topdown analysis
A Top-Down Method for Performance Analysis and Counters Architecture
为什么要提出这个方法学?
传统的性能评估方法:

其限制如下:
- Stalls overlap:OoO处理器许多模块都是并行计算,可能dcache miss惩罚会被overlap(即使miss也可以执行其他没有依赖的指令)
- Speculative execution:推测执行产生的错误结果不会影响提交,他们对性能实际影响较小(相对正确路径)
- Penalties are workloaddependent:性能惩罚的周期不定,而是和具体的工作负载相关,传统的性能评估方法认为所有惩罚周期一致
- Restriction to a pre-defined set of miss-events:只有一些比较常见的会被评估,但比较细节的就可能被忽视(前端供指不足)
- Superscalar inaccuracy:超标量处理器可以一个周期执行退休多条指令,issue带宽可能会出现问题(其中一个例子)
于是,intel提出了top-down的性能分析方法,该方法不仅可以应用于微结构探索,也可以去应用于软件分析
他的分析方法就相当一个树,从跟节点到叶子节点一点点分析(选择占比大的事件分析),特点如下:
引入错误预测的性能事件,并放在性能事件顶部
引入专门的计数器(12个)
确定关键的流水线阶段(issue)和计数时机
比如,与其统计内存访问总时间,不如去观察由于mem access hang导致的执行单元利用率低的持续时间
使用通用的事件
其分析层次如下:
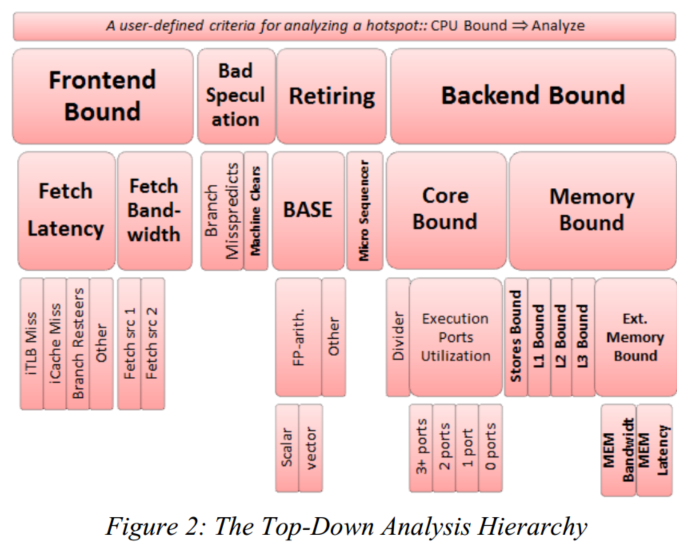
我们选择issue阶段来进行事件分解
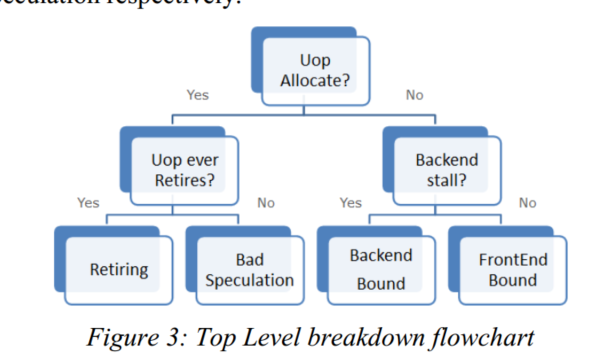
将性能事件分为4类: Frontend Bound, Backend Bound, Bad Speculation and Retiring
前端 bound
前端分为Latency和Bandwidth,
Latency:icache未命中等导致前端无法产生有效指令
