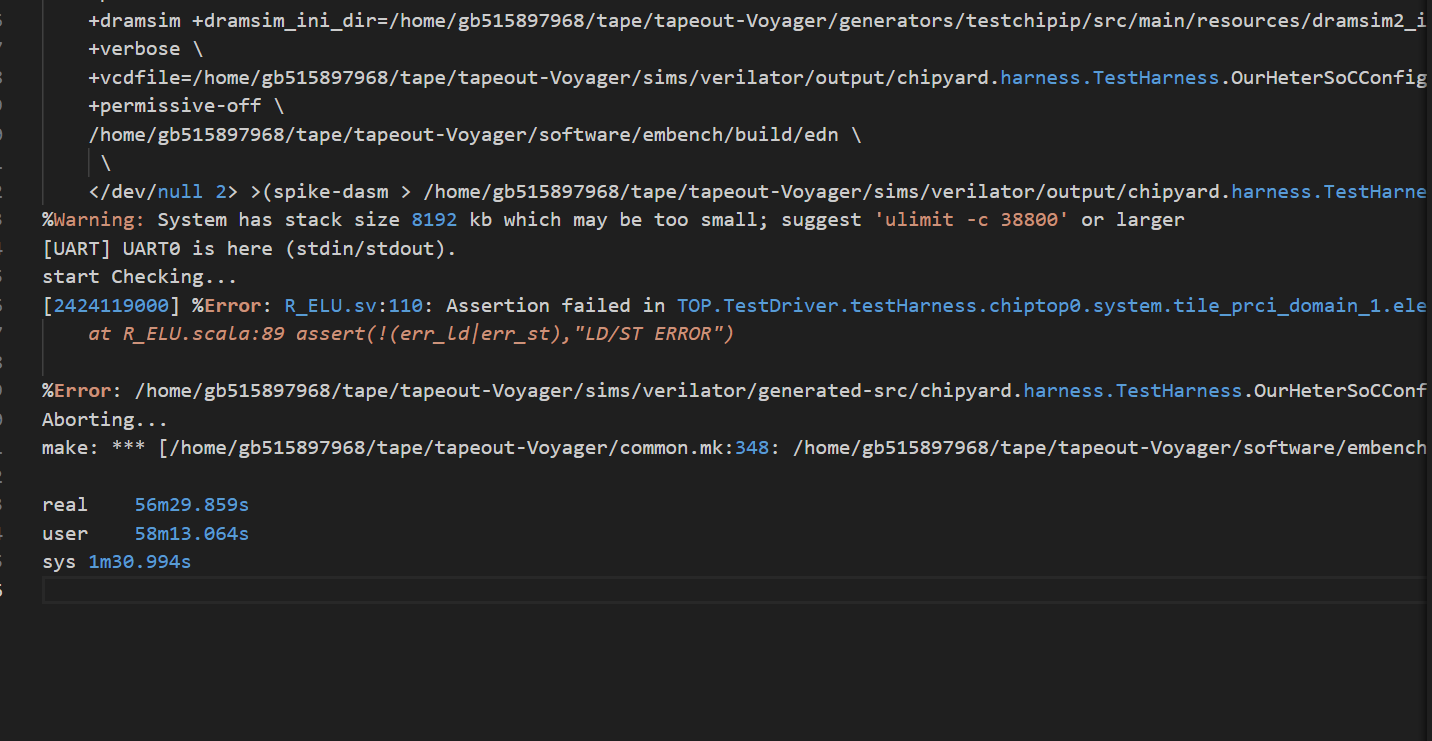
global配置meek不太行,必须得上cde了,所有的node都得改
1.13.0必须挂代理才可以进去
新版本的不能和旧版本的使用同一个仿真文件夹,否则打不开blk——dev——log
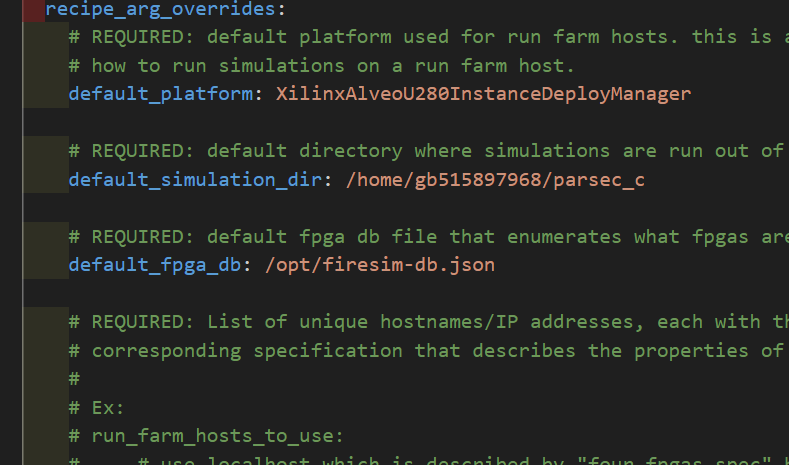
目前感觉gcc的bug是因为没有正确给出ecp的target,
这里应该把ecp发到3,而不是2
nemu linux
Difftest 适配
在跑linux需要加入csr的检查,以测出特权指令执行的结果是否正确
首先需要做的就是维护一套csr寄存器,我个人做法就是设置一个csr_map结构体,然后查询这个结构体来找到csr是否实现
1 | nemu_csr_t csr_map[] = { |
然后每次增加一个csr寄存器,只需在difftest.cc和inst.c同时将寄存器加入map即可
之后我们需要实现非法指令异常,可以参考yield在nemu实现,当遇到一些没实现的csr时,就可以触发异常,然后sbi会自己处理这些没实现的csr,我们此时也要去将这个非法指令访问异常同步到spike中,具体可以参考spike的get_csr
完成上述,基本difftest改造完成
移植opensbi
首先下载opensbi
1 | git clone https://github.com/riscv-software-src/opensbi |
然后复制一份platform/templete,将这个改为适配nemu的平台,具体改动:
先设置objects.mk,然后
1 | PLATFORM_RISCV_XLEN = 32 |
然后设置platform.c,主要就是设置timer,uart的地址,这里可以根据自己的想法去设置设备地址,也可以使用nemu内部的地址,建议uart使用nemu的,只需稍微改动即可,改动可参考uart8250手册
之后就是debug过程,最后由于跳转到0x0,所以会直接段错误退出,注意最好看19年的手册,24年新出的手册会增加一些csr,从而导致spike触发非法指令
运行结果如下

如果不确定需要实现哪些寄存器,可以先抛出非法指令异常,之后opensbi会告诉你要设置哪些寄存器
移植linux
为什么执行到relocate_enable_mmu会访问无效地址?
