regfile_prefetch
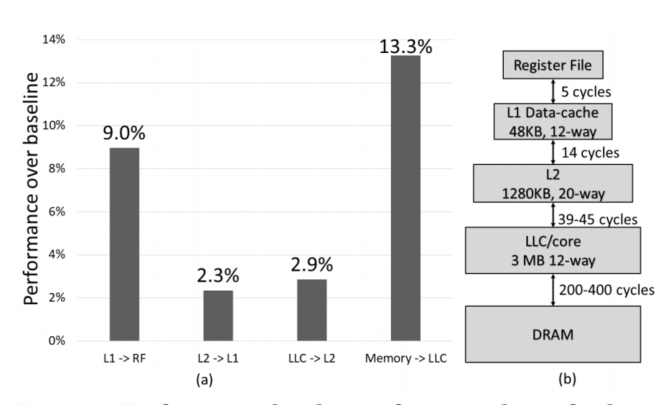
该论文首先去给出改进那部分对性能提升最大,首要为LLC,其次就是L1-RF
3. REGISTER FILE PREFETCH (RFP)(核心技术)
执行时的相应加载会检查预测地址是否与加载地址匹配,如果匹配,则预取的数据会被提供给依赖项,加载过程完全绕过缓存。否则,加载会像传统的OOO管道一样进行缓存访问
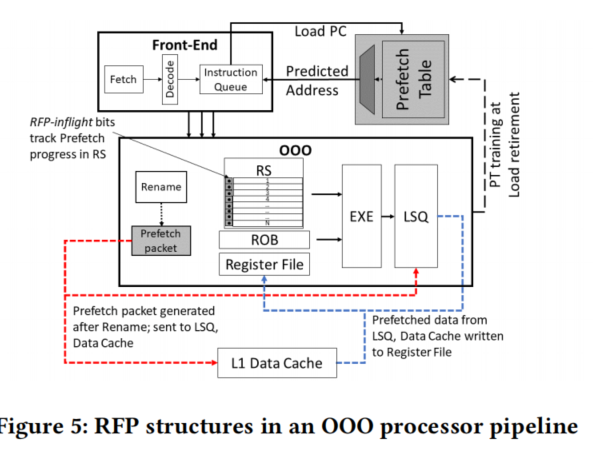
3.1 设计原则
- Timeliness(及时性):
- 选择在重命名阶段后触发预取(而非前端),因:
- 63%的负载在分配时操作数未就绪,提供预取时间窗口。
- 已知物理寄存器ID(
prfid),可直接写入数据。
- 选择在重命名阶段后触发预取(而非前端),因:
- Bandwidth(带宽):
- 正确预取时无需二次验证,节省L1带宽;错误预取仅需重新访问L1。
- Accuracy(准确性):
- 低置信度预测即可触发(错误代价低),优先服务常规负载。
我们使用负载PC查找PT,以标记符合RFP的负载。当加载被标记为RFP合格时,该加载的预取包被发送到LSQ(加载-存储-队列)和L1高速缓存以进行进一步处理。
预取包包含要预取的虚拟地址和预取数据要写入的加载的物理目的寄存器id (prfid)。请注意,指令的prfid只有在寄存器重命名后才知道。因此,寄存器重命名后会立即触发预取请求。严格地说,prfid可以在RFP管道中稍后提供,因为只有写回时才需要它。PT查找可以在管线中较早发生,在重命名之前,并且我们不期望它在时序关键路径上。
预取包首先与其它负载/RFP请求仲裁对L1端口的访问。当针对常规负载进行投标时,我们给予RFP预取最低的优先级。这可以防止常规负载的延迟升级。RFP队列被组织成一个FIFO,旧的RFP请求比新的获得优先权。预取将从L1获取数据,并将其写入prfid的寄存器文件。
如何处理store?
为了保证正确性,RFP考虑了所有可能修改负载数据的存储。当一个RFP被发送到L1和LSQ时,它会扫描所有较旧的商店(按照先老后小的顺序),并将其地址与商店地址进行匹配。匹配时,它等待存储完成,并使用存储数据而不是缓存数据进行预取。如果存储的地址不可用(意味着存储还没有执行),我们依靠内存歧义消除(MD) [14]机制来决定RFP是需要等待存储还是跳过它
流水线简化
如果一个RFP请求未命中L1,我们允许它继续处理,并从较低级别的缓存中获取数据,类似于常规的按需加载。在DTLB未命中的情况下,我们为了流水线简化而丢弃RFP,因为TLB未命中需要很长的延迟,并且在这种情况下RFP将没有足够的剩余运行时间。