NOC部分 参数定义 NOC部分的参数定义在/Hardware/little/subsystem/Configs.scala,然后NOC的全局参数定义在MEEK/Hardware/little/guardiancouncil/GH_GlobalParams.scala
1 2 3 4 5 6 7 object GH_GlobalParams { val GH_NUM_CORES = 5; val GH_WIDITH_PACKETS = 145; val GH_DEBUG = 0; val GH_WIDITH_PERF = 64; val IF_THERE_IS_CDC = true; }
然后GAGG和GHM参数定义,第一个参数为小核心的个数,第二个参数为发送包的长度,第一个参数就是找到所有tile的最大值,以此获得小核心的个数,注意hartid是从0开始的
1 2 case GHMCoreLocated(InSubsystem) => Some(GHMParams(((site(TilesLocated(InSubsystem)).map(_.tileParams.hartId).max+1)-1), GH_GlobalParams.GH_WIDITH_PACKETS)) case GAGGCoreLocated(InSubsystem) => Some(GAGGParams(((site(TilesLocated(InSubsystem)).map(_.tileParams.hartId).max+1)-1), GH_GlobalParams.GH_WIDITH_PACKETS))
还有GHT参数定义,该参数不使用cde,而是手动输入参数
1 2 3 4 5 6 7 8 9 10 case class GHTParams( width_core_pc: Int, width_data: Int, totalnumber_of_checkers: Int, totaltypes_of_insts: Int, totalnumber_of_ses: Int, packet_size: Int, core_width: Int, use_prfs: Boolean )
GHT_FILTER_PRFS解读 一开始是IO信号以及一些寄存器
指令解码如下,解码完成后送入寄存器寄存
1 2 3 4 inst := Mux(io.ght_ft_newcommit_in, io.ght_ft_inst_in, 0x0.U) func := Mux(io.ght_ft_newcommit_in, inst(14, 12), 0x0.U) opcode := Mux(io.ght_ft_newcommit_in, Mux(is_rvc, Cat(zeros_5bits, inst(1,0)), inst(6,0)), 0x0.U)
解码的同时ght_ft_cfg_in也会送入u_ght_ftable,这个是一个查找表,但目前并不了解这个具体作用
ght的数据从大核传入,主要为配置信息
1 2 3 4 5 6 7 8 9 10 val u_ght_ftable = Module (new GHT_FTABLE(GHT_FTABLE_Params ())) u_ght_ftable.io.cfg_ref_inst_func := this.io.ght_ft_cfg_in(31,28) u_ght_ftable.io.cfg_ref_inst_opcode := this.io.ght_ft_cfg_in(27,21) u_ght_ftable.io.cfg_ref_inst_index := this.io.ght_ft_cfg_in(8,4) u_ght_ftable.io.cfg_ref_inst_sel_d := this.io.ght_ft_cfg_in(20,17) u_ght_ftable.io.cfg_ref_inst_valid := this.io.ght_ft_cfg_valid u_ght_ftable.io.inst_newcommit := this.io.ght_ft_newcommit_in u_ght_ftable.io.inst_in_func := func u_ght_ftable.io.inst_in_opcode := opcode | (is_rvc_msb << 2) u_ght_ftable.io.inst_is_rvc := is_rvc
之后读出结果dp_sel和inst_idx,进入大核处理阶段(params.use_prfs=true),首先得出大核的指令类型,然后根据解码的数据发送转发信号,FTQ转发需要是ret指令,prf转发不能是ret指令(ret不写入寄存器)
目前暂时不清楚这个dp_sel如何选择,
dp_sel由软件写入,inst_idx同理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 io.ght_prfs_forward_ldq := MuxCase(0.U, Array((dp_sel === 0.U) -> false.B, (dp_sel === 1.U) -> false.B, (dp_sel === 2.U) -> true.B, (dp_sel === 3.U) -> false.B, ((dp_sel === 5.U) && (!lr_inst)) -> false.B, ((dp_sel === 5.U) && (lr_inst)) -> true.B ) ) io.ght_prfs_forward_stq := MuxCase(0.U, Array((dp_sel === 0.U) -> false.B, (dp_sel === 1.U) -> false.B, (dp_sel === 2.U) -> false.B, (dp_sel === 3.U) -> true.B, ((dp_sel === 5.U) && (!lr_inst)) -> true.B, ((dp_sel === 5.U) && (lr_inst)) -> false.B ) ) val ght_prfs_forward_prf = MuxCase(0.U, Array((dp_sel === 0.U) -> false.B, (dp_sel === 1.U) -> true.B, (dp_sel === 2.U) -> true.B, (dp_sel === 3.U) -> false.B, (dp_sel === 5.U) -> true.B ) ) io.ght_prfs_forward_prf := (ght_prfs_forward_prf === true.B) && (!(inst_ret|inst_ret_rvc)) io.ght_prfs_forward_ftq := (ght_prfs_forward_prf === true.B) && (inst_ret|inst_ret_rvc)
最后就是故障注入,这里采用了fi_counter,fi_counter_tiny来控制故障注入的频率,使用end_of_fi控制注入是否完成,然后fi信号就是故障注入信号,fi_dpx数据就是注入的故障数据
注意:这里必须开启fi_mode才会故障注入
1 2 3 4 5 6 val fi = Mux(incr_fi_counters.asBool && !end_of_fi.asBool && fi_counter_tiny === 31.U, true.B, false.B) val if_id = WireInit(0.U(4.W)) if_id := params.id_filter.U val fi_dp1 = Cat(if_id, fi_counter(3,0), io.gtimer(39,0), zero8, dp_ldst_reg) val fi_dp2 = Cat(if_id, fi_counter(3,0), io.gtimer(39,0), zero8, dp_ldst_reg) val fi_dp3 = Cat(if_id, fi_counter(3,0), io.gtimer(39,0), zero8, dp_jump_wire(61,0), jump_type)
最后即使根据dp_sel_reg来选择最后的数据包
1 2 3 4 5 6 7 8 io.packet_out := MuxCase(0.U, Array((dp_sel_reg === 0.U) -> 0.U, (dp_sel_reg === 5.U) -> Mux((inst_index_reg =/= 0.U), nfi_dp5, 0.U), (dp_sel_reg === 2.U) -> Mux((inst_index_reg =/= 0.U), Mux(fi, fi_dp1, nfi_dp1), 0.U), (dp_sel_reg === 3.U) -> Mux((inst_index_reg =/= 0.U), Mux(fi, fi_dp2, nfi_dp2), 0.U), (dp_sel_reg === 1.U) -> Mux((inst_index_reg =/= 0.U), Mux(fi, fi_dp3, nfi_dp3), 0.U), ) )
这里从new_commit信号开始读出数据,需要两个周期完成数据包送出
第一个周期:GHT_FTABLE读出数据
第二个周期:通过各种选择信号将数据送入io.packet_out
之后该数据会被送入GHM
GH_FIFO 主要解释status_fiveslots为还有五个空位
1 2 3 io.status_fiveslots := Mux(num_contentReg >= ((params.depth).U - 5.U), 1.U, 0.U)
GHT_FILTERS_PRFS 这个模块主要就是连线逻辑
连接过滤器
入队逻辑
出队逻辑
这里主要讲解FSM,FSM启动信号就是buffer有数据,或者rsu_merging,此时进入下一个状态,
考虑fsm_send_first跳转情况,如果ght_stall为false,会跳转到fsm_first_nxt_state,此时主要考虑以下情况:
buf1有数据,此时跳转到fsm_send_second
buf1没数据,但buf2有数据,此时跳转到fsm_send_thrid
buf1,buf2都没数据,buf3有数据,此时跳转到fsm_send_fourth
如果都没数据,并且此时不满足buffer有数据,或者rsu_merging,跳转到fsm_reset
这里FSM最多处理四个周期:4-width boom,buf下标从0开始
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 val fsm_reset :: fsm_send_first :: fsm_send_second :: fsm_send_third :: fsm_send_fourth :: Nil = Enum(5) switch (fsm_state) { is (fsm_reset){ // 0x0b000 packet := 0.U inst_type := 0.U load_t_buffer := Mux((!buffer_empty(0) || (io.rsu_merging === 1.U)), 1.U, 0.U) fsm_state := Mux((!buffer_empty(0) || (io.rsu_merging === 1.U)), fsm_reset_nxt_state, fsm_reset) } is (fsm_send_first){ when (io.ght_stall) { // 0x0b001 packet := 0.U inst_type := 0.U fsm_state := fsm_send_first load_t_buffer := 0.U } .otherwise { packet := t_buffer_packet(0) inst_type := t_buffer_inst_type(0) fsm_state := fsm_first_nxt_state load_t_buffer := load_t_buffer_first_state } } ... is (fsm_send_fourth){ when (io.ght_stall) { // 0x0b100 packet := 0.U inst_type := 0.U fsm_state := fsm_send_fourth load_t_buffer := 0.U } .otherwise { packet := t_buffer_packet(3) inst_type := t_buffer_inst_type(3) fsm_state := fsm_fourth_nxt_state load_t_buffer := load_t_buffer_fourth_state } } } fsm_first_nxt_state := MuxCase(fsm_send_first, Array((is_valid_t_buffer(1) =/= 0.U) -> fsm_send_second, ((is_valid_t_buffer(1) === 0.U) && (is_valid_t_buffer(2) =/= 0.U)) -> fsm_send_third, ((is_valid_t_buffer(1) === 0.U) && (is_valid_t_buffer(2) === 0.U) && (is_valid_t_buffer(3) =/= 0.U)) -> fsm_send_fourth, ((is_valid_t_buffer(1) === 0.U) && (is_valid_t_buffer(2) === 0.U) && (is_valid_t_buffer(3) === 0.U)) -> Mux((!buffer_empty(0) || (io.rsu_merging === 1.U)), fsm_reset_nxt_state, fsm_reset) ) )
然后就是几个输出信号,core_hang_up就是揭示buffer快满了,或者filter停了
1 2 3 4 5 6 7 8 9 10 11 12 13 // Outputs io.ght_ft_inst_index := inst_type(7,0) io.packet_out := Cat(inst_type(15,8), packet(280,145), inst_type(7,0), packet(135,0)) // Added inst_type for checker cores io.core_hang_up := core_hang_up | filter_stall io.ght_buffer_status := Cat(buffer_full(params.core_width-1), buffer_empty.reduce(_&_)) io.ght_filters_empty := buffer_empty.reduce(_&_) /* R Features */ io.ght_filters_ready := MuxCase(0.U, Array(((load_t_buffer === 1.U) && (io.rsu_merging === 0.U)) -> 0.U, ((load_t_buffer === 1.U) && (io.rsu_merging === 1.U)) -> 1.U ) )
filter_stall信号是看s_delay_counter_reg是否为0,不为0说明filter空间不够,
s_not_enough_filter_width如果不为1且core_hang_up不为1,说明filter正在输出数据,并且buffer位置充裕,当core_hang_up为1,说明buffer空间不足,这时s_delay_counter_reg不变,也就是等待buffer有空位再递减
这里的意思是检测filter是否有空间,空间不足就需要停止,停止的周期就是s_delay_counter的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 s_num_packets := Cat(zeros_2bits, io.ght_ft_newcommit_in(0)) + Cat(zeros_2bits, io.ght_ft_newcommit_in(1)) + Cat(zeros_2bits, io.ght_ft_newcommit_in(2)) + Cat(zeros_2bits, io.ght_ft_newcommit_in(3)) s_not_enough_filter_width := Mux((s_num_packets > filter_width), 1.U, 0.U) s_delay_counter := MuxCase(0.U, Array(((s_not_enough_filter_width === 0.U) || (filter_width === 0.U)) -> 0.U, ((s_not_enough_filter_width === 1.U) && (filter_width === 1.U)) -> (s_num_packets - 1.U), ((s_not_enough_filter_width === 1.U) && (filter_width === 2.U)) -> 1.U ) ) when (s_not_enough_filter_width === 1.U) { s_delay_counter_reg := s_delay_counter_reg + s_delay_counter } .otherwise { when (core_hang_up =/= 1.U) { s_delay_counter_reg := Mux(s_delay_counter_reg =/= 0.U, (s_delay_counter_reg - 1.U), 0.U) } .otherwise { s_delay_counter_reg := s_delay_counter_reg } } val filter_stall = Mux((s_delay_counter_reg =/= 0.U), 1.U, 0.U)
GHT解读 GHT是在大核和小核都部署的部件,
模块例化位置:MEEK/Hardware/big/common/tile.scala和MEEK/Hardware/little/tile/RocketTile.scala
该模块主要讲解之前没有的信号
配置路径 如下,通过输入的低三位来说明
目前并不知道cfg传入的是什么
cfg是通过GHE解码后传入的信号,cfg_in也就是ROCC指令的rs1的值(a1),cfg_valid也就是解码的指令为CFG指令
1 2 3 4 5 6 7 8 9 val ght_cfg_in_ft_filter = WireInit(0.U(32.W)) val ght_cfg_valid_ft_filter = WireInit(0.U(1.W)) ght_cfg_in_ft_filter := Mux((this.io.ght_cfg_in(3,0) === 2.U), this.io.ght_cfg_in, 0.U) ght_cfg_valid_ft_filter := Mux((this.io.ght_cfg_in(3,0) === 2.U), this.io.ght_cfg_valid, 0.U) u_ght_filters.io.ght_ft_cfg_in := ght_cfg_in_ft_filter u_ght_filters.io.ght_ft_cfg_valid := ght_cfg_valid_ft_filter
执行路径主要就是输出转发信号到ldq,stq,ftq
然后就是mapper 部分,这里主要就是将shared_CP_CFG解码,下面的代码是对cfg的解码,
同样,shared_CP_CFG并不知道包含什么,且不知道inst_arfs和inst_c是干什么的
shared_CP_CFG从大核传入,inst_arfs最后送入GHM
1 2 3 4 5 6 7 8 9 10 11 12 val u_ght_mapper_arfs = Module (new GHT_MAPPER(GHT_MAPPER_Params(params.totaltypes_of_insts, params.totalnumber_of_ses))) // configuration path u_ght_mapper_arfs.io.ght_mp_cfg_in := ght_cfg_in_mp_filter u_ght_mapper_arfs.io.ght_mp_cfg_valid := ght_cfg_valid_mp_filter u_ght_mapper_arfs.io.shared_CP_CFG := io.shared_CP_CFG // execution path u_ght_mapper_arfs.io.inst_index := io.inst_index_arfs for (i <- 0 to params.totalnumber_of_ses - 1) { inst_arfs(i) := u_ght_mapper_arfs.io.inst_c(i) }
