vec runahead
Vector Runahead
为什么前面有个Vector?
If runahead were instead to stall on cache misses to generate dependent chain loads, then it could regain performance if it could stall on many at once,传统的预取无法去预取间接访问内存的序列
解决的就是runahead的load chain预取
比如a[b[i]]

如图2(b)所示,假设所有存储器访问在高速缓存中未命中,PRE将发出对阵列a中第一个元素的访问的预取。依赖于该存储器访问的指令不能执行,因此对阵列B的访问和指针值不能被预取。当处理器在提前运行模式期间继续通过指令流时,它将命中对数组A中的第二个元素的访问,为此它将发出另一个预取;不幸的是,对B和数据值的相关访问不能被预取。接下来,对A中的第三个元素发出预取,依此类推。当启动提前运行模式的阻塞加载从主内存返回时,提前运行模式停止。此时,已经预取了对数组A的多次访问,但没有预取数组B的元素,也没有预取相关的数据值。
一旦回到正常模式,由于阵列b的第一次缓存未命中,处理器将很快再次停止。
现代处理器通常具有**硬件跨步预取器,**它应该能够预取对阵列A的跨步访问。如果是这样,当PRE访问阵列A中的元素时,它们将在缓存中命中,因此PRE能够发出对阵列B的第一级间接访问的预取请求,如图2(c)所示。在预运行模式下,PRE会将对阵列B的第一次访问(标记为“1”)转换为预取请求。但是不能预取从属数据值,因为它依赖于对B的访问。对A的下一次访问导致高速缓存中的命中,因为它被跨距预取器成功预取,因此处理器可以计算阵列B中的下一次访问的地址,并发出预取请求(标记为“2”)。同样,不能预取从属数据值。对A的下一次访问是高速缓存命中,然后处理器预取对B的第三次访问(标记为“3”),依此类推。总之,即使跨距预取使提前运行执行能够预取多一级间接寻址,它仍然不能预取第二级(或更高级)
而vec如图2(d)所示。
当启动向量提前运行模式时,对阵列A的多次访问被矢量化,即,在多个感应变量偏移处并行地推测性地发出相同的存储器操作。我们对尽可能多的可用向量宽度进行矢量化,在本例中为8。依赖于数组A中的值的指令也被矢量化,包括对数组B和相关数据值的访问。在提前运行模式期间对相关指令流进行矢量化,同时保持提前运行模式直到发出最后一个相关加载,这使得能够推测性地预取整个相关加载链。向量化提前运行指令流具有在发出下一批并行的相关存储器访问之前,从循环的多次迭代中同时发出相同的存储器操作的效果,等等。与原始指令流相比,这种对存储器访问的有效重新排序使得向量提前运行能够首先向A发出一批访问,然后向B发出一批访问,最后向相关数据值发出一批访问。换句话说,即使独立的内存访问在原始动态指令流中可能相距很远,矢量提前运行也会并行发出它们
优点
矢量化具有两个主要优点:(1)它大大增加了提前运行模式期间的有效提取/解码带宽,即我们一次提取/解码多个循环迭代,以及(2)它需要非常少的后端硬件资源,即向量提前运行模式中的向量指令对应于原始代码中来自多个循环迭代的多个标量指令,同时仅占用单个发布队列槽
具体设计
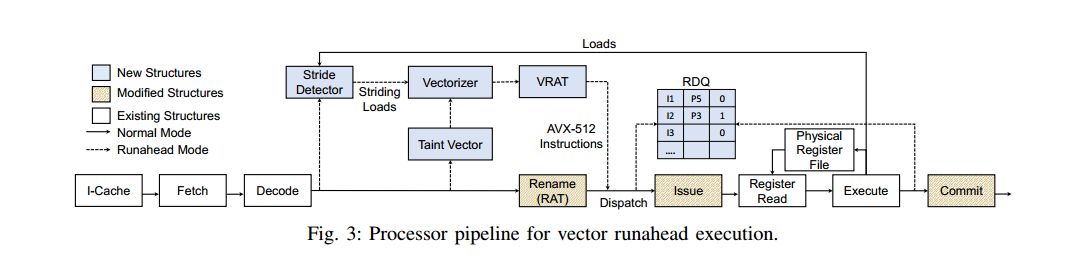
