IPCP
IPCP算是一个混合架构的预取器
为什么要做这个预取?
每个PC都有自己独特的访存行为
举例:
例如,下面是SPEC CPU 2017基准测试中一个名为bwaves的IPA的L1-D访问模式(根据缓存线对齐地址):C0,C3,C6,C7,C9。
这个IP在大多数情况下遵循三的恒定步幅。在这种情况下,简单的IP跨距预取器可以提供高预取覆盖率。这是来自名为mcf的基准的IPB的另一个访问模式:C0、C1、C3、C4、C6、C7。这个IP的步幅模式是1,2,1,2,1。
在这种情况下,IP-stride预取器提供零覆盖,因为预取器不能达到高置信度
lbm和gcc等流基准中常见的另一种访问模式如下:IPC (C0、C2、C1)、IPD(C3、C6、C4、C5)和IPE(C9、C8、C7)。这是一个Global Stream。观察全局模式,我们可以看到所有的访问都是连续的,并且局限于一个小的内存区域。然而,基于程序顺序,它们的访问模式有点混乱。在这种情况下,许多像IPC、IPD和IPE这样的IP都跟随Global Stream。
显然,IP是独特的,可以根据其访问模式分为不同的类别。请注意,特定IP可以从一种访问模式移动到另一种访问模式,并且可以在一种或多种访问模式下保持活动状态
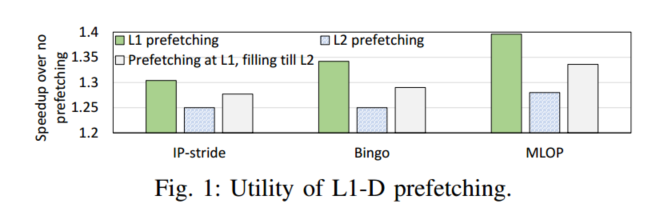
L1 pretch是对性能影响最大的
IPCP微结构
我们提出了一种空间IPCP,将IP分为三类。我们不跨页面边界进行预取,因为IPCP是一个简单的空间预取器,它在一个小区域(2KB和4KB)2内进行预取。
1. 常量步幅预取器(Constant Stride, CS)

目标场景:
处理仅由控制流驱动的规律性步幅访问。例如,循环中按固定间隔访问数组元素(如stride=3的访问序列C0, C3, C6, C9)。实现机制:
IP表(IP Table):记录指令指针(IP)的历史步幅和置信度(2-bit计数器)。
页地址处理:通过
last-vpage和last-line-offset检测跨页访问,计算跨页步幅(如从页末尾offset=63到下一页offset=0仍视为stride=1)。触发条件:当步幅置信度足够高时,预取地址为:
(
k为预取深度,默认3)。
优势:
低开销(仅需记录步幅和置信度),适合简单循环或数组遍历。
**Training phase:**IP的置信度达到一定值
Trained phase: prefetch_address=current_address+k×learned_stride ,注意,学习的IP在低置信度的情况下停止预取,并且在获得置信度之后再次开始预取
2. 复杂步幅预取器(Complex Stride, CPLX)
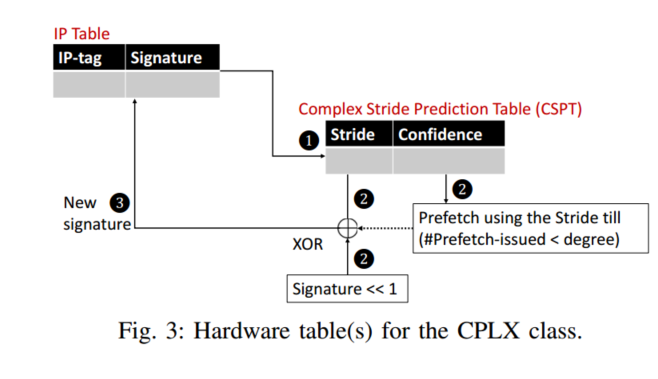
- 目标场景:
处理控制流与数据流耦合的非固定步幅,例如:- 非2的幂次内存布局(如结构体跨缓存行访问,步幅为
1,2,1,2)。 - 嵌套循环导致的步幅变化(外层循环步幅固定,内层步幅动态变化)。
- 非2的幂次内存布局(如结构体跨缓存行访问,步幅为
- 实现机制:
- 复杂步幅模式表(CSPT):记录IP的近期步幅序列(如7个历史步幅),通过签名匹配预测未来步幅。
- 置信度控制:低置信度时退化为NL(Next-Line)预取。
- 优势:
覆盖IP-stride无法处理的非规律性但局部可预测的访问模式,如不规则数据结构的遍历。
**Training phase: **每当IP看到相同的步幅时,置信度计数器就加1,否则就减1。此步距与现有签名进行哈希运算,并再次查找CSPT以发出预取请求。根据以下等式,将先前获得的步距添加到签名中:signature = (signature << 1) ˆ stride,请注意,我们将签名移位一位,以便能够适应高度复杂的步幅模式。因此,一个模式可以产生许多签名,但是我们在CSPT中没有观察到太多的碰撞,因为在同一时间点没有许多CPLX IPs
Trained phase: 每当签名指向步距时,并且如果置信度足够高(在我们的例子中≥1),复合步距被添加到高速缓存行以产生预取地址。这种预测一直持续到达到预取程度计数(degree)。如果置信度值为零,则使用上述等式将步距添加到签名,以预测下一步距(3),并且不进行预取。
其与SPP的区别:
我们发现,在有些情况下,IP驱动的复杂大步掌握着关键。(I)存储器访问(对于给定的IP)有时不是2的幂(跨高速缓存行的数据结构中的存储器布局),导致非恒定的步幅模式。例如,考虑一个8字节的高速缓存行,如果每第12个字节被访问,则访问产生如下步长:字节地址:0,12,36,48,72;高速缓存行对齐地址:0,1,3,4,6;步幅:1,2,1,2。(ii)另一种情况是通过不同级别的循环进行访问。
外部循环可以进行恒定步距访问(很容易被CS类捕获)。然而,内部循环可以进行不同的步幅访问(取决于外部循环的步幅),从而导致步幅模式中的颠簸。基于IP的CPLX可以利用这种模式。
此外,CPLX类侧重于复杂步幅的局部顺序(捕获控制和数据流),这与SPP看到的全局顺序(数据流)不同。请注意,SPP是为L2设计的高性能预取器,仅CPLX无法与SPP的效率相提并论(苹果与橙子)。CPLX的实现是非常轻量级的,因为它是一个L1-D预取器,并具有在L1发出预取的关键路径上减少延迟的额外好处(SPP必须通过使用逻辑或查找表来计算置信度)
3. 全局流预取器(Global Stream, GS)
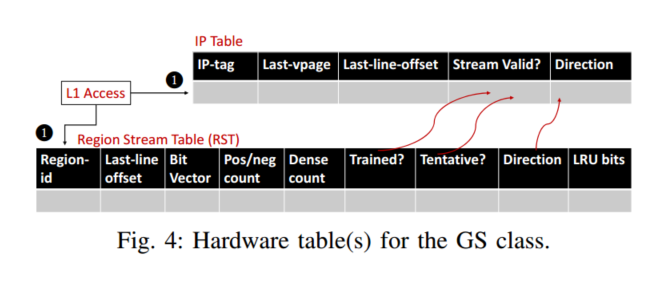
- 目标场景:
处理由控制流预测的全局数据流,即多个IP访问同一密集内存区域(如流式应用的连续但乱序访问C0,C2,C1,C3,C6,C4)。 - 实现机制:
- 区域流表(RST):
- 跟踪2KB区域内的访问密度(32-bit位向量记录已访问缓存行)。
- 当区域访问密度超过阈值(75%缓存行被访问),标记为“密集区域”。
- 方向预测:通过饱和计数器判断访问方向(正向/反向)。
- 跨区域预测:若前一个区域为密集区域,则新区域假设为密集(控制流预测数据流)。
- 预取策略:按预测方向连续预取
k个缓存行(默认k=6)。
- 区域流表(RST):
- 优势:
利用空间局部性,适合流式负载(如多媒体处理、矩阵运算)。
Training phase:
当一个新的region被访问,在RST分配一个入口,如果第一次访问这个cacheline,设置相应的 bit位,并且增加dense-count,last-line-offset也会被存储,
如果dense-count大于阈值,这个区域就是一个经常被访问的区域,此时trained bit会被set,注意,如果已经设置了位向量中的位,则计数器不会递增