之后来到GHT_SE部分,这个部分的输入也用到了cfg_in,首先se首先例化GHT_STABLE,将下面信号做一个寄存(感觉这里可以使用Reg_enable)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 val u_ght_stable = Module (new GHT_STABLE(GHT_STABLE_Params ())) val sch_reset = WireInit(0.U(1.W)) sch_reset := Mux(((this.io.ght_se_cfg_valid === 1.U) && (this.io.ght_se_cfg_in(27,21) === 0xF.U)), 1.U, 0.U) u_ght_stable.io.cfg_sch_end_id := Mux(sch_reset === 1.U, 0.U, this.io.ght_se_cfg_in(31,28)) u_ght_stable.io.cfg_sch_policy := Mux(sch_reset === 1.U, 0.U, this.io.ght_se_cfg_in(27,21)) u_ght_stable.io.cfg_sch_start_id := Mux(sch_reset === 1.U, 0.U, this.io.ght_se_cfg_in(20,17)) u_ght_stable.io.cfg_sch_valid := Mux(sch_reset === 1.U, 0.U, this.io.ght_se_cfg_valid) val sch_end_id = WireInit(0.U(4.W)) val sch_policy = WireInit(0.U(7.W)) val sch_start_id = WireInit(0.U(4.W)) sch_policy := u_ght_stable.io.sch_policy sch_end_id := u_ght_stable.io.sch_end_id sch_start_id := u_ght_stable.io.sch_start_id
然后还有一个SCH部分,这里个人目前理解c后缀的代表commit,core_s代表checker 的id,core_d代表目的checker
这个的功能就是得出目的checker的id?然后io.cpuna没有用到
注意,这里io.sch_hang始终为0
1 2 3 4 5 6 7 8 9 10 11 12 13 val u_sch_p = Module (new GHT_SCH_PIN(GHT_SCH_Params (params.totalnumber_of_checkers))) val core_d_p = WireInit(0.U(params.totalnumber_of_checkers.W)) u_sch_p.io.core_s := sch_start_id u_sch_p.io.core_e := sch_end_id u_sch_p.io.inst_c := Mux(sch_policy === 1.U, io.inst_c, 0.U) for (i <- 0 to params.totalnumber_of_checkers - 1) { u_sch_p.io.core_na(i) := io.core_na(i) } core_d_p := u_sch_p.io.core_d u_sch_p.io.rst_sch := sch_reset io.sch_hang := u_sch_p.io.sch_hang io.core_d := core_d_p
再回到GHT,Scheduler Engines得到core_d_all,core_d_all_arfs,也就是调度的core id
注意,这里的sch_hang总是为0
然后到AGG Configuration,这里也是用到了ght_cfg_in
GHT在大核的作用 下面的核心信号只要是bridge出去的信号都和cmdrounter有关,其他信号使用了diplomacy的Node
目前暂时还没看cmdrounter,数据全部从cmd_counter传入
为什么大核送入GHT的rsu_merging为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ght.io.ght_mask_in := (ght_bridge.io.out | (!if_correct_process_bridge.io.out)) ght.io.gtimer := debug_gtimer ght.io.gtimer_reset := debug_gtimer_reset ght.io.use_fi_mode := s_or_r ght.io.ght_cfg_in := ght_cfg_bridge.io.out ght.io.ght_cfg_valid := ght_cfg_v_bridge.io.out ght.io.debug_bp_reset := debug_bp_reset_bridge.io.out outer.ght_packet_out_SRNode.bundle := ght.io.ght_packet_out outer.ght_packet_dest_SRNode.bundle := Cat(ght.io.arfs_dest, ght.io.ght_packet_dest) core.io.gh_stall := ght.io.core_hang_up outer.ghe_event_out_SRNode.bundle := ghe_bridge.io.out outer.clear_ic_status_SRNode.bundle := 0.U core.io.clear_ic_status_tomain := outer.clear_ic_status_tomainSKNode.bundle core.io.icsl_na := outer.icsl_naSKNode.bundle ght.io.core_na := outer.sch_na_inSKNode.bundle if_ght_filters_empty_bridge.io.in := ght.io.ght_filters_empty
核心信号连接,主要连接了从大核来的pc_addr,inst,commit信号。以及alu数据
1 2 3 4 5 6 7 8 9 10 11 12 for (w <- 0 until gc_core_width) { ght.io.ght_pcaddr_in(w) := core.io.pc(w) ght.io.ght_inst_in(w) := core.io.inst(w) ght.io.new_commit(w) := core.io.new_commit(w) ght.io.ght_alu_in(w) := MuxCase(0.U, Array((ght.io.ght_prfs_forward_ldq(w) === true.B) -> Cat(zeros_8bits, ldq_header(w)), (ght.io.ght_prfs_forward_stq(w) === true.B) -> Cat(zeros_8bits, stq_header(w)), (ght.io.ght_prfs_forward_ftq(w) === true.B) -> Cat(zeros_72bits, jal_or_jlar_target_buffer(w)) ) ) }
GHE 接下来解读rocc,因为大核内部除了GHT就是rocc和cmdcounter连接,rocc实际上为GHE,GHE主要就是解码器,对输入的ROCC指令解码
首先要明确ROCC指令的格式
GHE的作用类似于中间层,去处理rocc指令,然后通过cmdrounter路由
rocc指令 1 2 3 4 5 6 7 8 9 10 #define CUSTOMX(X, xd, xs1, xs2, rd, rs1, rs2, funct) \ CUSTOMX_OPCODE(X) | \ (rd << (7)) | \ (xs2 << (7+5)) | \ (xs1 << (7+5+1)) | \ (xd << (7+5+2)) | \ (rs1 << (7+5+3)) | \ (rs2 << (7+5+3+5)) | \ (EXTRACT(funct, 7, 0) << (7+5+3+5+5))
rd,rs1,rs2分别代表目的寄存器,源寄存器1,源寄存器2的标号,xd,xs1,xs2分别代表是否使用这些寄存器,然后funct指示了func,最后还有X(op_code),指示指令属于custom_x
之后分别解读各个信号:
下面的解释将LW作为读取作用的指令(含有rd的),
doCheck:funct为0x00,在软件中为ghe_status
doSorR: funct为0x1,在软件中为ghe_asR,ghe_asG
doEvent: (funct ===0x40.U) || (funct ===0x41.U) || (funct ===0x42.U) || (funct ===0x43.U),在软件中分别为ghe_go,ghe_complete,ghe_release,0x42暂时没有找到
doCheckBigStatus:funct为0x07,为LW,在软件中为ghe_checkght_status
doCheckAgg:funct为0x10,为LW,在软件中为ghe_agg_status:
doInitialised:funct为0x50||0x51,软件中为ghe_initailised,这个函数有一个if_initailised输入,来选择执行funct为0x50的指令还是0x51的指令
doCopy:funct为0x60,并未找到0x60的函数
doCheckRSU:funct为0x61,软件中为ghe_rsur_status
1 2 3 4 // 0b00: idle // 0b01: snapshot received // 0b11: snapshot and results recieved // 0b10: wrong status
doDeqELU:funct为0x63,软件中没有这个
好像只是没有封装为函数
doBigCheckComp:funct为0x06,软件中很多0x6的
doMask:满足的软件函数很多 funct 从0x30-0x38
0x30-0x34:ght_set_status,通过输入index选择执行不同的指令,其他暂时没有实现
doCritical:0x39:暂时没有找到
doCheckCritial:0x49,暂时没有找到
doPID_Cfg:0x16,软件中为ght_set_satp_priv,ght_unset_satp_priv
doGHT_Cfg:0x06并且rs2_val==2||3||4,软件中对应的是
1 2 3 4 5 6 ght_cfg_filter ght_cfg_se ght_cfg_mapper ghm_cfg_agg ght_debug_filter_width
doGHTBufferCheck:0x08,为LW,软件中为ght_get_buffer_status
doBigCheckIni:0x1b,为LW,软件中为ght_get_initialisation
doSetActivatedCheckers:0x1c,软件中为ght_set_numberofcheckers
doICCTRL
上面的均未使用函数封装
rd写入 下面介绍需要写入rd的操作
首先是doCheck,写回值为Cat(channel_full, channel_empty),2-bits
1 2 3 4 // 0b01: empty; // 0b10: full; // 0b00: data buffered; // 0b11: error
doCheckBigStatus,写回值为ghe_status_in,从GHM传入
doCheckAgg,写回值为Cat(zeros_62bits, io.agg_buffer_full, zeros_1bit),
此处只会检查full,但不检查error
1 2 3 4 // 0b01: empty; // 0b10: full; // 0b00: data buffered; // 0b11: error
doBigCheckComp,写回值为Cat(bigComp, rs1_val(15, 0)),bigComp为ghm传入,rs1_val为寄存器读出
doBigCheckIni,写回值为bigInialised,该信号为ghm传入
doGHTBufferCheck:写回值为Cat(zeros_62bits, io.ght_buffer_status),该信号为ght传入
doCheckCritial:写回值为ght_critial_reg(也就是rs1_val(1,0)的寄存器)
doCheckRSU:写回值为Cat(io.rsu_status_in, zeros_3bit),从rocketchip传入
doDebug_bp_checker:写回值为io.debug_bp_checker,从ght传入
doDebug_bp_checker -> io.debug_bp_checker,
这三个和上面同理
doPerfRead写回值来自io.elu_data_in(63,0),由Boom传入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 rd_val := MuxCase(0.U, Array(doCheck -> Cat(zeros_channel_status, channel_status_wire), doCheckBigStatus -> ghe_status_reg, doCheckAgg -> Cat(zeros_62bits, io.agg_buffer_full, zeros_1bit), doBigCheckComp -> Cat(bigComp, rs1_val(15, 0)), doBigCheckIni -> Cat(bigInialised), doGHTBufferCheck -> Cat(zeros_62bits, io.ght_buffer_status), doCheckCritial -> Cat(zeros_62bits, ght_critial_reg(1,0)), doCheckRSU -> Cat(io.rsu_status_in, zeros_3bit), doDebug_bp_checker -> io.debug_bp_checker, doDebug_bp_cdc -> io.debug_bp_cdc, doDebug_bp_filter -> io.debug_bp_filter, doPerfRead -> io.elu_data_in(63,0) ) )
输出信号 ghe_event_out:Cat(0.U, ghe_initialised_reg, ghe_event_reg, channel_warning),传输了ghe_initialised_reg,ghe_event_reg,这两条信息分别与doInitialised和doEvent有关
ght_mask_out:~(ght_status_reg(0)),与doMask有关
ght_status_out:Cat(0.U, num_activated_cores, ght_status_reg(22,0)),与doSetActivatedCheckers和doMask有关
ght_cfg_out,ght_cfg_valid:Mux(doGHT_Cfg, rs1_val(31,0), 0.U),Mux(doGHT_Cfg, 1.U, 0.U),与doGHT_Cfg有关
debug_bp_reset:Mux(doDebug_Reset_bp, 1.U, 0.U),与doDebug_Reset_bp有关
agg_packet_out,report_fi_detection_out,agg_core_status_out,ght_sch_na_out,fi_sel_out:与输入直连
ght_sch_na:channel_sch_na:控制信号由channel_nearfull和ght_sch_refresh(GHM传入)控制
ght_sch_dorefresh:恒为0
if_correct_process:Mux((define_monitor_target ===1.U), 1.U, (hit_satp_ppn & hit_privi & has_monitor_target))
1 2 define_monitor_target := Mux((doPID_Cfg && (rs1_val === 1.U)), 1.U, 0.U) undefine_monitor_target := Mux((doPID_Cfg && (rs1_val === 2.U)), 1.U, 0.U)
t_value_out:t_Value和doSetTValue有关
RoccCommandRouterBoom也就是cmdrounter,内部加入了MEEK的信号,目前暂时不知道这些信号含义
目前该模块虽然得知各个信号代表什么,但怎莫用,如何去用还需研究
GHM ghm和gagg都是在顶层定义的,然后在这个文件中定义了GBUS,MEEK/Hardware/little/subsystem/BusTopology.scala,主要用于外设的访问
文件位置:MEEK/Hardware/top/System.scala中的ChipyardSystem
其中DigitalTop继承了这个类
GHM主要就是将大核数据送入小核
NOC节点定义与连接 位于MEEK/Hardware/little/subsystem/HasTiles,主要在该trait定义了Ephemeral节点,且指定了数据类型,然后这个trait只能被BaseSubsystem或者其子类继承
1 2 3 4 5 6 7 8 9 10 11 trait HasGHnodes extends InstantiatesTiles { this: BaseSubsystem => val tile_ghm_agg_core_id_EPNode = BundleBridgeEphemeralNode[UInt]() val tile_ght_packet_out_EPNode = BundleBridgeEphemeralNode[UInt]() val tile_core_r_arfs_EPNode = BundleBridgeEphemeralNode[UInt]() ...... val tile_debug_gcounter_EPNode = BundleBridgeEphemeralNode[UInt]() var tile_agg_packet_in_EPNodes = Seq[BundleBridgeEphemeralNode[UInt]]() val tile_agg_empty_EPNode = BundleBridgeEphemeralNode[UInt]() val tile_agg_free_EPNode = BundleBridgeEphemeralNode[UInt]() }
这里是trait CanAttachTile内部的一个连接函数,主要作用是将tile信号传送到总线上,并且经过跨时钟域处理
1 2 3 4 5 6 7 8 def connectMasterPorts(domain: TilePRCIDomain[TileType], context: Attachable): Unit = { implicit val p = context.p val dataBus = context.locateTLBusWrapper(crossingParams.master.where) dataBus.coupleFrom(tileParams.name.getOrElse("tile")) { bus => bus :=* crossingParams.master.injectNode(context) :=* domain.crossMasterPort(crossingParams.crossingType) } }
大核流程 大核首先将rocc的cmd送入rocc,rocc模块处理完成后会将处理完成的信号送入cmdrouter,
1 2 rocc.module.io.cmd <> cmdRouter.io.out(i) cmdRouter.io.in <> core.io.rocc.cmd
大核会去和ght以及ghe交互
大核和rocc
GHE与GHT交互信号
只要是rocc指令,均为GHE传入
然后与GHT有关的信号会送入GHT处理,具体的
ght_mask_in:rocc指令
use_fi_mode:rocc指令
ght_cfg_in:rocc指令中rs1的值
ght_cfg_valid:rocc指令中rs1的(1,0)
debug_bp_reset:rocc指令
if_correct_process:相对比较复杂的ROCC指令
ght_buffer_status:看ght buf的空满,2 bit 信号,其中高位为1是满,低位为1是空
大核与GHT交互信号 主要获取核的状态:pc,inst,commit,alu
是否prfs_rd,是否为rvc
解释ght是否准备好