因为指第一次写入satp并没有去执行sfence,所以导致系统仍然使用之前的映射关系
- 需要去为ref传递异常号
- 为什么会跳转到c000098,这里可能发生了嵌套异常(错误的行为)
终于可以跑起来一部分页表了:
发现之前的问题是因为自己的pte解析出错了
目前的问题是:
会访问0x80040000的数据,这个就是j指令
bingo
Bingo Spatial Data Prefetcher
概要
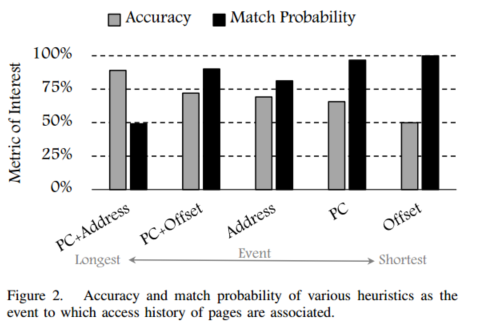
在本文中,我们做出以下贡献:•我们表明,依靠单个事件发出预取请求是最先进的空间数据预取的主要效率来源。
•我们提出了一个tage-like预测器,以准确和最大提取空间相关的数据访问模式。
•我们建议将多个历史表合并到单个统一元数据表中的方案,从而大大降低了存储要求。
•将所有内容放在一起,我们提出了一个名为Bingo的空间数据预取器,并对各种大数据应用程序进行了精心评估。我们表明,我们的提案平均将系统性能提高了60%,而没有预取器的基线高达285%。同时,它的表现胜过最好的先前的空间数据预取器平均11%,高达67%
背景
Spatial data prefetching:
- 仅需要存储offset或者delta,不需要存储完整地址
- 访问顺序不重要,不需要记录访问顺序
- 消除强制cache miss,(cache的3C)
之前的空间预取器分为两类:
- PPH:记录每个页面的访问历史方法
- SHH:记录全局访问方法(SPP)
微结构设计
bingo在访问新页面时去将模式移动到历史表,他使用PC+addr和pc+offset模式,PC+addr预测的为长历史事件(相同的指令和相同的地址应该同时发生),
但是实际两个表是多于的

也就是短事件和长事件有很多预测一致的表项
对于Bingo的情况,在“PC+Address”中携带“PC+Offset”的信息;因此,通过知道‘PC+地址’,我们也知道‘PC+偏移’是什么。为了利用这种现象,我们建议只具有一个历史表,该历史表仅存储长事件的历史,但是用长事件和短事件来查找。对于宾果的情况,历史表存储在每个“PC+地址”事件之后观察到的足迹,但是利用触发器访问的“PC+地址”和“PC+偏移”两者来查找足迹,以便提供高准确性,同时不丢失预取机会。
为了达到这样,我们使用短事件去hash,但长事件作为tag保存,并且替换算法为LRU
每次访问时,先使用pc+addr匹配,如果没匹配到,就使用pc+offset匹配
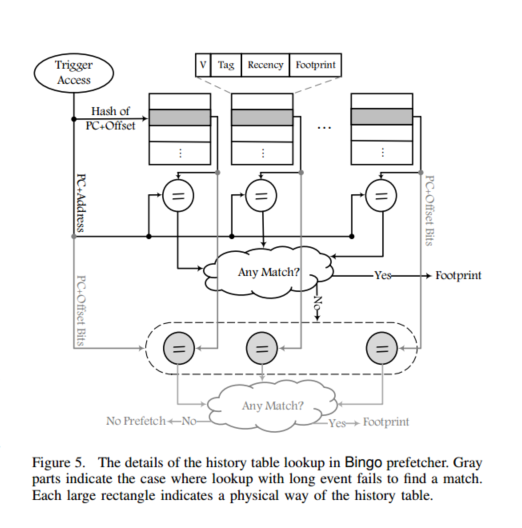
Bingo历史表的组成
Bingo的空间数据预取器采用了一个存储高效的单历史表设计,这个表是实现预取功能的核心组件。历史表的每个条目包含了以下几个关键组成部分:
- 触发访问事件 :这是预取器在记录访问模式时所依据的事件,通常包括程序计数器(PC)、地址(Address)和偏移量(Offset)等信息。例如,长事件为
PC+Address,短事件为PC+Offset。 - 页面足迹(Footprint) :这是一个位向量,表示页面中哪些块被访问过。每个位对应页面中的一个缓存块,
1表示该块被访问过,0表示未被访问。 - 踏频信息(Recency) :用于记录条目的最近使用情况,帮助预取器选择替换策略,如最久未使用(LRU)。
- 标签(Tag) :用于标识条目,确保正确的事件匹配。
Bingo历史表的工作原理
Bingo历史表的工作过程可以分为以下几个步骤:
- 触发访问 :当处理器访问一个新的页面时,触发访问发生,预取器开始记录该页面的访问模式。
- 记录足迹 :在页面的驻留期间,预取器会记录所有访问到的缓存块,生成页面的足迹(Footprint)。
- 存储足迹 :当页面的驻留结束时,预取器将足迹以及触发访问的事件(如
PC+Address)存储到历史表中。存储时,使用短事件的哈希值来索引表的位置,并将长事件作为标签存储。 - 预取决策 :当后续的访问触发预取时,预取器首先使用长事件(如
PC+Address)查找历史表。如果找到匹配项,就使用对应的足迹进行预取。如果未找到匹配项,则使用短事件(如PC+Offset)再次查找历史表。如果找到匹配项,就使用对应的足迹进行预取。如果仍未找到匹配项,则不进行预取。
通过这种设计,Bingo能够在保持高准确性的同时,不丢失预测机会,从而提高系统性能。
其中足迹的获取是第一次访问这个页面就记录,然后结束后把足迹送入,类似于SMS生成方式
总结
该论文创新点在于结合了PC+addr和PC+offset,并且将二者存在一个表内,pc+offset索引,pc+addr作为tag
spp
Path Confidence based Lookahead Prefetching