Frontend Bandwidth Bound:decoder效率低,其次就是取指令宽度不够(后端执行太快)
boom很难产生Latency bound,后端执行单元少,无法利用OoO的并行
Bad Speculation category
细分为br mispred和mechine clear
Backend Bound category
这里可能会有dcache miss divider执行等情况
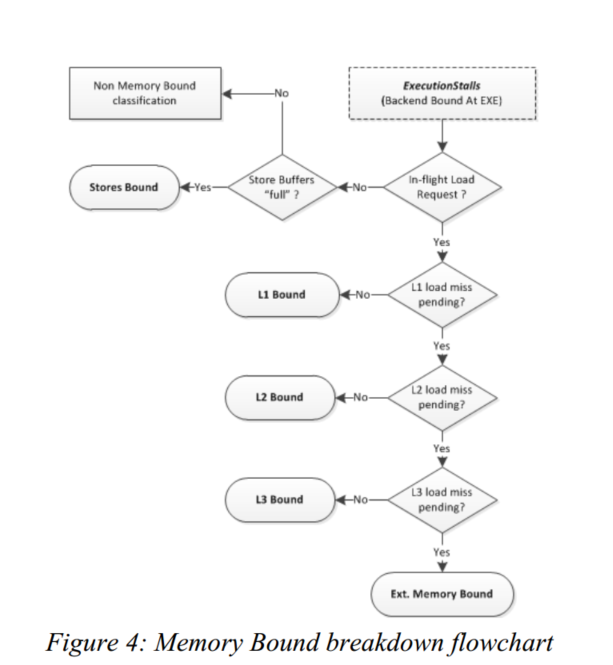
其进一步细分为Memory Bound 和Core Bound
为了维持最大IPC,需要去在4-wide的机器上尽量让exu跑满
Memory Bound:显而易见,就是lsu所造成的性能损失
Core Bound :执行端口利用率低,除法指令
下面还展示了将Mem Bound细分
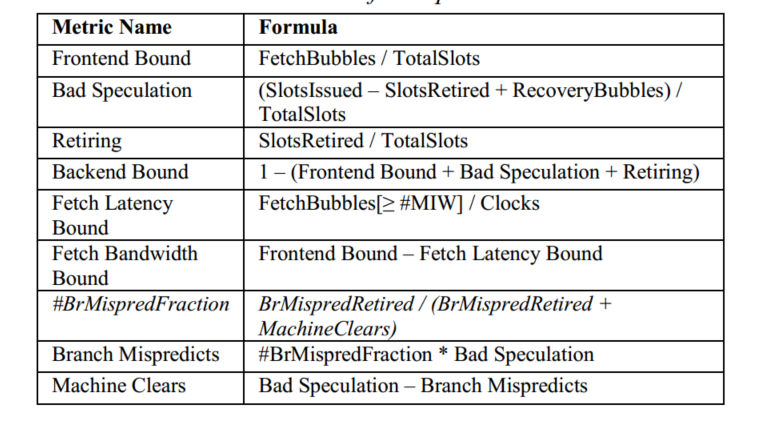
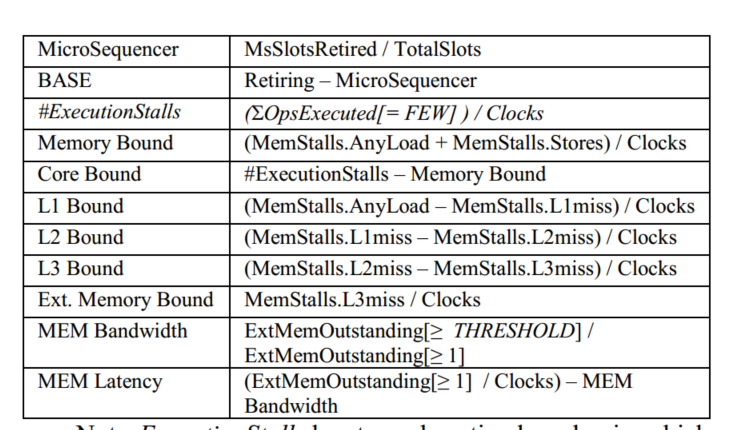
计数器结构
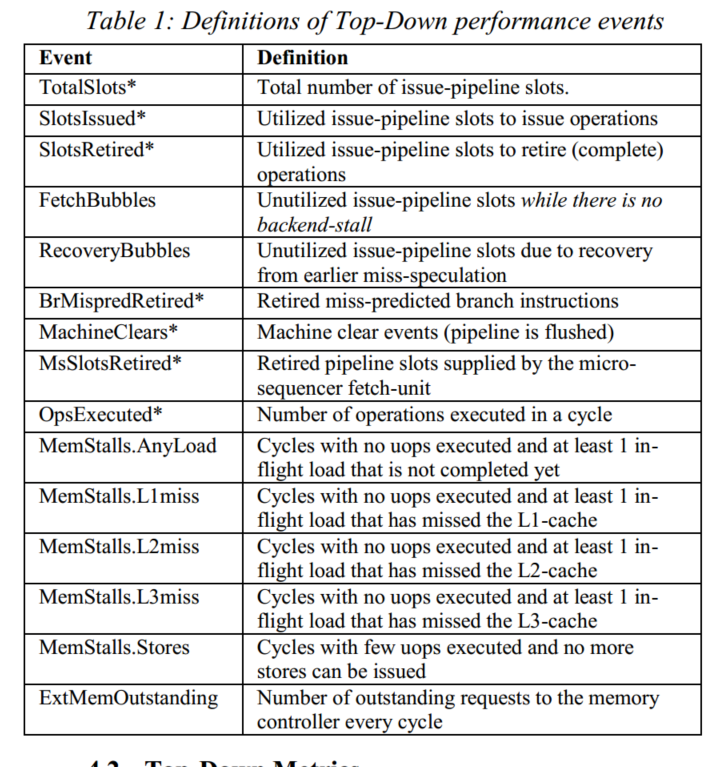
有*号代表现代的PMU含有该计数器,可以看到只需8个新的perf计数器就可以实现一级level的TMA,其计算公式如下:
Rocket chip 性能计数器
RISCV只给出了性能计数器的标准,但并未给出性能计数器的具体实现,rocket chip 的实现方法如下:
这里的EventSets,给出了三个EventSet,每个EventSets通过event选择
1 | val perfEvents = new EventSets(Seq( |
rocketchip的性能计数器需要写入hpmevent来给出对应的操作:
具体的,hpmevent低8位选择不同的EventSet,其他位去选择具体的性能事件,比如向mhpmevent3写入0x4200,那么mhpmcounter在发生int load commit或 cond branch inst commit均会递增

下面介绍一些函数的用法:该片段节选自CSR,这里主要就是去写入计数器(用于初始化)和event,注意在写入event时需要执行maskEventSelector,防止写入非法的区域