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 for (w <- 0 until gc_core_width) { jal_or_jlar_target_buffer(w) := core.io.alu_out(w) ght.io.ght_pcaddr_in(w) := core.io.pc(w) ght.io.ght_inst_in(w) := core.io.inst(w) ght.io.new_commit(w) := core.io.new_commit(w) ght.io.ght_alu_in(w) := MuxCase(0.U, Array((ght.io.ght_prfs_forward_ldq(w) === true.B) -> Cat(zeros_8bits, ldq_header(w)), (ght.io.ght_prfs_forward_stq(w) === true.B) -> Cat(zeros_8bits, stq_header(w)), (ght.io.ght_prfs_forward_ftq(w) === true.B) -> Cat(zeros_72bits, jal_or_jlar_target_buffer(w)) ) ) core.io.ght_prfs_forward_prf(w) := ght.io.ght_prfs_forward_prf(w) ght.io.ght_prfs_rd(w) := core.io.prf_rd(w) outer.frontend.module.io.gh.gh_ftq_idx(w) := Mux((core.io.is_jal_or_jalr(w) === true.B), core.io.ft_idx(w), 0.U) ght.io.ght_is_rvc_in(w) := core.io.is_rvc(w) } ght.io.ic_crnt_target := core.io.ic_crnt_target ght.io.shared_CP_CFG := core.io.shared_CP_CFG ... ght.io.inst_index_arfs := core.io.r_arfs_pidx(0) core.io.ght_filters_ready := ght.io.ght_filters_ready core.io.gh_stall := ght.io.core_hang_up
大核与GHE交互
i说明是输入core的信号
o说明是输出core的信号
icctrl:i :rocc指令,输出值为rs1(3,0)
t_value:i:rocc指令,输出值为rs1(14,0)
if_correct_process:i:rocc:该信号同时也会传入GHT
num_of_checker:i:rocc:GHE的ght_status_out(30,23)
debug_perf_ctrl:i:rocc:rs1(4,0)
core.io.ptw.ptbr.ppn:o:rocc,GHE的ght_satp_ppn信号,和GHE的if_correct_process信号有关
core.io.ght_prv:o:rocc,GHE的ght_sys_mode信号,和上面一个信号共同影响if_correct_process
debug_perf_val:o:rocc,GHE的elu_data_in信号,软件读出
大核与GHM交互 clear_ic_status_tomain:i:GHM的clear_ic_status_tomain信号,从小核的clear_ic_status传入
icsl_na:i:GHM的icsl_na信号,从小核lsl_highwatermark传入
ic_counter:o:在ghm中连接如下,最后连接到小核的ic_counter
1 2 3 for (i <- 0 to params.number_of_little_cores - 1) { io.icsl_counter(i) := Cat(io.debug_maincore_status, io.ic_counter((i+1)*16+15, (i+1)*16)) }
debug_maincore_status:o,在GHM对应信号为debug_maincore_status,和上面信号同时组成了icsl_counter
GHM与GHE交互 ghe_packet_in:ghe_status_ini:ghm的ghm_packet_outs信号,大核不连接GHE,也就是大核不接受ghe数据,大核只发出数据
ght_status_out:o:在GHM中为ghm_status_in
agg_packet_out:一直送入GAGG的agg_packet_in,大核没有使用
bigcore_comp:i:为GHM的传入bigcore_comp
GHT与GHM,GAGG交互 ght_packet_out:o:送入GHM的信号就是packet ghm_packet_in
Cat(ght.io.arfs_dest, ght.io.ght_packet_dest):送入GHM为ghm_packet_dest信号
ghm_agg_core_id:o:ghm_agg_core_id_SKNode:送入GAGG的信号为agg_core_id
debug_bp:i:在GHM信号为debug_bp
ght_stall:i:在GHM中信号为bigcore_hang
总结 大核的命令先送入GHE处理,然后根据GHE来展开接下来的操作,首先,大核的数据会送入GHT,GHT首先过滤请求,加工数据(与ic_crnt_target和cfg有关),并且向大核发出forward请求,然后处理完数据后,送入GHM,经过CDC送入小核
小核心流程 小核心与GHE交互 arfs_if_CPS:i:所以该信号需要s_or_r以及arfs_in:
首先为s_or_r,为GHE的s_or_r_out传入
arfs_in:i:由GHM的core_r_arfs_c传入
packet_arfs:i:由下面代码看到这个信号和arfs_if_CPS类似
packet_lsl:i:该信号的组成为s_or_r,+GHM的ghm_packet_outs信号,该信号也就是从大核经CDC传入的数据
packet_lsl1:i:该信号和上面类似
arf_copy_in:i:从GHE传入的arf_copy_out
s_or_r:i:为GHE的s_or_r_out传入
if_correct_process:i:GHE传入的if_correct_process
record_pc:i:GHE传入record_pc
elu_deq:i:GHE传入的elu_deq_out
elu_sel:i:GHE传入的elu_sel_out
debug_perf_ctrl:i:debug_perf_ctrl
record_and_store:i:record_and_store_out
rsu_status:o;rsu_status_in:软件读出
elu_status:o;GHE并未找到使用
core_trace:i:core_trace_out
ght_prv:o;
上面两个信号共同影响if_correct_process
elu_data:o;elu_data_in:由软件读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 val packet_in_superset = outer.ghe_packet_in_SKNode.bundle val packet_in = packet_in_superset(143, 0) val packet_index = packet_in (143, 136) val ptype_fg = Mux(((packet_index(2) === 0.U) && (packet_index(1,0) =/= 0.U) && (s_or_r === 0.U)), 1.U, 0.U) val ptype_lsl = Mux((s_or_r.asBool && (packet_index(2,0) =/= 7.U) && (packet_index(2,0) =/= 0.U)), 1.U, 0.U) val core_trace = Wire(0.U(2.W)) val debug_perf_ctrl = Wire(0.U(5.W)) val record_and_store = Wire(0.U(2.W)) cdc_flag := Mux((ptype_fg.asBool || ptype_lsl.asBool) && (packet_in_superset(288) =/= cdc_flag), packet_in_superset(288), cdc_flag) cdc_ack := Mux((ptype_fg.asBool || ptype_lsl.asBool) && (packet_in_superset(288) =/= cdc_flag), cdc_ack + 1.U, cdc_ack) val arfs_in = outer.core_r_arfs_c_SKNode.bundle val arfs_index = arfs_in (143, 136) val ptype_rcu = Mux(s_or_r.asBool && (arfs_index(2,0) === 7.U), 1.U, 0.U) val arfs_if_CPS = Mux(ptype_rcu.asBool && (arfs_index (6, 3) === outer.rocketParams.hartId.U), 1.U, 0.U) val packet_fg = Mux((ptype_fg === 1.U) && (packet_in_superset(288) =/= cdc_flag), packet_in, 0.U) val packet_rcu = Mux((ptype_rcu === 1.U), arfs_in, 0.U) val packet_lsl = Mux((ptype_lsl === 1.U) && (packet_in_superset(288) =/= cdc_flag), packet_in, 0.U) val packet_in1 = packet_in_superset(287, 144) val packet_index1 = packet_in1(143, 136) val ptype_lsl1 = Mux((s_or_r.asBool && (packet_index1(2,0) =/= 7.U) && (packet_index1(2,0) =/= 0.U)), 1.U, 0.U) val packet_lsl1 = Mux((ptype_lsl1 === 1.U) && (packet_in_superset(288) =/= cdc_flag), packet_in1, 0.U)
小核心与GHM,GAGG交互 本节不介绍前一节介绍过的
首先介绍下面两个:
1.送入GHM的信号为ghe_event_in
2.送入GHM的信号为ghe_revent_in
1 2 3 outer.ghe_event_out_SRNode.bundle := Cat(cdc_ack, (ghe_bridge.io.out | Cat(core.io.packet_cdc_ready, zeros_4bits) | Cat(zeros_4bits, core.io.lsl_near_full))) outer.ghe_revent_out_SRNode.bundle := core.io.lsl_highwatermark
ic_counter:i:icsl_counter:GHM
clear_ic_status:o;clear_ic_status:GHM
GHE与GHM,GAGG交互
GHE信号:(i or o):GHM or GAGG
ghe_status_in:i:ghm_status_outs:该信号需要软件读出
ght_status_out:o;ghm_status_in
agg_packet_out:在GHE中赋值为0
report_fi_detection_out:未在小核心使用
agg_buffer_full:i:agg_buffer_full:软件读取
agg_core_status:o;agg_core_status,注意该信号还使用到了其他模块的信号
1 2 outer.agg_core_status_SRNode.bundle := Mux(!s_or_r.asBool, cmdRouter.get.io.agg_core_status_out, core.io.icsl_status)
ght_sch_na:o;sch_na_in
ght_sch_refresh:i:sch_refresh_out
ght_buffer_status:恒为0,软件读取
总结 小核心接受从GHM传入的数据包,根据GHE的指令来选择对应的操作
软件执行流程 以TC_OverTaking为例子,大核首先执行r_ini,进行初始化,首先设置小核心数目,ght_set_numberofcheckers(num_checkers);当大核心执行这条ROCC指令,cmd送入GHE,然后GHE将信息通过ght_status_out送出,然后num core会送入大核内,还会有一部分传入GHM,
然后会执行ght_cfg_filter
参数有index,func,opcode以及sel_d,大核执行完ROCC指令会将s1送出GHE,之后会送入GHT,如果rs1的(3,0)==2,说明是filter配置,送入GHT_filter,然后congruentFTABLE,之后运行的指令都会去查询这个表,得出dp_sel
然后之后会执行ght_cfg_se,
hart0执行main 以及hart1执行_main可以在libgloss内找到
小核心在此时会去执行checker,具体的:
首先去执行ghe_asR,然后会在GHE解码得到s_or_r_out(rs1(1,0)),该信号会送入core,且会控制其他的信号
之后会去执行ght_set_satp_priv,该函数进入GHE为doPID_Cfg,设置当前的ppn以及mode,然后还会去发出if_correct_process送入小核心
执行ghe_go,该函数在GHE对应doEvent,然后会将funct写入寄存器ghe_event_reg
执行ghe_initailised,该函数在GHE对应doInitialised,会将funct写入ghe_initialised_reg寄存器
执行ghe_perf_ctrl,在GHE对应debug_perf_ctrl,将rs1的前4位写入,最后送入核内
执行下列指令
ROCC_INSTRUCTION (1, 0x75); // Record context
ROCC_INSTRUCTION (1, 0x73); // Store context from main core
ROCC_INSTRUCTION (1, 0x64); // Record PC
这三个信号在仿真阶段被优化了
大核部分 大核的数据传输主要在LSQ,ROB,FTQ,以及prf和csr
LSU部分 LSU直接读HAED部分的数据,head总是最近提交的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 //===== GuardianCouncil Function: Start ====// val ldq_head_delay = Reg(Vec(coreWidth, UInt((2*xLen).W))) val stq_head_delay = Reg(Vec(coreWidth, UInt((2*xLen).W))) val zeros_24bits = WireInit(0.U(24.W)) for (i <- 0 to coreWidth - 1){ ldq_head_delay(i) := Cat(ldq(ldq_head+i.U).bits.debug_wb_data, zeros_24bits, ldq(ldq_head+i.U).bits.addr.bits) stq_head_delay(i) := Cat(stq(stq_commit_head+i.U).bits.data.bits, zeros_24bits, stq(stq_commit_head+i.U).bits.addr.bits) } for (i <- 0 to coreWidth - 1){ io.ldq_head(i) := ldq_head_delay(i) io.stq_head(i) := stq_head_delay(i) } //===== GuardianCouncil Function: End ====//
FTQ部分 入队信号
1 2 3 val gh_ftq_idx = Input(Vec(coreWidth, UInt(log2Ceil(ftqSz).W))) val jal_or_jlar_target = Output(Vec(coreWidth, UInt(vaddrBitsExtended.W))) val gh_redirect_pc = Input(UInt(vaddrBitsExtended.W))
该部分信号全部被优化掉
ROB部分 信号定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 //===== GuardianCouncil Function: Start ====// val gh_stall = Input(Bool()) val can_commit_withoutGC = Output(Bool()) val gh_effective_jalr_target = Input(UInt(xLen.W)) // Revisit: make it is generic val gh_effective_rob_idx = Input(UInt(7.W)) // Revisit: make it is generic val gh_effective_valid = Input(UInt(1.W)) // Revisit: make it is generic val r_next_pc = Output(UInt(40.W)) // Revisit: make it is generic //===== GuardianCouncil Function: End ====// ... //===== GuardianCouncil Function: Start ====// val gh_effective_alu_out = Vec(retireWidth, UInt(xLen.W)) // Revisit: make it is generic //===== GuardianCouncil Function: End ====//
其中gh_stall可以将rob停止提交,can_commit_withoutGC为原始的commit信号,
r_next_pc为指令的pc,这里使用的是uop的debug_pc
gh_effective_alu_out会输出jmp指令的target
这里有个疑问,为什么需要输出jmp指令的target
core部分 信号定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 //===== GuardianCouncil Function: Start ====// val pc = Output(Vec(coreWidth, UInt(vaddrBitsExtended.W))) val inst = Output(Vec(coreWidth, UInt(32.W))) val new_commit = Output(Vec(coreWidth, UInt(1.W))) val prf_rd = Output(Vec(coreWidth, UInt(xLen.W))) val uses_ldq = Output(Vec(coreWidth, UInt(1.W))) val uses_stq = Output(Vec(coreWidth, UInt(1.W))) val is_jal_or_jalr = Output(Vec(coreWidth, UInt(1.W))) val ft_idx = Output(Vec(coreWidth, UInt(log2Ceil(ftqSz).W))) val ght_prfs_forward_prf = Input(Vec(coreWidth, Bool())) val alu_out = Output(Vec(coreWidth, UInt(xLen.W))) val ght_prv = Output(UInt(2.W)) val is_rvc = Output(Vec(coreWidth, UInt(1.W))) // val arf_long = Output(UInt((xLen*2).W)) // val arf_pc = Output(UInt(40.W)) // val arf_sel = Input(UInt(6.W)) val gh_stall = Input(Bool()) /* R Features */ val num_of_checker = Input(UInt(8.W)) val icctrl = Input(UInt(4.W)) val t_value = Input(UInt(4.W)) val ght_filters_ready = Input(UInt(1.W)) val r_arfs = Output (Vec(1, (UInt((xLen*2+8).W)))) val r_arfs_pidx = Output(Vec(1, UInt(8.W))) val rsu_merging = Output(UInt(1.W)) val ic_crnt_target = Output(UInt(5.W)) val if_correct_process = Input(UInt(1.W)) val ic_counter = Output(Vec(GH_GlobalParams.GH_NUM_CORES, (UInt(16.W)))) val clear_ic_status_tomain = Input(UInt(GH_GlobalParams.GH_NUM_CORES.W)) val icsl_na = Input(UInt(GH_GlobalParams.GH_NUM_CORES.W)) val core_trace = Input(UInt(1.W)) val debug_maincore_status = Output(UInt(4.W)) val ic_trace = Input(UInt(1.W)) val debug_perf_ctrl = Input(UInt(4.W)) val debug_perf_val = Output(UInt(64.W)) val shared_CP_CFG = Output(UInt(13.W)) //===== GuardianCouncil Function: End ====//