首先,SPP 使用基于压缩历史的方案,可以准确预测复杂的地址模式。 其次,与其他基于历史的算法不同,当地址模式在物理页面之间转换时,这些算法会错过许多预取机会,而 SPP 会跨物理页面边界跟踪复杂模式,并在它们移动到新页面时立即继续预取。最后,SPP 利用其对预测的信心,根据每个预取流自适应地限制自身。SPP 以最小的开销实现这一点,严格在物理地址空间内操作,并且不需要任何额外的处理器核心状态,例如 PC。
SPP贡献
- 我们引入了一种签名机制,以压缩形式存储内存访问模式并启动前瞻预取过程。此 12 位签名最多可压缩四个小增量,且不会产生混叠。通过将签名与未来可能的增量模式相关联,SPP 可以快速准确地学习简单和复杂的内存访问模式。签名还可用于检测两个物理页面之间的局部性,并从一个物理页面的末尾继续执行相同的预取模式,直到下一个物理页面。
- 我们开发了一种基于路径置信度的预取节流机制。随着lookahead预取的深入,一系列签名构建了一条签名路径。每条签名路径都有不同的置信度值,这取决于其之前的增量历史、预取准确性和预取深度。路径置信度值用于动态限制预取深度,以平衡预取覆盖率和准确性
- 与之前基于前瞻的预取器 [12]、[13] 不同,SPP 不需要深入到核心微架构中,而是纯粹基于物理内存访问流
MOTIVATION AND PRIOR WORK
对于之前的工作:
- 需要去处理复杂的访存模式
- 需要去自适应预取深度(lookahead深度)
- 需要考虑跨页预取
DESIGN
随着lookahead深度增加,预取置信度在下降,公式如下
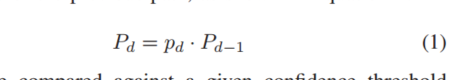
然后将Pd与置信度阈值对比,以确定何时停止预取,置信度Pd还可以选择插入哪个缓存,置信度高的插入高级别的
SPP在物理空间运行,不用访问tlb,spp使用一个页面的学习结果来预测其他页,通过两种模式:
首先,虽然增量历史签名是在每个物理页面的基础上维护的,如第 III-B 节所述,但这些签名索引到用于预测增量的全局表中,该表由所有页面共享。其次,如第 III-D 节所述,当第一次按需访问新的物理页面时,可以继承来自其增量预测跨越页面边界的先前物理页面的增量签名模式,并将其用于引导此新页面中的预测。这使 SPP 具有不需要长时间的每页预热期来开始预取复杂模式的优势,从而导致更高的预取覆盖率。
大致设计
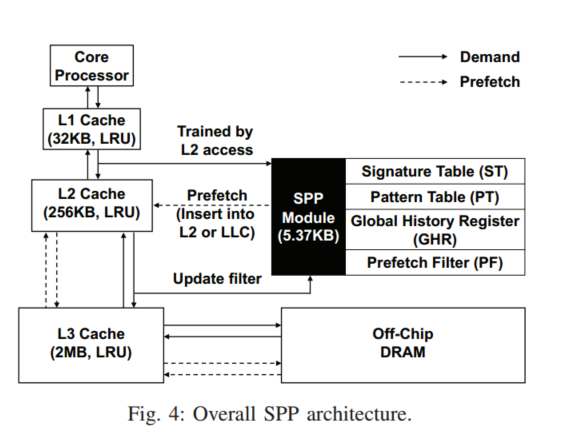
主要有三个结构:Signature Table, Pattern Table, and Prefetch Filter以及一个小的GHR(用于跨页预取)
SPP是用访问L2Cache的流来训练,可以将结果填充至L2或LLC,ST跟踪最近256个页面,每个页面的delta访问压缩为12bits的签名,然后这个可以去访问模式表(PT),存储预测的模式,PT还会去估计给定增量的置信度如果置信度高,就会作为预取候选传送给PF,PF检查是否存在冗余的预取,如果预测的增量跨4k边界,SPP不会发出预取,而是送入GHR学习
Learning Memory Access Patterns
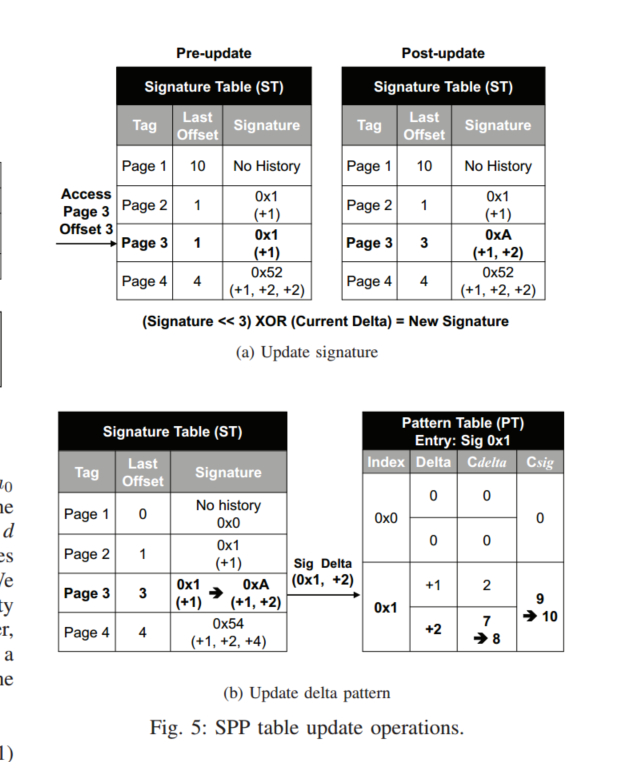
ST是在4K页面内捕获访问模式,并将先前的offset记录在表中,如上图A,物理页面3,offset为3的请求访问ST,ST会根据下面公式更新签名
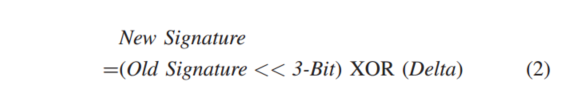
我们此时可以认为,给定的一组访问,比如0x1,他还会去访问增量为2的地址,如果PT不包含匹配的增量,他会在这个签名所属的一个地方去找一个Cdelta最低的值填入
我们会在PT中更新这种访问模式,更新策略就是,找到delta为2的,将置信度+1,为了去估计每个delta的预取准确率,还维护了sig计数器,他跟踪签名出现的次数,如果两个技术器其中一个饱和了,与该签名的所有计数器将会右移1,这样做不会去丢失之前的历史记录
PT的条目是全局共享的,也就是页面A,B共享相同的访问模式,他们会生成同样的签名,并且签名会索引到PT中相同的条目,更新PT访存模式
PT每个条目可容纳最多四个delta,如果其置信度Cd>=Cdelta/Csig,则这个条目就成为预取候选者
delta最大为7bit,假设 4KB 页面具有 64B 缓存行,所有可能的增量都在 (-63) 到 (+63) 的范围内。我们对正增量和负增量都使用 7 位符号+幅度表示。因此,负增量和正增量会产生不同的签名,指向模式表中的不同条目,并最终指向不同的预取目标。但注意大于7的delta会发生混叠
Path Confidence-based Prefetching
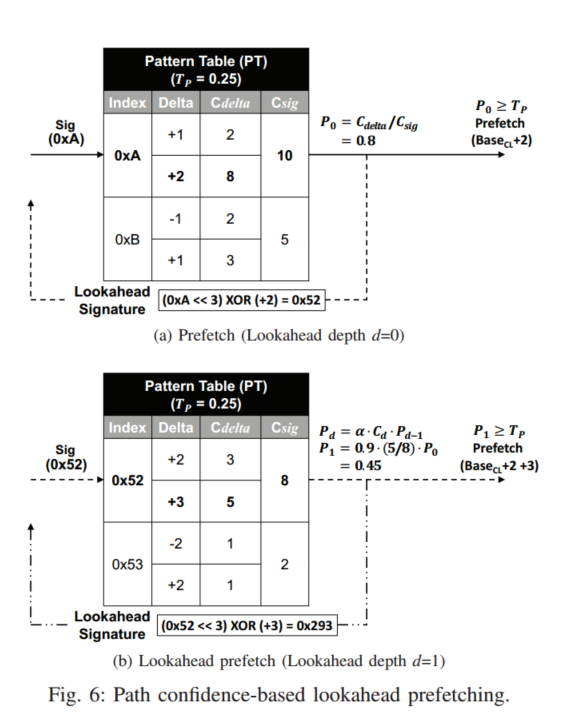
路径置信度是根据0XA的签名相关的增量计算的,初次访问置信度为Cdelta/Csig,所以+2的增量会被送入预取
此外PT还会构建新的签名以供下次预取使用,虽然可能会有多个候选,但只选择置信度最高的生成签名,新的lookahead签名用于再次访问PT,直至Pd小于Tp,更大的置信度Tf决定了给定的预取应该送入哪个缓存