跨距检测器19用于查找代码中的常规访问模式,这些模式可用作“归纳变量”来生成代码的推测性矢量化副本。一旦我们进入向量提前运行模式(第III-C节),依赖于这种矢量化步长模式的指令就被污点向量跟踪(第III-D节),并被矢量化(第III-E节):地址计算算术运算被转换为向量单元运算,依赖者将自己加载到向量集合中。假设分支在每个矢量化副本上匹配,使用屏蔽来处理其他情况(第III-F节)。为了进一步将存储器级并行性提高到比单个向量加载所支持的水平更高的水平,我们设计了向量展开和流水线技术(第III-G节)来同时发出许多未来的加载。由于这导致旧标量指令和新向量指令之间的一对多关系,所以在前端引入向量寄存器分配表(VRAT)用于寄存器分配(第III-H节),在后端引入寄存器解除分配队列(RDQ)(第III-I节)。
Detecting Striding Loads
为了检测代码中的序列,我们可以从中生成归纳变量来对未来的内存访问进行矢量化,我们使用了一个简单的参考预测表[19,62],它会在每个加载指令执行后进行更新。这由加载PC索引,并且每个条目维护四个字段:(1)最后访问的存储器地址;(2)负载的最后观察到的步幅;(3)指示置信度的2位饱和计数器;以及(4)来自跨步加载的指令链中的最终相关加载的终止符或PC。
这里类似于分支预测器,学习stride,相当于一个简单的stride学习器
最后一个字段(4)是新的,是在一轮矢量提前运行期间填充的,它允许我们在矢量提前运行模式下完成所有有用的工作后提前终止(第III-J节)。
Entering Vector Runahead
在加载指令阻塞ROB的头部之后,当满足以下两个条件中的任何一个时,内核进入runahead模式:(1)ROB被指令填充;或者(2)发布队列被填充到其全部容量的80%。
除了为从分支错误预测中恢复而存储的检查点之外,向量提前运行还通过为前端(RAT)的每个条目存储一个检查点来检查PC和前端RAT。这标志着进入提前运行模式。当我们返回正常模式时,处理器状态将恢复到该检查点。
这里解释了如何进入runahead,以及进入runahead需要保存的状态
我们访问每个加载指令的步距检测器。直到我们达到一个跨步负载,或者如果不存在这样的跨步负载,向量Runahead与PRE [64]类似地执行,但是不使用其完全关联的停止切片表,向量Runahead消除了对其的需要,以避免在没有这种模式的情况下损害工作负载,并捕获向量Runahead稍后使用的任何标量依赖关系。
没stride load就和pre执行差不多
当我们解码一个跨越负载(置信度= 3)时,进入矢量提前运行模式开始。我们对跨越的负载进行矢量化,随后是依赖于它的指令序列。当检测到同一跨步负载的另一个动态实例时,或者从属链完成时,该过程终止(第III-J节)。我们称两个动态跨越负载实例之间的依赖指令为间接链。
Taint Vector
为了跟踪哪些操作(传递地)依赖于指令流中新矢量化的跨负载,我们使用污点向量(TV)。
这为每个架构整数寄存器提供了一个条目,并存储两个标志:(1)如果写入该寄存器的前一个指令是向量化操作(向量化位);以及(2)如果先前写入该寄存器的指令无效(无效位)。TV在runahead开始时是空的,因为它在runahead终止时被清除。
向量化位最初是为所发现的跨越式加载的目标体系结构寄存器设置的。无效位最初基于不支持的操作的目的地来设置,例如,那些将浮点操作作为输入的操作(其总是无效的,因此不需要TV条目)。
如果任何一个指令的输入寄存器被标记,那么目标寄存器也被标记。如果没有输入寄存器被标记,则目标寄存器的标志被复位。
没有设置位的指令作为传统的标量提前运行操作发出,并且在当前的矢量提前运行模式迭代中,相对于指令序列的矢量化副本被视为循环不变的。
具有无效位组的指令被丢弃,只有矢量化位组的指令被矢量化。
Vectorizing Instructions