该部分的输出信号均来自commit阶段,读取prf是加入了corewidth个读端口去读出数据
这个算是运行时数据,为何要记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 //===== GuardianCouncil Function: Start ====// // Register Read <- Issue (rrd <- iss) for (i <- 0 until numIrfReadPorts) { iregister_read.io.rf_read_ports(i) <> iregfile.io.read_ports(i) } val rob_io_commit_uops_pdst_reg = Reg(Vec(coreWidth, UInt(maxPregSz.W))) for (w <- 0 until coreWidth) { rob_io_commit_uops_pdst_reg(w) := rob.io.commit.uops(w).pdst iregfile.io.read_ports(numIrfReadPorts+w).addr := Mux(io.ght_prfs_forward_prf(w) === true.B, rob_io_commit_uops_pdst_reg(w), 0.U) } //===== GuardianCouncil Function: End ====// ... for (w <- 0 until coreWidth) { ght_prfs_forward_prf_reg(w) := io.ght_prfs_forward_prf(w) io.pc(w) := rob.io.commit.uops(w).debug_pc(31,0) io.inst(w) := rob.io.commit.uops(w).debug_inst(31,0) io.new_commit(w) := Mux(r_syscall, 0.U, rob.io.commit.arch_valids(w)) io.prf_rd(w) := Mux(ght_prfs_forward_prf_reg(w) === true.B, iregfile.io.read_ports(numIrfReadPorts + w).data, 0.U) io.uses_ldq(w) := rob.io.commit.uops(w).uses_ldq io.uses_stq(w) := rob.io.commit.uops(w).uses_stq io.is_jal_or_jalr(w) := rob.io.commit.uops(w).is_jal|rob.io.commit.uops(w).is_jalr io.ft_idx(w) := rob.io.commit.uops(w).ftq_idx io.is_rvc(w) := rob.io.commit.uops(w).is_rvc io.alu_out(w) := rob.io.commit.gh_effective_alu_out(w); if_mret_or_sret(w) := rob.io.commit.arch_valids(w) && ((rob.io.commit.uops(w).debug_inst(31,0) === 0x30200073.U) || (rob.io.commit.uops(w).debug_inst(31,0) === 0x10200073.U)) }
ght_prv从csr读出系统的mode状态
ic_incr,指出本周期提交指令个数,然后arfs和farfs分别记录int和fp寄存器堆的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 val ic_incr = arch_valids_extended.reduce(_ + _) val numARFS = 32 val pcarf = RegInit(0.U(40.W)) val arfs = Reg(Vec(numARFS, UInt(xLen.W))) val farfs = Reg(Vec(numARFS, UInt(xLen.W))) for (w <- 0 until coreWidth) { when (rob.io.commit.arch_valids(w)) { when (rob.io.commit.uops(w).dst_rtype === RT_FIX && rob.io.commit.uops(w).ldst =/= 0.U && !r_syscall) { arfs(rob.io.commit.uops(w).ldst) := rob.io.commit.debug_wdata(w) } .elsewhen (rob.io.commit.uops(w).dst_rtype === RT_FLT && !r_syscall) { farfs(rob.io.commit.uops(w).ldst) := rob.io.commit.debug_wdata(w) } } }
R_IC模块解读 信号定义
ic_run_isax,ic_exit_isax,ic_syscall,ic_syscall_back均与icctrl有关,该控制信号由rocc读入
core_trace信号也由ROCC传入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 val ic_run_isax = Input(UInt(1.W)) val ic_exit_isax = Input(UInt(1.W)) val ic_syscall = Input(UInt(1.W)) val ic_syscall_back = Input(UInt(1.W)) val rsu_busy = Input(UInt(1.W)) val ic_threshold = Input(UInt((params.width_of_ic-1).W)) val icsl_na = Input(Vec(params.totalnumber_of_cores, UInt(1.W))) val ic_incr = Input(UInt((3.W))) val if_ready_snap_shot = Input(UInt((1.W))) val crnt_target = Output(UInt(5.W)) val if_filtering = Output(UInt(1.W)) // 1: filtering; 0: non-filtering val if_pipeline_stall = Output(UInt(1.W)) val if_dosnap = Output(UInt(1.W)) val ic_counter = Output(Vec(params.totalnumber_of_cores, UInt(params.width_of_ic.W))) val ic_status = Output(Vec(params.totalnumber_of_cores, UInt(1.W))) val clear_ic_status = Input(Vec(params.totalnumber_of_cores, UInt(1.W)))//小核心传入 val if_correct_process = Input(UInt((1.W)))//ROCC传入 val num_of_checker = Input(UInt((8.W)))//同样为ROCC val changing_num_of_checker = Input(UInt((1.W))) val core_trace = Input(UInt((1.W))) val ic_trace = Input(UInt((1.W))) val debug_perf_reset = Input(UInt((1.W))) val debug_perf_sel = Input(UInt(3.W)) val debug_perf_val = Output(UInt(64.W)) val debug_maincore_status = Output(UInt(4.W)) val shared_CP_CFG = Output(UInt(13.W))
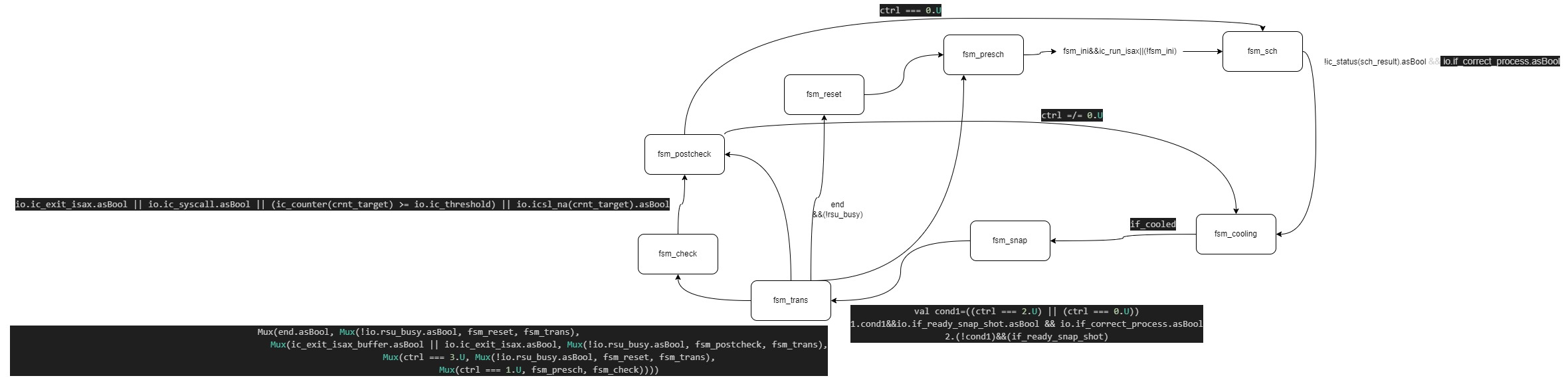
R_IC主体为一个状态机
1 2 val fsm_reset :: fsm_presch :: fsm_sch :: fsm_cooling :: fsm_snap :: fsm_trans :: fsm_check :: fsm_postcheck :: Nil = Enum (8 )val fsm_state = RegInit (fsm_reset)
定义了 8 个状态:
fsm_reset:复位状态。fsm_presch:预调度状态。fsm_sch:调度状态。fsm_cooling:冷却状态。fsm_snap:快照状态。fsm_trans:转换状态。fsm_check:检查状态。fsm_postcheck:后检查状态。
a. fsm_reset 1 2 3 4 5 6 7 8 9 10 11 12 13 14 is (fsm_reset) { end := 0. U ctrl := 2. U crnt_target := 0. U crnt_mask := 0. U nxt_target := 0. U if_filtering := 0. U if_pipeline_stall := 0. U for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_status(i)) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_counter(i)) } fsm_state := fsm_presch }
功能 :初始化所有寄存器和状态。状态转移 :进入 fsm_presch 状态。
b. fsm_presch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 is (fsm_presch) { end := end ctrl := 2. U crnt_target := crnt_target crnt_mask := crnt_mask nxt_target := nxt_target if_filtering := 0. U if_pipeline_stall := Mux (fsm_ini.asBool, 0. U , io.if_correct_process.asBool) for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_status(i)) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_counter(i)) } fsm_state := Mux (fsm_ini.asBool, Mux (io.ic_run_isax.asBool, fsm_sch, fsm_presch), fsm_sch) }
功能 :重置流水线停滞标志。
根据 io.ic_run_isax 决定是否进入调度状态。
状态转移 :如果 io.ic_run_isax 有效,进入 fsm_sch,否则保持当前状态。
c. fsm_sch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 is (fsm_sch) { end := end ctrl := ctrl crnt_target := crnt_target crnt_mask := crnt_mask nxt_target := Mux (!ic_status(sch_result).asBool && io.if_correct_process.asBool, sch_result, nxt_target) if_filtering := 0. U if_pipeline_stall := io.if_correct_process.asBool for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_status(i)) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_counter(i)) } fsm_state := Mux (!ic_status(sch_result).asBool && io.if_correct_process.asBool, fsm_cooling, fsm_sch) }
功能 :更新目标核心 nxt_target。
根据 io.if_correct_process 和核心状态决定状态转移。
状态转移 :如果 sch_result 的状态为空闲且 io.if_correct_process 有效,进入 fsm_cooling。
否则保持当前状态。
d. fsm_cooling is (fsm_cooling) {
功能 :如果冷却完成,进入快照状态。
否则保持冷却状态。
状态转移 :进入 fsm_snap。
e. fsm_snap 1 2 3 4 5 6 7 8 9 10 11 12 is (fsm_snap) { end := end ctrl := Mux ((ctrl === 2. U ) || (ctrl === 0. U ), Mux (io.if_ready_snap_shot.asBool && io.if_correct_process.asBool, Cat (ctrl, crnt_target), crnt_mask), Mux (io.if_ready_snap_shot.asBool, Cat (ctrl, crnt_target), crnt_mask)) nxt_target := nxt_target if_filtering := 0. U if_pipeline_stall := io.if_correct_process.asBool for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , Mux ((crnt_target === i.U ) && (ctrl(0 ) === 0. U ), 1. U , ic_status(i))) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_counter(i)) } fsm_state := Mux ((ctrl === 2. U ) || (ctrl === 0. U ), Mux (io.if_ready_snap_shot.asBool && io.if_correct_process.asBool, fsm_trans, fsm_snap), Mux (io.if_ready_snap_shot.asBool, fsm_trans, fsm_snap)) }
功能 :根据控制信号 ctrl 和 io.if_ready_snap_shot 决定下一步操作。
更新核心状态。,此时会选择检查核心,然后置高ic_status
状态转移 :进入 fsm_trans。
f. fsm_trans 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 is (fsm_trans) { end := Mux (!end.asBool && (ic_exit_isax_buffer.asBool || io.ic_exit_isax.asBool), Mux (!io.rsu_busy.asBool, 1. U , end), end) ctrl := Mux (!end.asBool && (ic_exit_isax_buffer.asBool || io.ic_exit_isax.asBool), Mux (!io.rsu_busy.asBool, 3. U , ctrl), ctrl) crnt_target := crnt_target crnt_mask := crnt_mask nxt_target := nxt_target if_filtering := 0. U if_pipeline_stall := io.if_correct_process.asBool for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_status(i)) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_counter(i)) } fsm_state := Mux (end.asBool, Mux (!io.rsu_busy.asBool, fsm_reset, fsm_trans), Mux (ic_exit_isax_buffer.asBool || io.ic_exit_isax.asBool, Mux (!io.rsu_busy.asBool, fsm_postcheck, fsm_trans), Mux (ctrl === 3. U , Mux (!io.rsu_busy.asBool, fsm_reset, fsm_trans), Mux (ctrl === 1. U , fsm_presch, fsm_check)))) }
功能 :根据 end 和 io.rsu_busy 决定是否复位。
根据 ic_exit_isax_buffer 和 io.ic_exit_isax 决定状态转移。
状态转移 :如果 end 有效,且 io.rsu_busy 无效,进入 fsm_reset。
否则保持当前状态。
g. fsm_check 1 2 3 4 5 6 7 8 9 10 11 12 13 14 is (fsm_check) { end := end ctrl := Mux (io.ic_exit_isax.asBool, 3. U , Mux (io.ic_syscall.asBool || if_t_and_na.asBool, 1. U , Mux (if_t_and_a.asBool, 0. U , ctrl))) crnt_target := crnt_target crnt_mask := crnt_mask nxt_target := nxt_target if_filtering := Mux (io.ic_exit_isax.asBool || io.ic_syscall.asBool || (ic_counter(crnt_target) >= io.ic_threshold) || io.icsl_na(crnt_target).asBool, 0. U , 1. U ) if_pipeline_stall := Mux (io.ic_exit_isax.asBool || io.ic_syscall.asBool || (ic_counter(crnt_target) >= io.ic_threshold) || io.icsl_na(crnt_target).asBool, 1. U , 0. U ) for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_status(i)) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , Mux ((crnt_target === i.U ) && (io.if_correct_process.asBool) && (!io.ic_syscall.asBool), (ic_counter(i) + io.ic_incr), ic_counter(i))) } fsm_state := Mux (io.ic_exit_isax.asBool || io.ic_syscall.asBool || (ic_counter(crnt_target) >= io.ic_threshold) || io.icsl_na(crnt_target).asBool, fsm_postcheck, fsm_check) }