SPP可以引入a来降低lookahead的概率
请注意,为简单起见,在上面的讨论中,我们在浮点数的背景下描述了路径置信度计算。然而,在实际实现中(以及在我们的模拟器中),我们使用 7 位定点数来表示 0∼100 之间的路径置信度值,并对这些定点数执行乘法和除法。此外,由于 Cdelta 和 Csig 是 4 位饱和计数器,我们可以使用一个简单的 16x16=256 条目查找表来存储所有可能的除法结果,这使我们能够完全删除昂贵的除法器模块。此外,额外的计算延迟可以被隐藏,因为 SPP 可以在 L2 缓存等待 DRAM 服务需求未命中时在后台计算路径置信度
如果预取器观察到以下条件之一,SPP 会停止预取:1) 路径置信度 Pd 较低。 2) L2 读取队列资源太少。
Page Boundary Learning
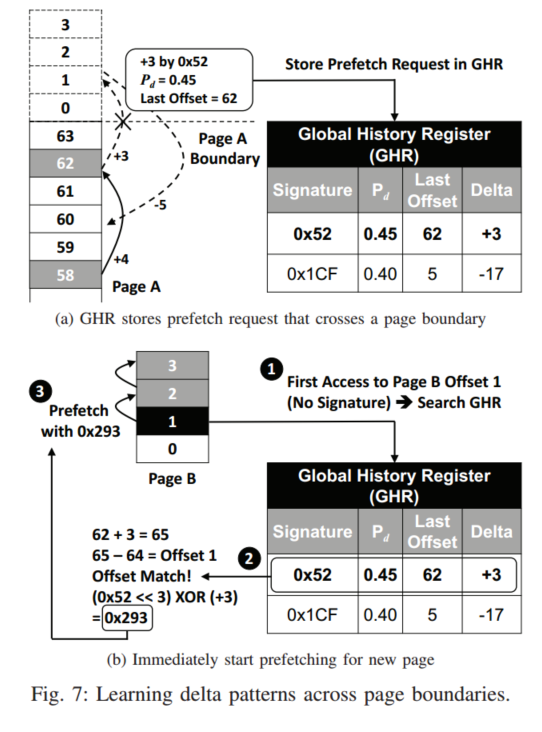
边界预测被存放到一个8entry的条目中,这个GHR存储当前的签名,路径置信度,以及偏移和delta,页面A发生跨页预取,那么会在新页面B访问GHR,匹配offset相等的,
也即是发生跨页时:
- 写入跨页请求,然后这个请求其实是B的offset为1的访问,此时访问GHR,发现匹配值,然后生成页面B的签名
Prefetch Filter
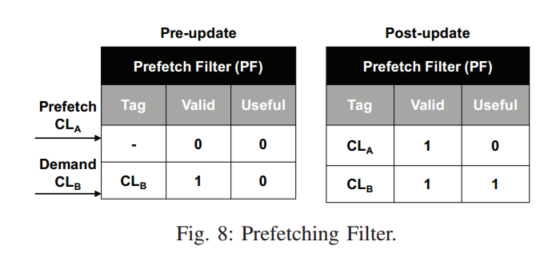
SPP总是先检查PF,然后再发出预取,如果PF已经包含一个缓存行,说明这个缓存行已经被预取,预取请求会被丢弃,当缓存行被替换,会重置有效位来清除条目
通过在每个过滤器条目中添加一个有用位,PF 还可以近似预取精度。SPP 有两个全局计数器,一个用于跟踪预取请求的总数 (Ctotal),另一个用于跟踪有用预取的数量 (Cuseful)。每当 SPP 发出未被过滤器丢弃的预取时,Ctotal 计数器就会增加。有用的预取由 PF 中命中的实际 L2 缓存需求请求检测到,这会增加 Cuseful 计数器。为了避免每个有用的预取行增加 Cuseful 超过一次,我们在 PF 条目中设置了一个已用位,以防止重复计算。此过滤器跟踪的全局预取精度用于公式 3 中的 α,以限制路径置信度值。

MLOP
Multi-Lookahead Offset Prefetching
摘要
讲的就是MLOP集timelineness和coverage于一体,并且可以弥补BOP只能预测一个offset,MLOP使用一个轻量级的硬件结构,由一个小存储器和一个简单的逻辑组成,用于识别在不同预测前瞻下可以覆盖特定缓存未命中的预取偏移量。基于此,MLOP为预取偏移量分配分数,并为每个前瞻选择分数最高的偏移量来发出预取请求。我们评估并比较了MLOP与各种最近的先进数据预取器,并表明我们的提议比没有数据预取器的系统提高了30%的系统性能,比之前性能最好的数据预取器提高了4%。
提议
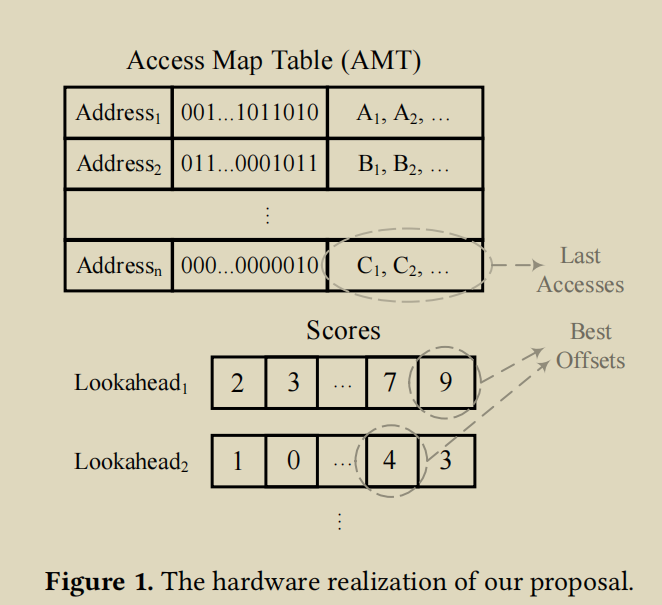
偏移量在前瞻级别X的分数表示预取器能够预取访问的次数,至少在发生前X次访问,例如,偏移量在前瞻级别1的分数表示预取器能够预取任何未来访问的次数
AMT中存放的是一个一个region的memory访问情况 每个region对应一个entry, entry中存储一个bit vector, 表示每一个位置是否被访问过了。 此外,每个region还会有一个history queue。以queue的形式存最近k个访问的offset,然后每个位向量都有level个级别的历史访问顺序。
因为MLOP有多个lookahead level, 每个level有自己的最佳offset。因此,MLOP开了level个score table, 记录当前level每个offset的得分
为了在前瞻级别1更新偏移量分数,每当发生访问时,我们找到其对应的位向量(使用其高位来搜索AMT),然后根据位向量信息,识别可以预取该访问的偏移量,并相应地增加这些偏移量在第一前瞻级别的分数。最后,我们在AMT中设置当前访问块对应的位。更新高位的分数需要先屏蔽低位的访问
说实话他这个论文比较空,建议读ppt
MEEK
MEEK:Re-thinking Heterogeneous Parallel Error Detection Architecture for Real-World OoO Superscalar Processors
芯片检测错误关键就是增加冗余去检测错误,大致可以分为三种,本文采用的是物理冗余

摘要
我们构建了首个全RTL设计的MEEK,并将其集成到一个开源SoC中,从微架构和指令集架构(ISA)到操作系统和编程模型。我们识别并解决了之前工作中被忽视的瓶颈和错误,并证明MEEK能够在可承受的开销下实现微秒级的检测能力。通过在协同设计的硬件-软件层之间权衡架构功能,MEEK仅对成熟的乱序超标量核心进行了轻微的改动,简化了协调软件层,并且只需要几行操作系统代码
