FDIP
具体微结构
首先先翻译一下:
在[14]中,我们研究了分支预测器与指令缓存的解耦。为了提供解耦的前端,提取目标队列(FTQ)用于桥接分支预测器和指令高速缓存之间的间隙。每个周期,分支预测器都会产生一个提取目标块预测,并将其存储在FTQ中,最终由指令缓存使用。FTQ提供允许分支预测器和指令高速缓存自主操作所需的缓冲。当分支预测器由于高速缓存未命中或指令缓冲区已满而暂停时,FTQ允许分支预测器在指令高速缓存之前工作。如果指令高速缓存是多端口的,则可以在单个周期内消耗多个有效的FTQ条目,直到端口耗尽。
任何分支预测器(基本块目标缓冲器[22]、提前两个块预测器[15]或提取目标缓冲器[14])都可以放在FTQ之前,并产生要由指令高速缓存消耗的提取块地址。正是FTQ允许分支预测器在指令缓存之前运行。
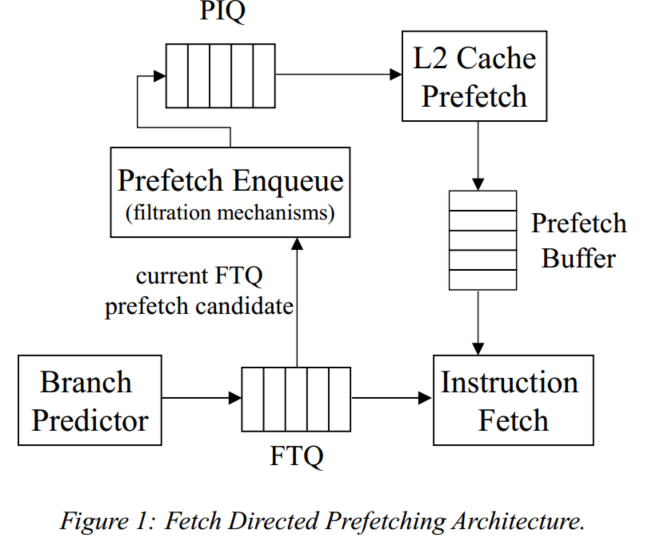
FTQ包含一个提取块,当数据缓存或者指令缓存未命中,从PIQ开始预取。
Prefetch Buffer 的工作机制
在论文提出的 Fetch Directed Prefetching (FDP) 架构中,Prefetch Buffer 是一个关键组件,用于临时存储通过分支预测器前瞻生成的指令缓存块。以下是其具体工作原理和设计细节的详细解析:
1. Prefetch Buffer 的核心作用
- 目标:通过提前将未来可能需要的指令缓存块加载到缓冲区,减少指令缓存未命中带来的延迟。
- 数据来源:由 Fetch Target Queue (FTQ) 中的候选预取地址生成。
- 与指令缓存的协作:在指令缓存查询时,Prefetch Buffer 并行查找;若命中,则直接将缓存块插入指令缓存。
2. Prefetch Buffer 的结构设计
-
FIFO 队列结构
:
采用先进先出(FIFO)的队列结构,新预取的缓存块插入队尾,最旧的块在队首。
容量:论文中未明确指定具体条目数,但提及使用类似流式缓冲区的设计(例如 4 条目或更多)。
条目内容:每个条目存储一个完整的指令缓存块(如 32 字节)及其地址标签。
替换策略:当缓冲区满时,新预取请求需等待旧条目被消费或替换。
3. 预取流程的触发与管理
-
预取地址的生成
:
FTQ 中的每个条目包含多个候选预取地址(每个地址对应一个缓存块)。
这些地址通过分支预测器生成,并标记为“候选预取位”(Candidate Bit)。
Prefetch Instruction Queue (PIQ)
:
- 候选地址首先进入 PIQ 等待调度。
- 优先级:指令缓存未命中 > 数据缓存未命中 > 预取请求。
- 当 L2 总线空闲时,从 PIQ 中取出地址发起预取请求。
4. 预取缓冲区的操作流程
1.
预取填充
:
- 从 PIQ 获取地址后,向 L2 缓存发起预取请求。
- 预取的数据块存入 Prefetch Buffer 队尾。
2.
指令缓存查询时的并行查找
:
- 当指令缓存需要访问某个地址时,同时查询指令缓存和 Prefetch Buffer。
- 若在 Prefetch Buffer 中找到匹配项(命中):
- 命中条目(通常是最旧条目)被移出缓冲区。
- 该缓存块直接插入指令缓存,替换原有未命中的块。
3.
分支误预测的处理
:
- 发生分支误预测时,FTQ 和 Prefetch Buffer 会被清空(Flush),确保预取路径与正确执行路径一致。
如果cache未命中,且预取缓冲区有数据,此时如何解决?
论文并未提出,不过如果命中可以直接从缓冲区取出数据,类似于压缩队列