功能 :更新控制信号 ctrl。
根据条件更新过滤标志和流水线停滞。
更新核心计数器。
状态转移 :如果满足退出条件,进入 fsm_postcheck。(system call,指令達到阈值,小核心lsl满了)
否则保持当前状态。
在该阶段有三个退出check的条件
h. fsm_postcheck 1 2 3 4 5 6 7 8 9 10 11 12 13 14 is (fsm_postcheck) { end := end ctrl := ctrl crnt_target := crnt_target crnt_mask := crnt_mask nxt_target := nxt_target if_filtering := 0. U if_pipeline_stall := io.if_correct_process.asBool for (i <- 0 to params.totalnumber_of_cores - 1 ) { ic_status(i) := Mux (clear_ic_status(i).asBool, 0. U , ic_status(i)) ic_counter(i) := Mux (clear_ic_status(i).asBool, 0. U , Mux ((crnt_target === i.U ), (ic_counter(i) | 0x8000 .U ), ic_counter(i))) } fsm_state := Mux (ctrl === 0. U , fsm_sch, fsm_cooling) }
功能 :更新核心计数器。
根据控制信号 ctrl 决定状态转移。
状态转移 :如果 ctrl === 0.U,进入 fsm_sch。
否则进入 fsm_cooling。
输出信号 crnt_target:为crnt_mask,只有在fsm_snap阶段才会赋值为Cat(ctrl, crnt_target)
if_pipeline_stall:该信号可以停止ROB提交,在fsm_check阶段会去根据三个条件置为高,其他阶段均和if_correct_process有关(除reset)
if_dosnap:快照信号
ic_counter:计数提交的指令
ic_status:正在运行核心的状态
shared_CP_CFG:Cat(one, cp_bitmap, core_bitmap),这个个人理解就是得出现在调度核与下一个要调度的核心
R_RSU解读 RSU主要作用就是去维护一个快照状态
记录快照状态
1 2 3 4 5 6 7 8 when (doSnapshot === 1.U) { for (i <- 0 until params.numARFS) { arfs_ss(i) := io.arfs_in(i) farfs_ss(i) := io.farfs_in(i) } pcarf_ss := io.pcarf_in fcsr_ss := io.fcsr_in }
merge逻辑
主要看merge_counter,该cnt指示要去传什么idx的arf,0-31传fp和int寄存器,32传pc和fcsr
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 if (GH_GlobalParams.IF_THERE_IS_CDC){ val merge_cdc_counter = RegInit(0.U(1.W)) when ((doMerge === 1.U) && (merging === 0.U)){ merging := 1.U merge_counter := 0.U merge_cdc_counter := 0.U } .elsewhen (merging === 1.U) { merging := Mux((merge_counter === 32.U) && (merge_cdc_counter === 1.U), 0.U, 1.U) merge_counter := Mux(merge_cdc_counter === 1.U, Mux((merge_counter === 32.U), 0.U, merge_counter + 1.U), merge_counter) merge_cdc_counter := merge_cdc_counter + 1.U } .otherwise { merging := merging merge_counter := merge_counter } } ... io.arfs_merge(0) := MuxCase(0.U, Array(((merging === 1.U) && (merge_counter =/= 32.U)) -> Cat(farfs_ss(merge_counter), arfs_ss(merge_counter)), ((merging === 1.U) && (merge_counter === 32.U)) -> Cat(zeros_56bits, fcsr_ss, zeros_24bits, pcarf_ss) ) ) io.arfs_index(0) := Mux((merging === 1.U), (merge_counter), 0.U) io.arfs_pidx(0) := Mux((merging === 1.U), Cat(io.ic_crnt_target(4,0), seven_3bits), 0.U)
在merge期间需要置高core_hang_up
rsu_bsy揭示了rsu的忙状态
core与rsu,ic交互 core与rsu和ic交互主要就是stall信号,两模块均可阻塞rob提交,其他信号就是来自外部的配置信号,以及送入外部的配置信号
小核部分 信号定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 val arfs_if_CPS = UInt(1.W).asInput val record_pc = UInt(1.W).asInput val ic_counter = UInt(20.W).asInput val clear_ic_status = UInt(1.W).asOutput val pc = UInt(vaddrBitsExtended.W).asOutput val inst = UInt(32.W).asOutput val new_commit = UInt(1.W).asOutput val clk_enable_gh = Bool().asInput val alu_2cycle_delay = UInt(p(XLen).W).asOutput val csr_rw_wdata = UInt(p(XLen).W).asOutput val packet_arfs = UInt(GH_GlobalParams.GH_WIDITH_PACKETS.W).asInput val packet_lsl = UInt(GH_GlobalParams.GH_WIDITH_PACKETS.W).asInput val packet_lsl1 = UInt(GH_GlobalParams.GH_WIDITH_PACKETS.W).asInput val packet_cdc_ready = UInt(1.W).asOutput val arf_copy_in = UInt(1.W).asInput val rsu_status = UInt(2.W).asOutput val s_or_r = UInt(1.W).asInput val lsl_near_full = UInt(1.W).asOutput val ght_prv = UInt(2.W).asOutput val if_correct_process = UInt(1.W).asInput val elu_data = UInt(GH_GlobalParams.GH_WIDITH_PERF.W).asOutput val elu_deq = UInt(1.W).asInput val elu_sel = UInt(1.W).asInput val elu_status = UInt(2.W).asOutput val icsl_status = UInt(2.W).asOutput val core_trace = UInt(1.W).asInput val record_and_store = UInt(2.W).asInput val debug_perf_ctrl = UInt(5.W).asInput val lsl_highwatermark = UInt(1.W).asOutput
new_commit使用的是从csr来的valid,实际上也是wb阶段的valid经过处理得到的
1 2 3 4 5 6 7 8 9 io.pc := wb_reg_pc io.inst := wb_reg_inst io.new_commit := csr.io.trace(0).valid && !csr.io.trace(0).exception io.csr_rw_wdata := csr.io.rw.wdata /* R Features */ val rsu_pc = Reg(UInt(width=40)) val checker_mode = Wire(UInt(width=1)) ibuf.io.checker_mode := checker_mode
R_RSUSL解读 信号定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 val arfs_out = Output(UInt(params.xLen.W)) val farfs_out = Output(UInt(params.xLen.W)) val arfs_idx_out = Output(UInt(8.W)) val arfs_valid_out = Output(UInt(1.W)) val pcarf_out = Output(UInt(40.W)) val fcsr_out = Output(UInt(8.W)) val pfarf_valid_out = Output(UInt(1.W)) val core_hang_up = Output(UInt(1.W)) val arfs_merge = Input(UInt((params.xLen*2).W)) val arfs_index = Input(UInt(8.W)) val arfs_if_ARFS = Input(UInt(1.W)) val arfs_if_CPS = Input(UInt(1.W)) val paste_arfs = Input(UInt(1.W)) val rsu_status = Output(UInt(2.W)) val clear_ic_status = Input(UInt(1.W)) val cdc_ready = Output(UInt(1.W)) val do_cp_check = Input(UInt(1.W)) val if_cp_check_completed = Output(UInt(1.W)) val core_arfs_in = Input(Vec(params.numARFS, UInt(params.xLen.W))) val core_farfs_in = Input(Vec(params.numARFS, UInt(params.xLen.W))) val elu_cp_deq = Input(UInt(1.W)) val elu_cp_data = Output(UInt((4*params.xLen+8).W)) val elu_status = Output(UInt(1.W)) val core_trace = Input(UInt(1.W)) val record_context = Input(UInt(1.W)) val store_from_checker = Input(UInt(1.W)) // 0: from main; 1: from checker. val core_id = Input(UInt(4.W)) // 0: from main; 1: from checker. val starting_CPS = Output(UInt(1.W))
packet入队逻辑 当if_RSU_packet信号为高,说明有有效的packge,此时接授arfs和farfs,同时告诉外界开始接受snapshot(starting_CPS),并且将snapshot信息写入arfs_ss和farfs_ss,注意pc是最后一个包
1 2 3 4 5 6 7 8 9 10 11 12 13 if_RSU_packet := Mux(io.arfs_if_ARFS.asBool && io.arfs_if_CPS.asBool, 1.U, 0.U) packet_valid := Mux(if_RSU_packet === 1.U, 1.U, 0.U) packet_arfs := Mux(if_RSU_packet === 1.U, io.arfs_merge(63,0), 0.U) packet_farfs := Mux(if_RSU_packet === 1.U, io.arfs_merge(127,64), 0.U) packet_index := Mux(if_RSU_packet === 1.U, io.arfs_index, 0.U) io.starting_CPS := if_RSU_packet.asBool && (packet_index === 0.U) when (packet_valid === 1.U) { arfs_ss.write(packet_index, packet_arfs) farfs_ss.write(packet_index, packet_farfs) } pcarfs_ss := Mux(packet_valid.asBool && (packet_index === 0x20.U), packet_arfs(39,0), pcarfs_ss) rsu_status := Mux(io.clear_ic_status.asBool, 0.U, Mux(packet_index === 0x20.U, 1.U, Mux(packet_index_ECP === 0x20.U, 3.U, rsu_status)))
保存checker状态 record_and_store信号来自ROCC,该保存状态逻辑和之前大核类似,只不过将寄存器堆变为了sram
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 when (io.record_context.asBool && !recording_context) { recording_context := true.B recording_counter := 0.U } .elsewhen (recording_context === 1.U){ recording_context := Mux(recording_counter === 0x20.U, false.B, true.B) recording_counter := Mux(recording_counter === 0x20.U, 0.U, recording_counter + 1.U) } .otherwise { recording_context := recording_context recording_counter := recording_counter } when (recording_context) { arfs_ss_GMode.write(recording_counter, io.core_arfs_in(recording_counter)) farfs_ss_GMode.write(recording_counter, io.core_farfs_in(recording_counter)) }
应用snapshot状态 通过设置计数器来达到每周期恢复2个寄存器(int,fp),paste_arfs来自ROCC指令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 apply_snapshot_memdelay := apply_snapshot apply_counter_memdelay := apply_counter arf_addr := Mux(apply_snapshot.asBool, apply_counter, 0.U) farf_addr := Mux(apply_snapshot.asBool, apply_counter, 0.U) arf_data := Mux(!io.store_from_checker, arfs_ss.read(arf_addr, apply_snapshot.asBool), arfs_ss_GMode.read(arf_addr, apply_snapshot.asBool)) farf_data := Mux(!io.store_from_checker, farfs_ss.read(farf_addr, apply_snapshot.asBool), farfs_ss_GMode.read(arf_addr, apply_snapshot.asBool)) when ((io.paste_arfs === 0x01.U) && (apply_snapshot === 0.U)) { apply_snapshot := 1.U apply_counter := 0.U } .elsewhen (apply_snapshot === 1.U){ apply_snapshot := Mux(apply_counter === 0x20.U, 0.U, 1.U) apply_counter := Mux(apply_counter === 0x20.U, 0.U, apply_counter + 1.U) } .otherwise { apply_snapshot := apply_snapshot apply_counter := apply_counter } val arfs_out_printf = Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), arf_data, 0.U) val arfs_out_valid_printf = Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), 1.U, 0.U) val arfs_out_idx = Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), apply_counter_memdelay, 0.U) io.arfs_out := Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), arf_data, 0.U) io.farfs_out := Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), farf_data, 0.U) io.arfs_idx_out := Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), apply_counter_memdelay, 0.U) io.arfs_valid_out := Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay =/= 0x20.U)), 1.U, 0.U) val pcarfs_ss_delay = RegInit(0.U(40.W)) pcarfs_ss_delay := pcarfs_ss if (GH_GlobalParams.GH_DEBUG == 1) { when ((io.core_trace.asBool) && (pcarfs_ss_delay =/= pcarfs_ss)) { printf(midas.targetutils.SynthesizePrintf("[C%x-CPS] = [%x]\n", io.core_id, pcarfs_ss)) } when ((io.core_trace.asBool) && (packet_valid_ECP.asBool) && (packet_index_ECP === 0x20.U)) { // printf(midas.targetutils.SynthesizePrintf("[C%x-CPE] = [%x]\n", io.core_id, packet_arfs_ECP)) } } io.pcarf_out := pcarfs_ss io.fcsr_out := Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay === 0x20.U)), farf_data, 0.U) io.pfarf_valid_out := Mux(((apply_snapshot_memdelay === 1.U) && (apply_counter_memdelay === 0x20.U)), 1.U, 0.U) io.cdc_ready := packet_valid | packet_valid_ECP io.rsu_status := rsu_status