在提前运行模式下执行的指令只在产生存储器访问时有用,它们的状态不在ROB中维护。因此,在runahead模式下不分配任何ROB条目。相反,我们使用更简单的寄存器解除分配队列[64] (RDQ,第III-I节)来处理寄存器可用性。由于浮点指令很少用于计算地址本身,我们忽略了这种指令(将它们和任何使用它们的指令标记为无效[57]),以及存储和任何已经在原始代码中矢量化的指令。
Control Flow
当向量化时,我们隐含地假设所有向量通道将遵循彼此相同的控制流模式。然而,当在向量提前运行模式下执行时,当通道遇到分支指令时,它们之间可能存在分歧。我们使用微操作将标量分支转换为八个向量通道的谓词掩码。由于向量提前运行不需要覆盖所有代码,因此我们仅使用第一个通道的结果来确定分支的方向,并屏蔽掉任何将采用不同控制路径的通道。这种屏蔽一直持续到我们终止vector-runahead的单次迭代。相比之下,单个向量提前间隔内的不同展开迭代(第III-G节)可以遵循独立的控制流
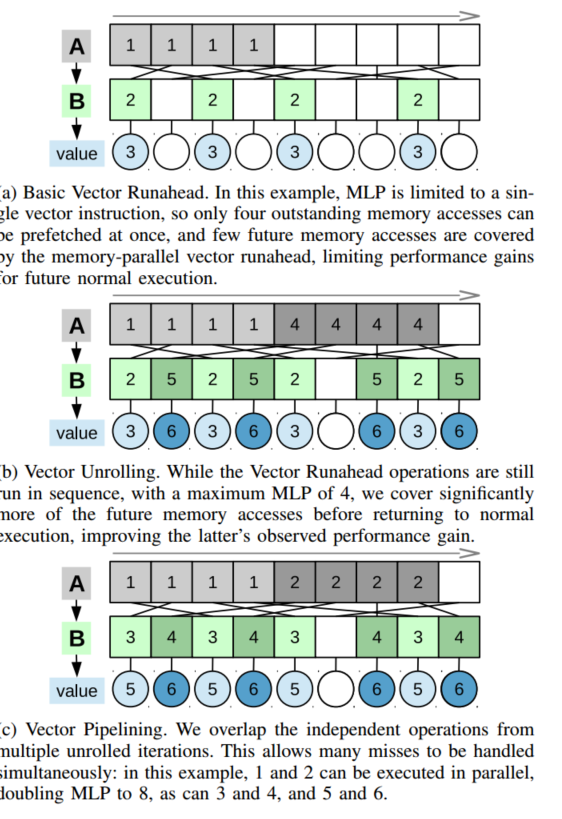
Vector Unrolling and Pipelining
向量提前运行使用两种技术:向量展开和向量流水线,通过增加提前运行的程度来提高性能,以允许比指令集体系结构本身支持的向量更宽的向量。
Vector RAT
我们在架构标量寄存器和重命名的物理向量寄存器之间有一对多的关系。对于深度为4的流水线,我们需要将一个架构标量寄存器重命名为4个独立的向量物理寄存器(每个寄存器包含8个数据元素)。这意味着我们添加一个新的向量寄存器分配表(VRAT ),每个架构整数寄存器有P个条目,记录分配给指令的P个流水线副本的P个目标物理向量寄存器。当我们在VRAT中查找这些P寄存器时,新矢量化指令的P个副本中的每一个都使用P个条目中的一个作为自己的输入。这使我们能够区分向量流水线配置中的独立流水线迭代的输入和输出,从取指令的角度来看,它们都是同一指令的别名。16个整数寄存器中的每一个都需要P个条目,这通常是很小的
Managing Pipeline Resources During Runahead
必须有足够数量的未使用的发布队列和物理(标量和向量)寄存器文件条目,用于推测性地执行导致间接加载的间接链。在矢量提前运行中,一条矢量指令从分派到执行占用一个issue入口。在执行时,发布队列条目被释放,并且可以被分配给更年轻的指令,类似于标准的OoO内核。
如何去保存映射关系与释放映射关系?
这是通过一个简单的有序寄存器解除分配队列(RDQ)来完成的,PRE [64]也使用这个队列。在VRAT中查找每条指令,以查看保存最后写入同一架构寄存器的指令的目的地的P(矢量流水线下)物理矢量寄存器,一旦新指令到达流水线的末端,该寄存器就会失效。
这个相当于一个小rob
Terminating Runahead
当满足以下四个条件中的任何一个时,矢量提前运行模式终止:(1)我们再次遇到相同跨越负载的动态实例;(2)我们遇到并发出终止符:由步幅检测器(第III-B节)识别为序列中最后一个相关加载的PC;(3)所有向量车道都已被标记为无效;或者(4)在沿着意外的代码路径行进的情况下,我们超时(在向量提前运行模式下执行了200个标量等价指令之后)。当U > P(截面III-G)时,即展开长度大于管道深度时,我们立即重新进入矢量提前运行模式,加载下一个跨越负载
再次发布矢量集合。重复这一过程,直到我们发出了U=P个总回合,然后才恢复正常执行。如第六节所示,对整个间接链进行矢量化的好处远远超过内核处于提前运行模式的额外时间,因为矢量提前运行比典型的无序执行产生更高的内存级并行性。
终止后,我们将前端RAT恢复到进入runahead模式的点,TV、VRAT和RDQ被清除。前端被重定向以从ROB中最后调度的指令之后的下一条指令获取。