介绍
硬件故障,无论是永久性的还是瞬态的,都会导致系统异常和执行错误,随着现代处理器中晶体管数量的增加和工作电压的降低,这种情况变得更加普遍[1]、[2]、[3]、[4]、[5]。为了减轻硬件故障引起的错误,存在从错误代码到容错架构的保护机制。检测始终是关键:一旦检测到错误,系统可以转换到安全状态,从而采取纠正措施(例如系统恢复或故障隔离)。
根据行业的全球安全标准,例如汽车的ISO26262[6]和航空电子的DO-178C[7],硬件故障必须在升级为危险之前得到解决,即在容错时间间隔(FTTI)内,通常以毫秒为单位[8]
软件机制(例如多线程 [4] [9] 和software scanner [10] [11])通常会导致显著的性能下降或提供有限的故障覆盖范围 [12],这使得它们不足以满足需要严格可靠性标准的处理器(例如ISO26262中的ASIL-D [6])。硬件机制通常采用一个专用核心来执行程序副本(lock-step),从而在每个时钟周期比较核心的引脚(例如锁步 [13] [14] [15])。通过在单独的同步核心上重放所有内容,并在信号级别进行运行时验证,实现了全覆盖和实时保证。尽管双核心和三核心锁步已经在许多生命关键应用场景中的微控制器级处理器核心中得到成功应用 [16] [17],但由于能量、面积和功耗成本过高 [18] [19] [20],它们已被证明对于乱序超标量核心不切实际。
异构并行错误检测 作为一种有前途的替代方案,异构并行错误检测 [21] [22] [2] 利用强归纳法,将运行在乱序超标量高性能核心(大核心)上的软件程序划分为多个离散段,使用寄存器检查点(RCPs),并在一组较小的能效核心(小核心)上重新执行这些段以进行验证。为了重放内存和其他不可重复的操作,从程序流中提取相关指令(例如load和store)的addr和data,在大核心的commit阶段生成加载和存储操作的分区分布式日志。当段的日志填满,或指令超时,或陷入内核模式时,会触发一个新的RCP,相应的小核心开始验证从开始RCP(SRCP)到结束RCP(ERCP)之间的段。通过重叠验证任务,小核心集体提供了足够的计算能力来跟上大核心的步伐,确保全覆盖且开销低 [21]。(很像difftest)
这使大核心上的应用程序线程可以使用RCPs进行分段,并在任何小核心上使用任何数量的检查线程进行重放和验证,同时仍然允许其他线程在它们上面执行(图1)
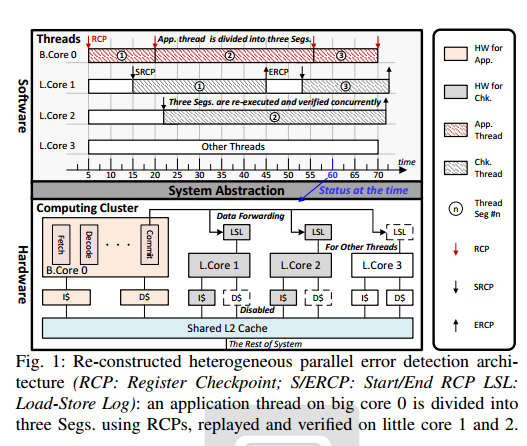
II. MEEK:一种CPU/OS协同设计方法
为了在保持高性能的同时以最小的复杂度实现MEEK,我们必须在硬件和软件之间进行仔细的设计选择分区(图2)。一方面,我们别无选择,只能在硬件中实现加载和存储日志记录,用于在小核心上重放执行
如果需要重放大核上的程序,必须得记录load和store,因为load和store在重放时可能被大核改变,从而导致错误
另一方面,由于小核心与大核心异步执行PTW,操作系统必须在某种程度上感知它们,因此我们让操作系统完全控制它们的调度,避免在硬件中实现不在性能关键路径上的复杂决策,并允许小核心执行标准进程。
与其采用完全透明的接口并避免在硬件中实现昂贵的错误纠正 [22],程序通过在main之前插入的协调函数与MEEK-ISA交互,这些函数请求操作系统提供检查资源,验证检查输出,并在需要时调用故障处理代码。为此,我们对大核心的微架构进行了轻微的修改,在提交阶段插入了一个只读观察通道(图2 a),收集大核心的状态数据(即架构、控制和状态寄存器文件)以及RCP之间的运行时数据(内存和其他不可重复操作的地址和数据)。
我们构建了一个专用的数据结构(图2 b),选择性地广播/路由提取的数据到小核心,最小化数据通信的反压。在小核心中,接收到的数据被缓冲在加载存储日志(LSL)中,替换程序重放期间的L1缓存,允许小核心重置其架构状态到给定的SRCP,重放SRCP和ERCP之间的精确指令,并在ERCP处使用不同类型的数据验证执行的正确性(图2 c)。
我们的ISA接口(图2 d和表I)(重新)配置小核心的检查特性,即操作模式(应用程序或检查模式)以及它们与大核心的关联:小核心最初以应用程序模式运行,作为标准核心执行程序。当与大核心关联时,可以部署并运行检查线程在检查模式下。应用程序和检查线程仍然在小核心上共存,操作模式仅在上下文切换时切换。
检测方法。错误检查通过检查线程并行化(图2 b):应用程序线程使用RCPs进行分段,当目标LSL已满、指令超时或陷入内核模式时,这些段由检查线程重新执行,假设所有先前的段都是正确的。重新执行后,检查线程将其架构寄存器与应用程序线程在相同RCP处提供的寄存器进行比较。如果寄存器匹配,则认为该段是正确的。如果所有段都通过检查,则认为整个执行是正确的。然而,在ERCP处无法验证内存操作。在重新执行期间,直接在LSL中比较内存操作的地址和数据。类似的设计方法用于控制和状态寄存器(CSRs)以验证不可重复的指令。