输出检查信号 该模块根据do_cp_check置高检查do_check,之后根据checking_counter_memdelay来输出if_cp_check_completed,同时当RSU工作时需要停止core,该信号送入icsl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 // Faking ELU data val checking_counter_memdelay = RegInit(0.U(2.W)) checking_counter_memdelay := checking_counter val if_check_completed = WireInit(0.U(1.W)) when (!do_check.asBool) { do_check := Mux(io.do_cp_check.asBool && !if_check_completed.asBool, 1.U, 0.U) checking_counter := Mux(io.clear_ic_status.asBool, 0.U, checking_counter) } .otherwise { do_check := Mux(if_check_completed.asBool, 0.U, 1.U) checking_counter := Mux(checking_counter === 0x2.U, checking_counter, checking_counter + 1.U) } if_check_completed := (checking_counter_memdelay === 0x2.U).asUInt io.if_cp_check_completed := if_check_completed io.core_hang_up := apply_snapshot | apply_snapshot_memdelay | io.record_context | recording_context | (do_check.asBool && !if_check_completed.asBool) io.elu_cp_data := 0.U io.elu_status := 0.U
R_ICSL解读 FSM转化条件
从 fsm_reset 到 fsm_nonchecking :
初始化所有寄存器。
设置 clear_ic_status 为 1。
设置 icsl_checkermode 为 0。
设置 if_rh_cp_pc 为 0。
转移到 fsm_nonchecking 状态。
从 fsm_nonchecking 到 fsm_checking :
如果 icsl_run 有效,转移到 fsm_checking 状态。
否则保持在 fsm_nonchecking 状态。
从 fsm_checking 到 fsm_postchecking :
如果 if_instants_completion 或 if_slow_completion 有效,并且 something_inflight 无效,转移到 fsm_postchecking 状态。
否则保持在 fsm_checking 状态。
从 fsm_postchecking 到 fsm_reset :
如果 returned_to_special_address_valid 有效,转移到 fsm_reset 状态。
否则保持在 fsm_postchecking 状态。
在checking阶段,sl_counter会根据提交指令增加,当sl_counter>=ic_counter_shadow,说明完成该代码段的执行if_instants_completion,
这里给出了检查完成信号,
1 2 3 4 val if_instants_completion = Mux((io.if_correct_process.asBool && io.new_commit.asBool && ((sl_counter + 1.U) >= ic_counter_shadow) && ic_counter_done.asBool), 1.U, 0.U) val if_slow_completion = Mux((io.if_correct_process.asBool && (sl_counter >= ic_counter_shadow) && ic_counter_done.asBool), true.B, false.B) val if_just_overtaking = Mux((io.if_correct_process.asBool && io.new_commit.asBool && ((sl_counter + 1.U) >= ic_counter_shadow)), 1.U, 0.U)
当在fsm_postchecking状态,if_rh_cp_pc置高,表示完成执行,如果此时returned_to_special_address_valid为高,也就是执行最后一条返回指令,此时完成检查整个流程
输出信号介绍
icsl_if_ret_special_pc:当rsu发出完成检查信号并且目前位于checkmode,此时发出icsl_if_ret_special_pc信号,表示icache下一次取指令的为pc_special
if_rh_cp_pc:表示完成检查,准备返回
icsl_stalld:停止流水线,这个主要在检查后阶段执行
if_overtaking:这个信号个人理解是杀去一些div和fpu指令
然后该阶段设置了一系列性能计数器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ic_counter_shadow := io.ic_counter(params.width_of_ic-2,0) + 1.U // The checker core requires to run one more insts due to the custom jump ic_counter_done := io.ic_counter(params.width_of_ic-1) if_overtaking := Mux((if_just_overtaking.asBool || (sl_counter >= ic_counter_shadow)), 1.U, 0.U) val if_overtaking_next_cycle = WireInit(0.U(1.W)) if_overtaking_next_cycle := Mux((if_just_overtaking.asBool || (sl_counter >= ic_counter_shadow)), 1.U, 0.U) if_ret_special_pc := Mux(io.if_check_completed.asBool && icsl_checkermode.asBool, 1.U, 0.U) icsl_run := io.icsl_run io.clear_ic_status := clear_ic_status io.icsl_checkermode := icsl_checkermode io.if_overtaking := (icsl_checkermode & if_overtaking) io.if_overtaking_next_cycle := (icsl_checkermode & if_overtaking_next_cycle) io.if_ret_special_pc := if_ret_special_pc io.if_rh_cp_pc := if_rh_cp_pc io.icsl_status := Mux(fsm_state === fsm_nonchecking, 1.U, 0.U) io.debug_sl_counter := sl_counter
R_LSL解读 ldst入队 入队信号如下,我们保证两个通道的fifo数据量一样,所以设置scala_ptr,该信号当来2笔数据时值不变,只有来1笔数据值才会改变,
scala_num_reqs为送入的数据数目
scala_ptr指示要写入哪个fifo
然后channel_enq_valid只有在有数据送入,如果scala_num_reqs为2,两个channel的enqvalid均为高,若为1,只有在scala_ptr=0时才会去置高,enq_data同样如此
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 has_data := io.m_st_valid.asBool || io.m_ld_valid.asBool || io.m_st_valid1.asBool || io.m_ld_valid1.asBool //来两笔数据+2等于不变,这个是为了保序用的 scala_ptr := Mux(has_data && (scala_num_reqs === 1.U), scala_ptr + 1.U, scala_ptr) //来了多少数据(最多为2) scala_num_reqs := Mux(io.m_st_valid.asBool || io.m_ld_valid.asBool || io.m_st_valid1.asBool || io.m_ld_valid1.asBool, Mux(((io.m_st_valid.asBool || io.m_ld_valid.asBool)) && (io.m_st_valid1.asBool || io.m_ld_valid1.asBool), 2.U, 1.U), 0.U) enq_data := Cat(io.m_st_valid, io.m_ld_valid, io.m_ldst_data, io.m_ldst_addr) enq_data1 := Cat(io.m_st_valid1, io.m_ld_valid1, io.m_ldst_data1, io.m_ldst_addr1) ... //这里enq_valid主要就是区分来的数据是1笔还是两笔,如果两笔数据,都可以入队,如果一笔数据,需要看scala_ptr,enq_data 同理 channel_enq_valid := Mux(has_data, Mux(scala_num_reqs === 2.U, 1.U, Mux(scala_ptr === 0.U, 1.U, 0.U)), 0.U) channel_enq_valid1 := Mux(has_data, Mux(scala_num_reqs === 2.U, 1.U, Mux(scala_ptr === 1.U, 1.U, 0.U)), 0.U) channel_enq_data := Mux(has_data, Mux(scala_num_reqs === 2.U, Mux(scala_ptr === 0.U, enq_data, enq_data1), Mux(scala_ptr === 0.U, enq_data, 0.U)), 0.U) channel_enq_data1 := Mux(has_data, Mux(scala_num_reqs === 2.U, Mux(scala_ptr === 0.U, enq_data1, enq_data), Mux(scala_ptr === 0.U, 0.U, enq_data)), 0.U)
ldst出队
出队逻辑同样含scala_ptr_core,不过由于小核心为标量,故每次最多传输1笔
if_lsl_empty根据scala_ptr_core值来选择输出哪个channel
resp_data和resp_addr根据scala_ptr_core选取对应的channel,最后的replay信号发生在输入有效但lsl没数据,输入有效,但该请求被kill
channel_deq_ready信号根据scala_ptr_core设置ready信号,前提lsl不能为空并且req_kill不为高
最后ld_deq,st_deq根据cahnnel和cmde是否置高
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 val if_lsl_empty = Mux(scala_ptr_core === 0.U, channel_empty, channel_empty1) scala_ptr_core := Mux((io.req_valid & !if_lsl_empty & !io.req_kill).asBool, scala_ptr_core + 1.U, scala_ptr_core) req_valid_reg := io.req_valid resp_valid_reg := io.req_valid & !if_lsl_empty & !io.req_kill resp_tag := io.req_tag cmd := io.req_cmd req_size_reg := io.req_size io.req_ready := !if_lsl_empty io.resp_valid := resp_valid_reg io.resp_tag := resp_tag // Revisit io.resp_size := Mux((resp_valid_reg === 1.U), req_size_reg, 0.U) io.resp_data := Mux((resp_valid_reg === 1.U), Mux(scala_ptr_core === 0.U, channel_deq_data1(127, 64), channel_deq_data(127, 64)), 0.U) io.resp_addr := Mux((resp_valid_reg === 1.U), Mux(scala_ptr_core === 0.U, channel_deq_data1(63, 0), channel_deq_data(63, 0)), 0.U) io.resp_has_data := Mux((resp_valid_reg === 1.U) && (cmd(0) === 1.U), 1.U, 0.U) io.resp_replay := req_valid_reg & !resp_valid_reg & !resp_kill_reg channel_deq_ready := io.req_valid & !if_lsl_empty & !io.req_kill & (scala_ptr_core === 0.U) channel_deq_ready1 := io.req_valid & !if_lsl_empty & !io.req_kill & (scala_ptr_core === 1.U) io.ld_deq := Mux(channel_deq_ready || channel_deq_ready1, Mux(io.req_cmd === 0x01.U, 1.U, 0.U), 0.U) io.st_deq := Mux(channel_deq_ready || channel_deq_ready1, Mux(io.req_cmd === 0x02.U, 1.U, 0.U), 0.U)
CSR入队出队和LDST类似,故不作解释
最后会输出LDST的channel是否满了,只有当四个CHANNEL全部为空,这时候if_empty才为空
1 2 3 4 5 6 7 8 9 10 io.resp_data_csr := Mux((scala_ptr_core_csr === 0.U), csr_channel_deq_data, csr_channel_deq_data1) // io.resp_replay_csr := (io.req_valid_csr === 1.U) && csr_channel_empty scala_ptr_core_csr := Mux((io.req_valid_csr === 1.U) && !if_csr_empty, scala_ptr_core_csr + 1.U, scala_ptr_core_csr) io.cdc_ready := has_data || has_data_csr io.near_full := u_channel(0).io.status_fiveslots | u_channel(1).io.status_fiveslots | csr_channel_nearfull | csr_channel_nearfull1 io.req_ready_csr := !if_csr_empty io.if_empty := csr_channel_empty & csr_channel_empty1 & channel_empty & channel_empty1 io.lsl_highwatermark := u_channel(0).io.high_watermark | u_channel(1).io.high_watermark | u_channel_csr(0).io.status_fiveslots | u_channel_csr(1).io.status_fiveslots
其中lsl_highwatermark,lsl_near_full最终会送往大核,来指示LSL状态
R_ELU解读 该模块主要就是检查ld和st是否错误,对于ld,只需检查地址,而st需要检查地址和数据
1 2 err_ld := Mux(ld_valid && (req_addr_reg(11,0) =/= io.lsl_resp_addr(11,0)), true.B, false.B) err_st := Mux(st_valid && ((req_addr_reg(11,0) =/= io.lsl_resp_addr(11,0)) || (req_data_wire =/= resp_data_wire)), true.B, false.B)
如果发生错误,会将错误信息写入fifo
1 2 3 4 5 6 7 err_log_ld := Cat(io.wb_pc, resp_data_wire, useless_ones, io.lsl_resp_addr, req_addr_reg) // load data is not compared err_log_st := Cat(io.wb_pc, resp_data_wire, req_data_wire, io.lsl_resp_addr, req_addr_reg) err_log := MuxCase(0.U, Array(err_ld -> err_log_ld, err_st -> err_log_st ) )
最后FIFO的出队逻辑elu_deq来自软件的ROCC指令
这里的elu_data和elu_status都没使用,elu_status传入了GHE但没使用
检测到错误如何进行之后操作
数据传输源码修改部分 大核:
MEEK/Hardware/big/common/tile.scala
MEEK/Hardware/big/exu/core.scala
MEEK/Hardware/big/exu/rob.scala
MEEK/Hardware/big/ifu/fetch-target-queue.scala
MEEK/Hardware/big/lsu/lsu.scala
top:
MEEK/Hardware/top/System.scala
MEEK/Hardware/top/CustomBusTopologies.scala
MEEK/chipyard/generators/chipyard/src/main/scala/Subsystem.scala
MEEK/Hardware/top/config/RocketConfigs.scala
小核:
MEEK/Hardware/little/tile/BaseTile.scala
MEEK/Hardware/little/rocket/RocketCore.scala
MEEK/Hardware/little/rocket/CSR.scala
MEEK/Hardware/little/r
MEEK/Hardware/little/guardiancouncil
MEEK/Hardware/little/subsystem/HasTiles.scala
MEEK/Hardware/little/tile/RocketTile.scala
MEEK/Hardware/little/tile/LazyRoCC.scala
MEEK/Hardware/little/subsystem/BusTopology.scala
MEEK/chipyard/generators/rocket-chip/src/main/scala/subsystem/Configs.scala
在移植过程中,会有很多目前不兼容的case,不过都可以通过报错的backtrace解决
随笔 发现PRF大核传输不是用的CDC而是直接node传过去的
prf传输是独立的,只有在prf传输完成,才可以进行校验,在这个期间大核仍然可以提交指令,但不会在小核心执行
ght——filter要做的事情就是将大核心commit的数据每个周期传输一个包,但可能有的buffer没有有效包,这里的设计和ibuf理念仍然一样:
有n个不定的输入,1个输出,如何去输出数据
GHT的rsu_merging是否真正有用?外部被置为0,ght_filters_ready也没用到
寄存器传输需要多8bit,因为需要状态位+idx
这里每次传输都是2个包,所以可以只判断低位
目前可配置数据可以泡通,但是时间比之前长,具体就是csr的lsl经常满,(相对之前来说,可能是CDC少打了一拍?)