RST通过饱和计数器统计stream方向,被初始化为2^n/2,通过找到连续两次访问cache的差异来获取方向,((the difference between the last-cache-line-offset and current access-offset within a region)(只有tentative或者trained置高才会去更新方向)
当遇到GS IP遇到一个新的区域,查看前一个访问的区域,如果前一个为密集的,新区域的tentaive会被设置,如果前一个region未设置trained,可能是该IP可能不具备GS特性了(可以防止强制缺失)
Trained phase:
如果trained和tentative被设置,我们认为IP为GS IP,设置IP table的stream_valid和direction,
这里的方向其实是决定预取地址从后向前还是从前向后,(这里主要就是为了timeliness)
整体结构
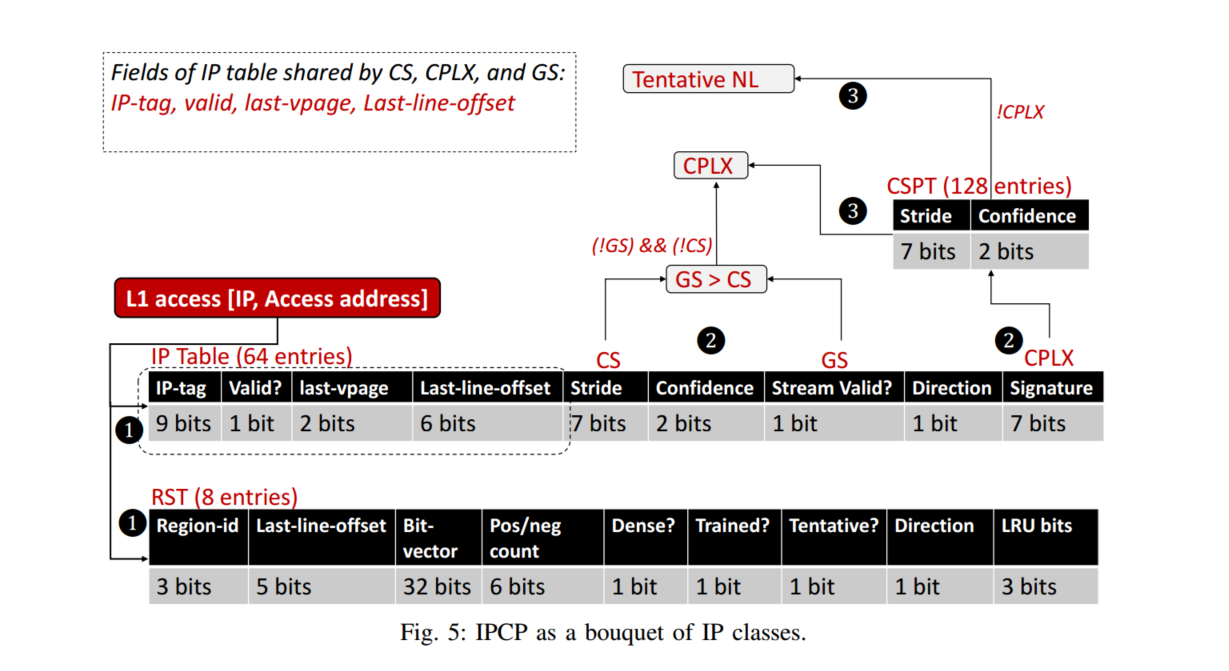
由于IP表是直接映射和标记的,决定保留哪个IP用于预取是一个挑战,因为匹配相同表条目的IP之间可能会有冲突,我们添加了一个额外的字段有效位来保持滞后(图5)。当第一次遇到一个IP时,它被记录在IP表中并设置有效位。当另一个IP映射到同一个条目时,有效位被复位,但前一个条目仍然有效。如果当看到新IP时有效位被重置,则表条目被分配给新IP,并且有效位被再次设置,确保在IP表中跟踪两个竞争IP中的至少一个。
如何解决CSPT表满的情况?
CSPT的stride为7bit,正好128个表项就可以覆盖全部,而且signature为7bit,可以直接索引cspt
IP_Table表多个IP映射同一个如何解决?
IP_TABLE是一个直接映射的表,包含64个条目。每个条目都有一个有效位(Valid bit),用于标记该条目是否有效。当一个IP第一次访问某个条目时,它的信息被记录在该条目中,并且有效位置为1。如果另一个IP映射到同一个条目,有效位会被清除(置为0),但之前的条目信息仍然保留。
具体实现:
- 当一个IP访问IP_TABLE时,如果该条目有效(Valid bit为1),则直接使用该条目中的信息。
- 如果该条目无效(Valid bit为0),则检查是否有另一个IP的信息仍然保留在该条目中。如果有,且新的IP需要使用该条目,则新的IP的信息会覆盖旧的IP信息,并将有效位置为1。
使用的预取优先级?
GS>CS>CPLX>NL
GS中的region_id和last-vpage区别?
rstable[cpu][i].region_id == ((trackers_l1[cpu][index].last_vpage << 1) | (trackers_l1[cpu][index].last_line_offset >> 5))
GS的tentative如何设置?
访问前一个region,如果region为trained,设置标志位,如果下一个新的区域访问,遇到该标志位会去置高tentative
GS的前瞻预取不能跨页面,否则直接退出
CPST和RST应该组织为数组结构,在电路上应该为CAM结构,而不是cache的用idx索引
为什么CPST要去根据sig取到地址
为什么他在遇到固定的stride时预取覆盖率不够
遇到这种模式,他会首先认为这个是stream模式,然后只预取前几个,而不是按照stride来预取