这里讲述了检查线程的触发条件:LSL满,指令超时,陷入内核模式
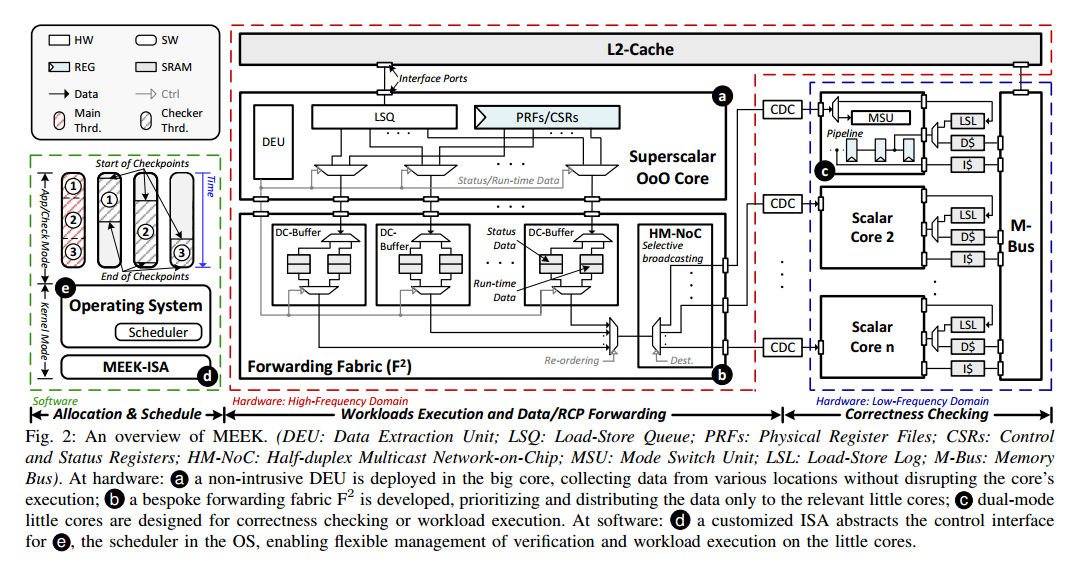
III. 微架构
特别是在数据传输方面。我们识别并缓解了之前工作 [21] [22] [26] 中缺失的关键瓶颈,由于缺乏RTL实现,这些工作仅通过抽象模拟进行。我们还识别了冗余数据存储方面的低效,其中大部分转发路径所需的信息已经在提交时间之前缓冲在核心内部,这意味着不需要专用结构;相反,我们可以从现有结构转发数据。尽管存在瓶颈,我们证明可以从一个成熟的异构SoC构建MEEK的微架构,只需进行少量改动,避免大量的工程工作。我们将MEEK构建到一个开源异构SoC(Rocket Chip [24])中,该SoC既包含高性能核心(BOOM)也包含能效核心(Rocket)。我们利用Rocket Chip来证明我们的方法适用于其他异构SoCs,例如ARM的big.LITTLE [27] 和Intel的P-和E类核心 [28]。
A. 乱序超标量核心(大核心)
程序重放需要收集状态数据和运行时数据:PRFs,CSRs,memtrace,在提交阶段提取,并且必须在之后指令提交前提取完成
这里最多两个周期提取?否则可能会被覆盖()
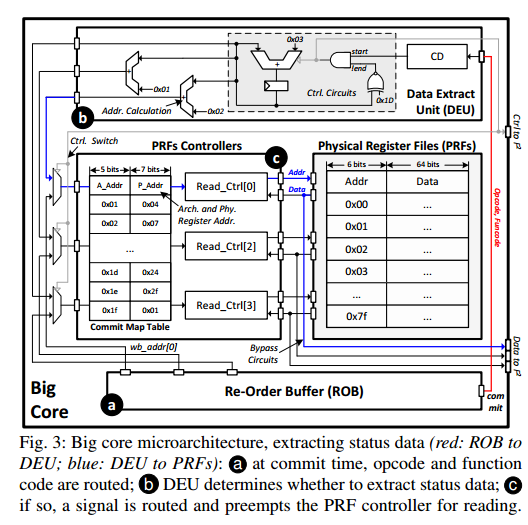
鉴于此,我们开发了一个非侵入式数据提取单元(DEU)(图3),包含提交检测器(CD)、控制电路和旁路电路,注入到PRFs、CSRs和LDQ。CD监控来自ROB的指令提交,并选择旁路电路以在RCPs或RCP之间的运行时数据处提取数据。这使得可以在不增加额外缓冲区或更改现有寄存器路径的情况下及时提取数据。
PRF示例。图3展示了使用PRFs(用于收集RCPs)的微架构示例,其中DEU与ROB、PRFs和F2进行交互。在每条指令提交时,操作码和功能码从ROB(图3 a)路由到CD,允许CD确定是否提取数据(图3 b)。如果到达RCP,则控制电路生成一个信号,抢占PRF控制器以读取寄存器文件并将其转发到F2(图3 c)。PRF控制器在ROB和DEU之间多路复用,DEU在需要时具有优先访问权,从而实现数据的立即读取并防止数据被覆盖。CSRs和LSQ。为CSRs实现了类似的微架构,允许从任意CSR地址提取数据。相比之下,由于LSQ的顶部始终持有最近提交指令的数据,当CD决定转发运行时数据时,旁路电路直接从队列顶部传输,最小化了设计复杂性并减少了数据争用。
大核主要工作就是提取出有效的状态
B. 转发结构(F2)
由于大核心的并行提交产生的大量运行时数据,与RCPs的频繁到达(通常以突发形式出现)发生拥塞,特别是在核心在RCP边界处提交多个加载或存储指令时,需要在一个周期内进行多次数据传输并需要高吞吐量。我们设计了F2,带有双通道缓冲区(DC-Buffers)和半双工多播片上网络(HM-NoC),用于存储和路由提取的数据(图2 b)。每个提交路径连接一个DC-Buffer,为状态和运行时数据添加独立的FIFO。这确保了所有运行时数据可以在提交的同一周期内存储,即使同时生成状态数据,避免了数据需要在原始核心设计中更长时间地存储在核心内部结构中。
HM-NoC使用半双工(1到N)曼哈顿网格。为了实现足够高的吞吐量,这个NoC允许每周期传输两个数据包,同时保持顺序。
转发策略。与之前的工作不同,之前所有段的数据在RCP处缓冲并集体转发,F2允许在收集时立即传输和使用数据,使小核心能够更早地重新执行。此外,由于相同的状态数据可能被两个小核心需要(分别用作SRCP和ERCP),当小核心能够接收数据时,数据会被选择性地广播到小核心,消除了冗余事务。
C. 顺序标量核心(小核心)
为了实现线程级错误检测并允许检查线程和应用程序线程共存,小核心的微架构必须支持不同的操作模式并抽象出一个软件控制接口。
因此,我们升级了小核心的微架构(图4),增加了模式切换单元(MSU,图4 a)和加载存储日志(LSL,图4 b)。MSU作为控制引擎,LSL缓冲接收到的数据包。在复制大核心的状态时,MSU记录小核心的架构寄存器文件并用LSL中的状态数据替换它们。MSU还通过检查运行线程的线程ID(TID)与检查线程的TID来管理小核心的操作模式。当调度检查线程时,MSU切换操作模式,此时加载和不可重复指令的结果从LSL中获取。鉴于小核心以顺序方式访问LSL,我们使用双路FIFO实现了LSL,比传统的组相联架构更简单。
小核直接从这个fifo读取memtrace
流水线集成。图4展示了LSL和MSU如何集成到一个5级流水线的小核心中。LSL被添加到内存访问(MA)阶段(图4 b),通过部署一个复用器并将其连接到加载存储单元(LSU)的地址端口。复用器根据操作模式(由MSU返回)选择性地将内存访问路由到LSL,并将虚拟索引和物理标签(由TLB返回)组合到LSL的地址端口。此外,在MA阶段集成一个解复用器,将读取的数据定向到后续阶段。在指令解码(ID)阶段部署了一对复用器和解复用器,以允许记录和更新架构寄存器。最后,我们在MA阶段部署了一个迷你解码器(Mini-D,图4 c),以区分传统的RISC-V和MEEK-ISA。