性能计数器如何添加?
1.延迟如何计算?
2.slowdown如何计算?
3.数据吞吐如何添加?
只要进入checkmode,就记录cycle?然后记录发出的包?
但只有ldst才会存入这个包?
对于数据输入:大核可以统计ld和stcommit的数据,也就是包的总数,但CDC只要ready就可以发送?
从哪个时间开始测试:
这些性能事件可以通过csr直接读取
一种设计思路:根据此次调度来存入不同的CDC FIFO
假设4个CDC FIFO:每个CDC入队时钟域为boom的时钟域,出队时钟域为各个rocket的时钟域,入队时根据不同的调度信息写入不同的FIFO
如果这样做:
CDC路线:
1.先对数据信号CDC
2.在对控制信号CDC
3.重新整理入队出队信号
LSL的high——water会导致大核调度下一个核心,也是小核心无法接受数据的信号
下游何时可以接受数据:
1.调度信号为该核心,
下游如何去打断上游?
CDC需要考虑的情况 数据传输:
全部得反压,且目前设置的不可配置
小核心切换:
情况1:
1.小核心lsl将近满
2.此时小核心通过该CDC将控制信号传入大核心,(这里会延迟几个周期(CDC必须消耗的周期),所以可能导致这个真空期会有大核数据存入CDC FIFO)
3.大核接收到high water信号,准备切换checker和状态,切换完成向小核心发出ack(为了将真空期 写入的数据读出)
4.ack信号经过CDC传入小核心,此时小核心会去检查CDC FIFO是否有数据(也即是真空期大核是否写入数据),如果有数据,需要读完这些数据,没数据可以直接进入postcheck,然后清空ic_status,向大核发出clear_ic_status请求
这种做法会导致小核心状态延迟被消除,这个是因为CDC引入了真空期
需要注意的是,小核心的cdc_ready需要和high water区分,至少留出余量,防止真空期写满导致数据丢失,(好像这里不用做出区分,如果满了,CDC FIFO会暂存),还有一个可能不常见的情况:CDC也满了,这样会导致数据丢失?
小核心检查cdc是否空时,有没有可能出现假空?
不大可能:大核心的ack传入小核心需要CDC,此时如果之前有数据写入,数据CDC FIFO已经读到正确的idx了(写指针已经同步到读端口),所以不会出现问题
最新做法:
小核心lsl满可以向大核心发出反压信号,大核心收到信号后会去停止执行,然后直接发送ic_cnt回来,小核心只需要执行到这个ic cnt就可以退出这个模式了
情况2:
1.小核心执行到目的的指令数目,和来自大核的ic_cnt对比,此时也会有真空期(大核的ic_cnt仍然在计数)
2.然后对比完成,转换状态,给出大核清除信号,大核此时去清除ic_status,注意此时大核可能执行的指令已经超过指令阈值,所以可能发生状态切换,导致错误
解决办法
1.所以小核心不应该去做ic_cnt对比,需要当大核心指令超过阈值,向小核心发出信号,小核心读取到信号后,需要对大核心的信号做出回应,执行完所有指令(cdc fifo空,lsl空,且pipeline无指令),然后大核心接到回应后切换状态,这样就可以去除CDC造成的真空期
2.继续原来的做法,也就是向小核心送入大核的cnt,然后根据这个cnt来得到stall(由于cdc存在延迟,所以不会出现问题),当大核心达到阈值的时候,向小核心发出done,此时小核心得到done(延迟几个周期,但不会出现问题),执行完成后,向大核发出clear
此时大核可能已经开始执行指令,但是不会出问题:
因为每个ic_status和cnt是独立的
同理,大核心发生ecall,执行退出命令,也是这样的做法
也就是checker切换分为两种情况 :
1.小核心lsl满,此时的CDC造成的真空期不可忽视,必须为小核心的LSL留出一定余量(其实也可以不用,反正都存在CDC FIFO),小核心执行完成后才会向大核心发出clear_status请求
2.其他情况,均和大核的执行状态有关,大核需要去向小核发出终止信号,小核心读取到信号必须向大核心信号做出回应,大核接受到回应才会去切换状态,改情况无真空期,但如果采用做法2,其实可以和1归为1类,和情况1的区别就是没有真空期
为什么需要对控制信号留出余量(depth>3)?
大核心写的太快,此时小核心读的慢,导致控制信号丢失,所以必须去暂存控制信号
必须反压或者采样
为什么控制信号不连续(主要出现在l2b)?
小核心写入太慢,大核心读取太快,导致FIFO经常空
这里也导致一个问题,控制信号不连续,需要做出对应处理?
1.为控制信号加入valid,只有fire的信号才是真正的控制信号
2.传输的控制信号必须要是单周期的信号,这样读出的信号才会是单周期的,否则可能出现不连续的情况,但是某些信号本来就不是单周期的,比如lsl high water
小核心的icsl状态转换处理?
当lsl满的时候,小核心需要去进入一个新的状态,也就是cdc_clear状态,当收到ack转换到该状态,然后如果cdc空了,且流水线执行完成,进入下一个状态)
其他情况时,(大核发生的事件导致小核心去切换),此时也要进入cdc_clear,cdc空后,且流水线执行完成,进入下一个状态
cdc_clear,也算是check状态,他的作用就是把CDC转化的真空期数据清空
为什么csr lsl满的很快?
解决方法:
当小核心执行到最后一条指令时,停止执行,看大核心是否已经完成这个的执行,如果完成执行,向小核心发出信号,然后小核心完成执行
目前需要解决的问题:
目前通过overtaking重新去重启取pc
需要去精确的停止在最后一个指令,此时需要去kill其他指令,且不能取指令
2025/4/10
为什么检查指令很短的时候会出错?
check speed在最后会出现问题
因为最后可能没有那么多指令,且大核可能执行没有小核心快,所以ic_cnt还是要传输,只不过需要三周期传一次,
解决办法:
为什么最后全部程序片段执行完成大核没有停止?
大核需要咨询小核心是否完成,最后信号传入大核为bigComp_reg,之前为wire变量,但由于目前基于采样,只能使用寄存器存储起来
如何反压检查点和数据的传输?
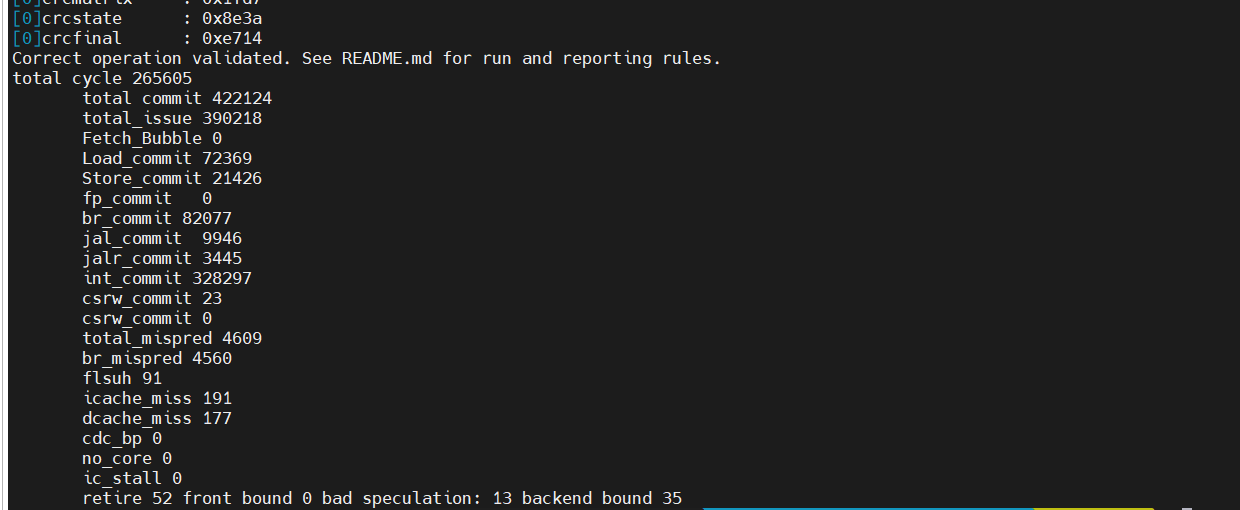
目前性能:
原来:81900
加入cdc,将指令改为3000:82155
加入cdc,将指令改为2:610325
2025/4/17
简化逻辑 GHT的转发是没必要的,在commit阶段其实可以直接传输数据了
问题:
新的逻辑给fence也转发了,导致逻辑出错,(fence竟然也是use_stq)
这个lsu的header好像有问题?