1 | for (((e, c), i) <- (reg_hpmevent zip reg_hpmcounter).zipWithIndex) { |
具体的,eventSetIdBits为8,set Mask是去mask不同的EventSet,maskMask是去mask一个EventSet不同的性能事件,然后执行eventSel & (setMask | maskMask).U保证写入一定是合法的值
1 | //这里低8位是用来选择模式的(也就是不同的性能计数器),setMask的意思就是给出此次选择哪个eventSet的Mask |
如何去触发性能事件并且使得相应的计数器增加呢?
首先通过写入reg_hpmevent,配置好性能事件
然后在rocketchip的核心中有
1 | csr.io.counters foreach { c => c.inc := RegNext(perfEvents.evaluate(c.eventSel)) } |
也就是遍历每个event是否触发了性能事件,并且给出增量,该增量会传入CSR,代码如下:
1 | val reg_hpmcounter = io.counters.zipWithIndex.map { case (c, i) => |
reg_mcountinhibit控制对应的计数器是否递增,为1禁止,(这里计数器最大为40位,因为64位会浪费bit)
接下来讲解evaluate是如何工作的,下面代码是EventSets类的函数
1 | private def decode(counter: UInt): (UInt, UInt) = { |
decode给出的是set(选择了哪个EventSet),mask(具体性能事件的选择),然后遍历了eventSets,对每个元素执行check函数
1 | def size = events.size |
check函数主要就是根据EventSet传入的函数,给出是否命中的信息,最后sets(set)就是选择对应的set,
rocket chip的性能计数器设置每个周期只能+1,这样就无法去将该逻辑应用到BOOM中
- 兼容boom
现在已经兼容boom,并添加了一级level的TMA