IV. 指令集架构、操作系统和编程模型
为了减轻微架构的复杂性,我们在软件支持方面进行了有限的改进,这些改进更简单、更容易验证或对正确功能是必要的。我们详细说明了ISA支持,以添加软件控制块来增强具有容错支持的程序。通过在内核中进行几行代码的更改,它可以调度和保留检查线程的资源,同时允许其他线程的标准调度和上下文切换。
A. ISA支持

新的ISA分为两类(表I),用于大核心(b.x())和小核心(l.x())。我们使用b.hook()设置大核心和小核心之间的关联,然后使用b.check()通过打开/关闭DEU来启用/禁用检查功能。对于小核心,l.mode()设置其操作模式,一对l.record()和l.apply()从给定来源记录和应用架构寄存器。为了将PC重定向到应用程序线程,我们开发了一个l.jal(),从原始跳转指令修改而来,目标地址有所更改。通过将检查点结束视为类似分支的操作,流水线处理了PC更改的控制危害,无需进一步更改。最后,l.rslt()指示是否检测到RCP不匹配。由于b.hook()和b.check()可能导致小核心的使用争用,l.mode()可能导致意外的内存访问错误,因此它们是特权指令,通过OS syscall执行。
B. 检查线程及其编程模型

检查线程在初始化应用程序线程时,通过使用构造函数和析构函数 [35] 增强应用程序线程的main函数(算法1:第14行)。由于检查线程依赖于LSL中的数据来重放内存操作,而LSL使用FIFO设计,因此上下文切换的日志是不可取的。因此,在调度时间,LSL被保留用于单个检查线程(算法1:第12行),即使多个线程可以调度到核心上。一旦LSL被保留,只有与关联的检查线程相关的数据才会被转发,直到重执行完成。同样,固定到特定应用程序线程的检查线程在重执行完成之前不能迁移。由于每个检查点的大小是有限的(最多5000条指令),并且所有权在每个检查点结束时返回给OS以供重新分配,因此这不会导致资源饥饿。编程模型。我们基于新的ISA开发了检查线程,确保最小的编码工作量:最初,使用l.record()记录当前的架构寄存器状态(算法2:第15行),允许核心在验证后返回。然后,创建一个忙等待循环,等待LSL中的状态数据到达(算法2:第19行)。接收到后,调用l.apply()以根据应用程序段修改核心的架构状态(算法2:第20行),并调用l.jalr()将PC重定向到复制的目标(算法2:第21行)。最后,使用l.rslt()返回验证状态。如果检测到错误,则触发中断以通知OS采取纠正措施(算法2:第16-18行)。
大小核心都有可能陷入模式
C. 操作系统内核及其验证
有了新的ISA,内核修改可以限制在调度程序中的上下文切换函数内,允许配置检查功能并管理检查线程 [36] [37]。根据大核心和小核心的不同角色,应用程序线程和检查线程的上下文切换被不同地修改。在从应用程序线程进入上下文切换时,调用b.check(DISABLE)禁用检查功能(算法1:第3行),在离开上下文切换时,调用b.check(ENABLE)重新启用它(算法1:第20行)。此外,如果调度了一个新发布的线程执行,则使用b.hook(core_index, next→checker_index[x])将其与小核心关联(算法1:第10-13行)。对于应用程序线程的上下文切换,唯一需要的修改是使用l.mode()切换小核心的操作模式(算法1:第3和7行),其余部分保持不变。内核验证和死锁解决。由于MEEK在线程级别启用错误检查,OS内核可以被视为一个专用的应用程序线程,并像其他应用程序线程一样进行验证。然而,在开发过程中,我们观察到一个之前文献 [21] [22] [26] 中遗漏的死锁,这是由于缺乏对OS的评估。因为检查线程可能会阻塞主线程,直到小核心完成,由于SRAM日志是有限的,这种行为表现为小核心持有的锁,而大核心需要。如果出现相反的情况(大核心持有锁,例如软件互斥锁,小核心需要),则会导致死锁(图5 a)。
这个死锁可以通过使检查线程永远不需要获取锁来解决。确保检查线程至少比主线程落后一条指令,这意味着后者会首先到达故障。通过在I/O上进行同步,可以防止写入可能被未完成的检查线程使用的页面(图5 b)。
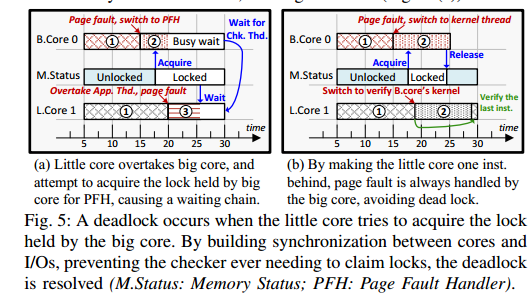
V. 评估
A. 性能开销
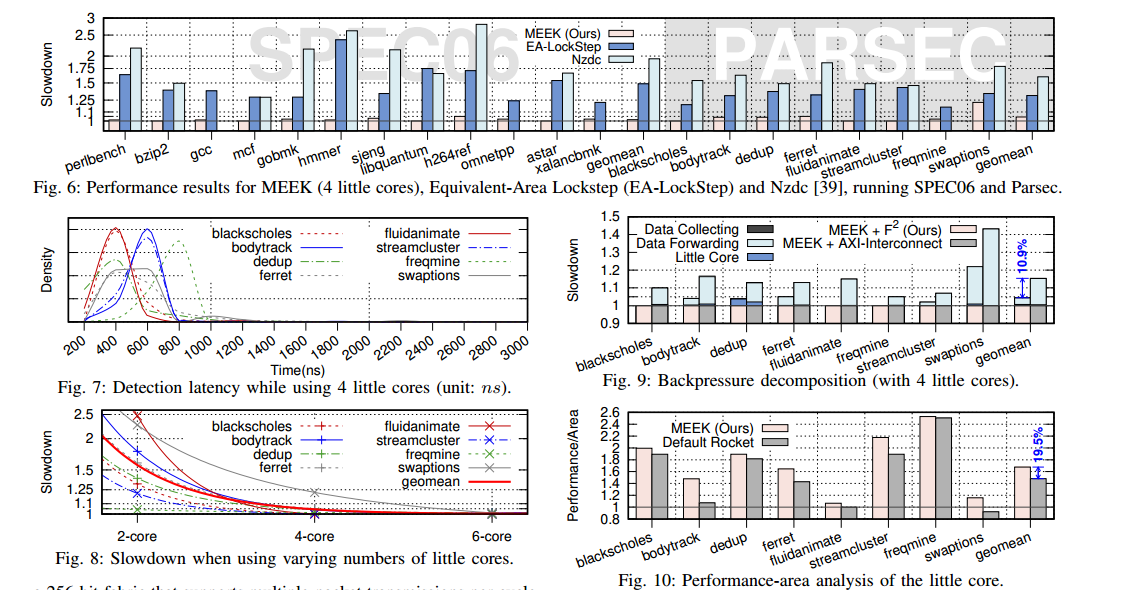
图6显示了在MEEK中运行SPECint和Parsec时大核心的减速情况,与在LLVM中实现的软件基对应物(Nzdc [39])和等效面积锁步(EA-LockStep)进行比较。选择Nzdc进行比较是因为它是唯一可用的开源软件机制,而锁步是最广泛使用的硬件机制。然而,简单地在锁步中复制核心会消耗大核心面积的两倍,同时实现与普通核心相同的性能,导致无趣的比较。因此,我们通过线性插值每个可配置的BOOM组件,创建了一个比较器,使两个核心的组合面积与MEEK的面积开销相匹配。在所有情况下,MEEK配置为使用四个小核心。使用四个小核心足以执行SPEC,开销为1.4%,Parsec为4.4%(几何平均值)。对于所有工作负载,除了swaptions,观察到的减速低于5%。然而,swaptions的减速最高,为22%,这是由于频繁的除法,Rocket核心的除法器性能显著低于BOOM核心。对于比较器,Nzdc在Parsec上引入了几何平均值60.2%的开销,在SPEC上引入了94.2%的开销,反映了其软件实现的局限性。硬件对应物EA-LockStep在Parsec上引入了几何平均值31.2%的开销,在SPEC上引入了48.7%的开销,大约是MEEK的6.1倍和33.7倍,证明了MEEK的性能-面积优势。
B. 检测延迟
为了检查检测延迟,我们在连接到大核心的F2中注入了转发数据的错误,例如内存操作的数据和地址以及架构寄存器数据,模拟硬件故障,同时不干扰大核心的正常执行。对于每个工作负载,随机生成了5000到10000个故障,并且检测延迟的密度如图7所示。每个分布都有一个长而非常薄的尾部延伸到右侧:平均检测延迟低于1微秒,而最坏情况下的延迟是平均值的5到10倍,最高可达2.7微秒(在ferret中)。尽管故障注入是随机的,但大量的样本点(总计超过100,000个)表明,3微秒足以覆盖超过99.9%的硬件故障,这比ASIL-D合规所需的毫秒级FTTI要求低几个数量级。
gem5在fs模式运行spec2006
假定已经安装了gem5,并且编译了RISCV的gem5.opt
环境准备
编译m5term,这个是连接终端的
1 | cd gem5/util/term |
编译m5
1 | cd gem5/util/m5 |
获取linux内核
获取riscv linux内核和img映像,获取方法
- 官网资源,使用riscv-disk-img,内核使用bootloader开头的
- 使用buildroot一键构建内核和img
- busybox构建img,然后自己编译linux内核
修改img文件
添加自己的文件
1 | sudo mkdir -p /mnt/rootfs |
然后我们还要去设置img的/etc/inittab,将 ::respawn:/sbin/getty ...这一行修改为
1 | ::respawn:-/bin/sh /root/init.sh |
也就是开机直接启动/root/init.sh
之后创建/root/init.sh
1 | /root/m5 checkpoint |
这个意思就是创建checkpoint,然后运行从readfile读入的脚本,运行完成退出,其中readfile的文件来自–script参数
生成checkpoint
首次运行需要生成checkpoint
1 | build/RISCV/gem5.opt configs/example/riscv/fs_linux.py \ |
生成了checkpoint后,我们会在gem5的m5out文件夹下发现cpt前缀,数字后缀的文件夹,该文件夹就是生成的checkpoint,之后我们均从该checkpoint运行benckmark
恢复checkpoint
1 | build/RISCV/gem5.opt \ |
但是在恢复运行时目前遇到这个问题(即使使用O3单独运行也会出现这个问题):
src/cpu/o3/fetch.cc:603: warn: Address 0xffffffe000004400 is outside of physical memory, stopping fetch
在issue找到了,但并没得到有效信息
论文移植
代码移植问题
- 将1.9.1的chipyard版本移植到1.17.1的firesim
- 直接使用1.17.1版本的chipyard
- 是否可以得到老师代码修改记录,这样可以最小限度移植
- 是将MEEK代码直接复制到chipyard,还是只将修改部分的代码复制到chipyard
修改1
修改rocket chip 的main/scala的packge.scala
1 | package freechips |
修改2
value io is not a member of freechips.rocketchip.diplomacy.LazyModuleImp
将
1 | lazy val module = new LazyModuleImp(this) { |
改为
1 | lazy val module = new Impl |
gem5部分
编写了se跑spec2006的脚本,目前需要给输入参数加入绝对路径
明天会编写fs跑spec2006的脚本,主要实现思路就是设置一个checkpoint,然后将所有benchmark打包进去,每次运行完一个benchmark就会poweoff,然后运行下一个(不知道是否可以并行)