这里连续提交了三条指令,但是只有两条在header出现,ldq/stq_head指针溢出了,导致出错
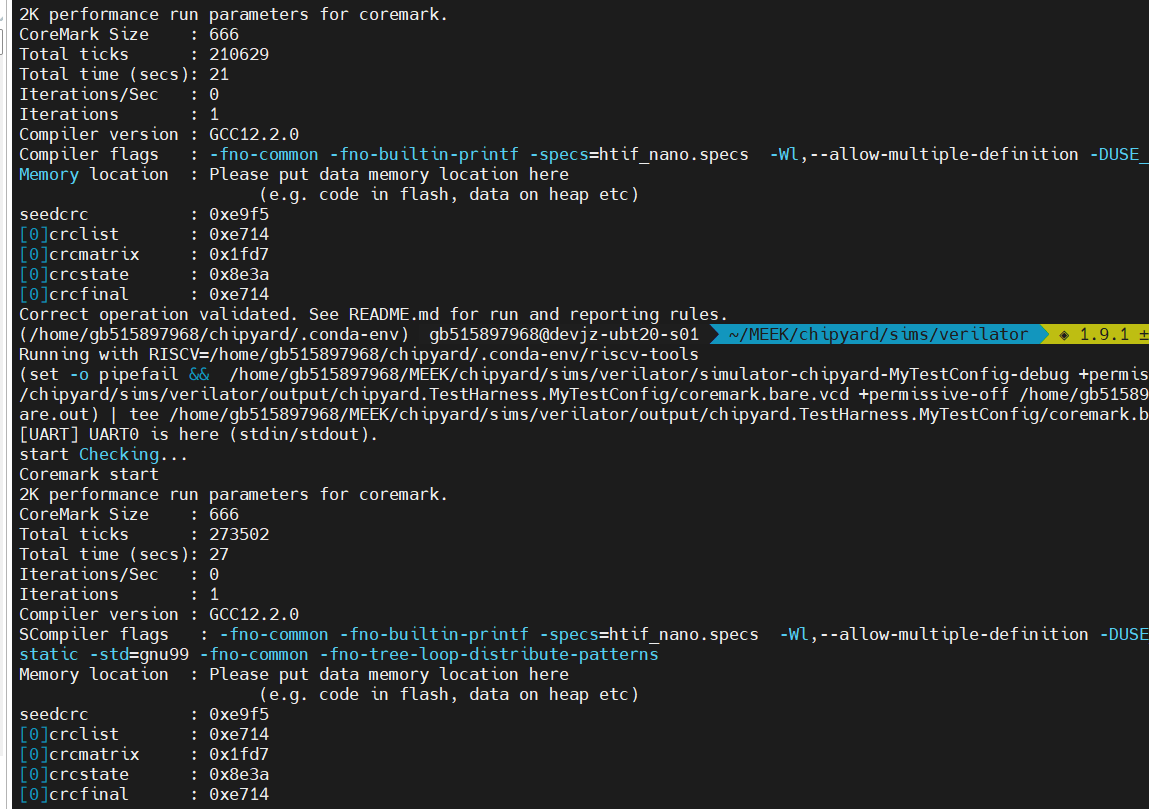
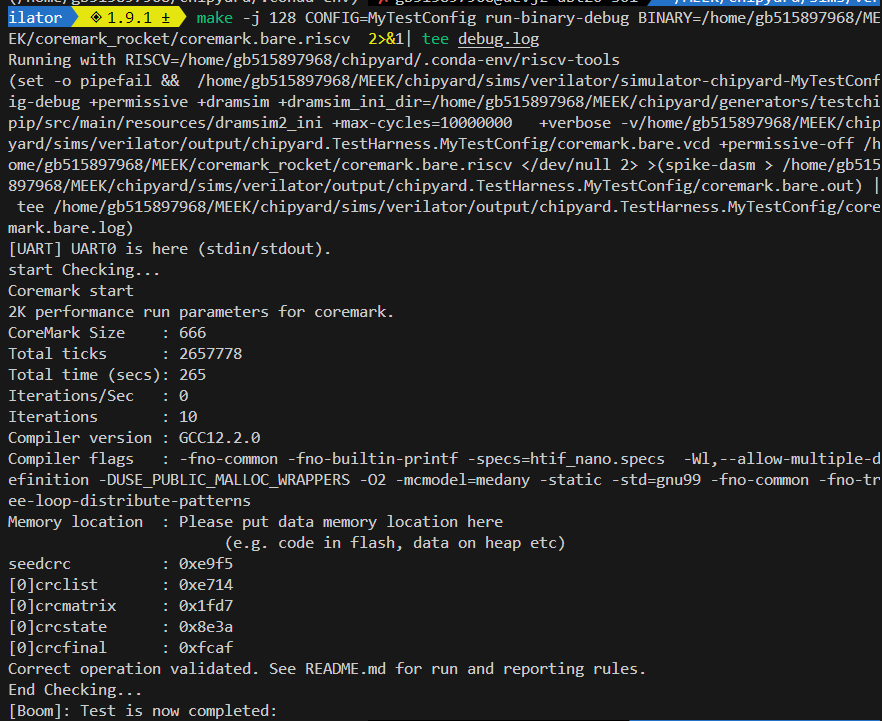
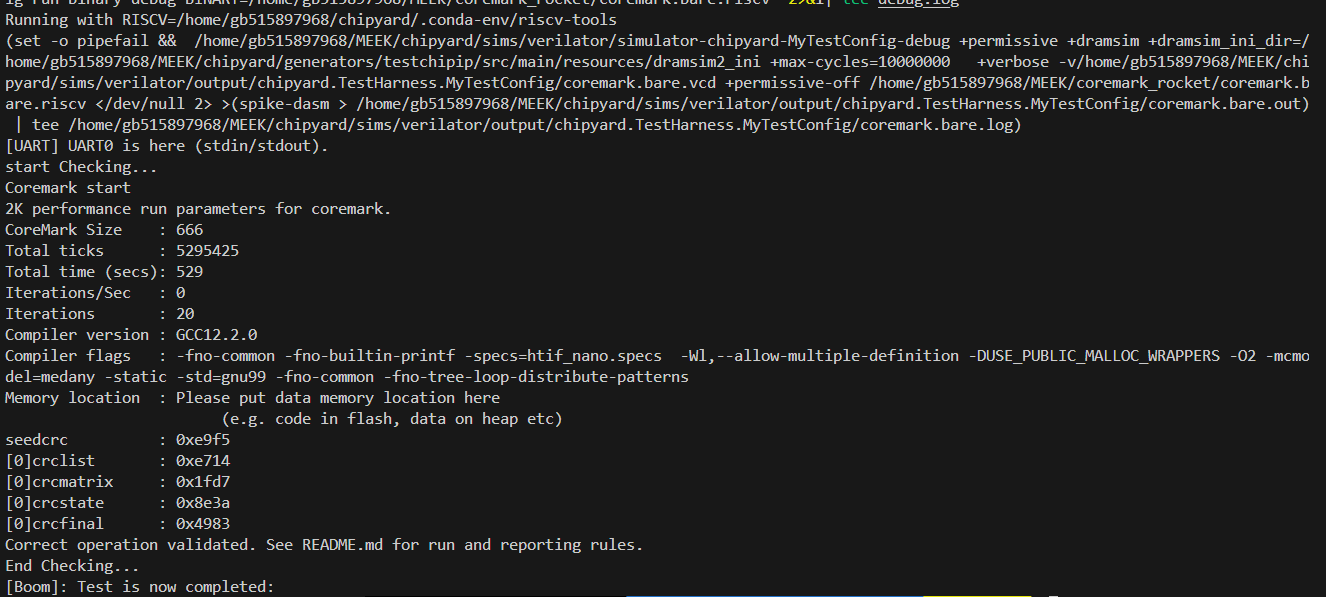
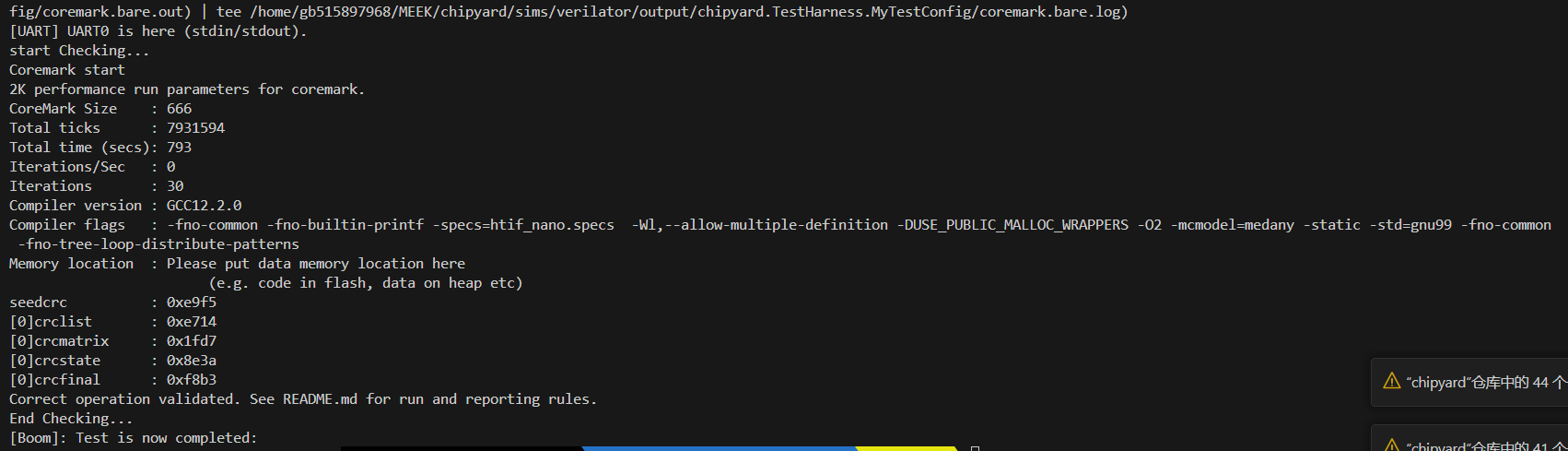
目前可以跑通一轮coremark :
未校验:21sec
校验:27sec
大概下降30%
不过coremark好像是计算密集型,可以很好的利用多发射的优势,导致大核早执行完成,但小核才刚开始跑,TC_Overtaking算是一直执行load/store(程序局部性差),即使大核也无法去利用其多发射的优势
小核调度情况
小核大核执行速度比较
前一个LD的包和下一个LD的包一起发送,导致一个包送入两个地方?
需要去判断两个包的目的核
10轮结果
20轮结果
30轮
1轮dhrystone
出现了之前跑50轮的错误,(好像是内存满了)
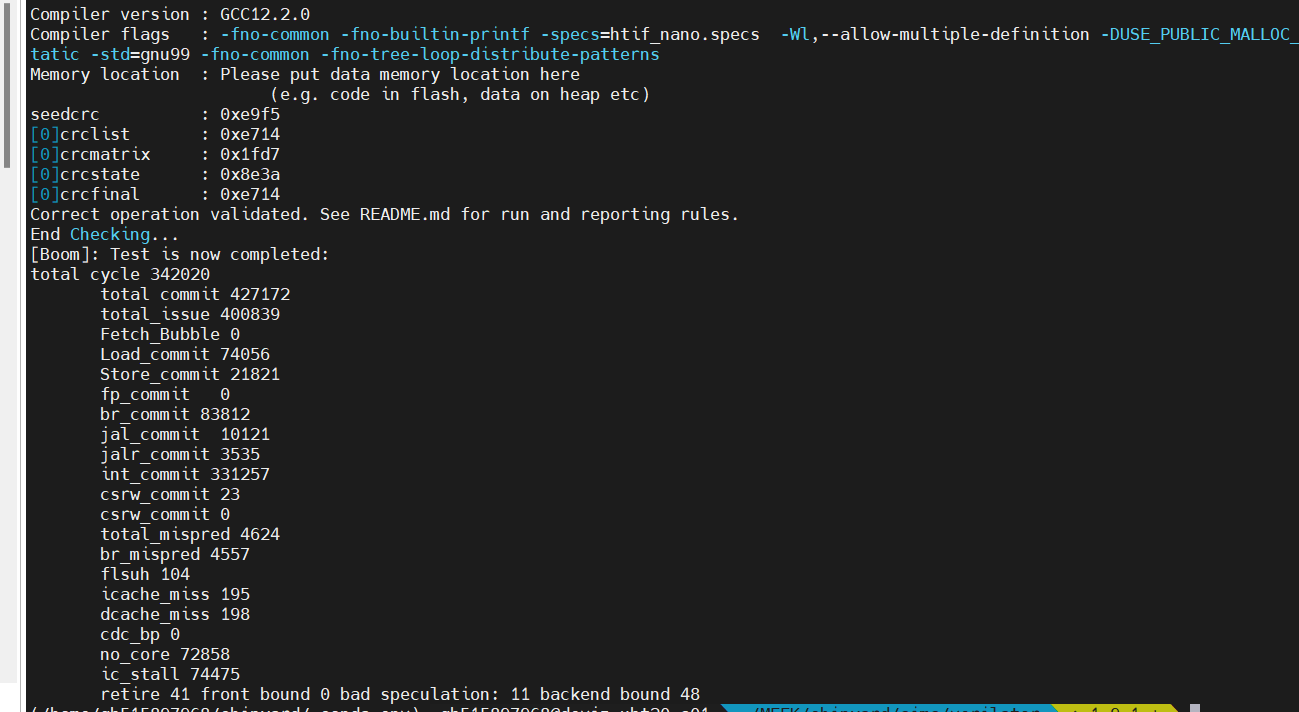
coremark一轮性能:
没开check
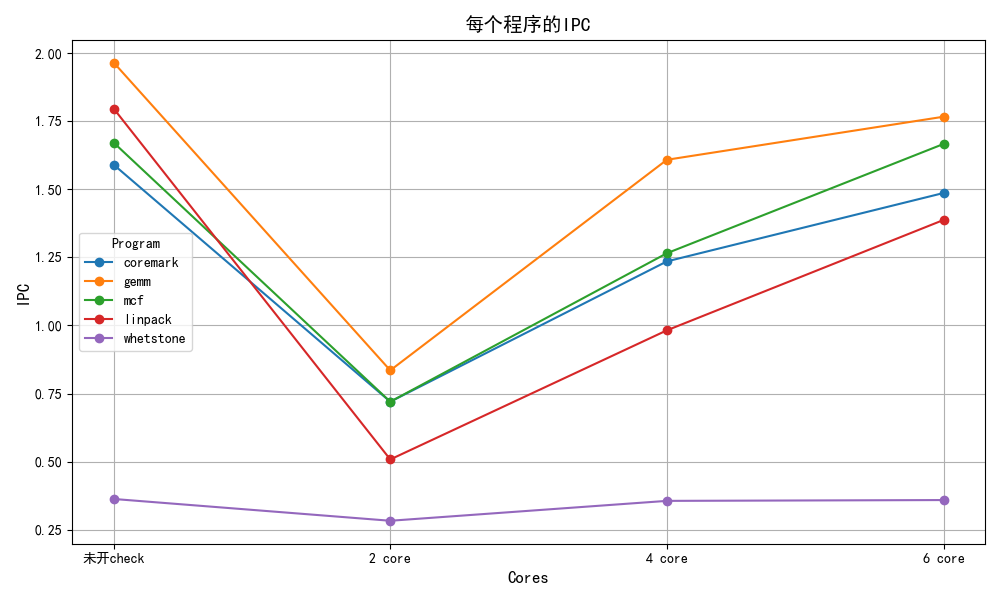
IPC
total cycle
cdc_bp
no_core_avaliable
ic_stall
未开check
1.59
265605
0
0
0
开check
1.235
342020
0
72858/21.3%/97.8%
74475/21.7%
Load
Store
br
jal
jalr
int
指令总数/占比
72369/17.1%
21426/5.1%
82077/19.4%
9946/2.4%
3445/0.8%
328257/77.8%
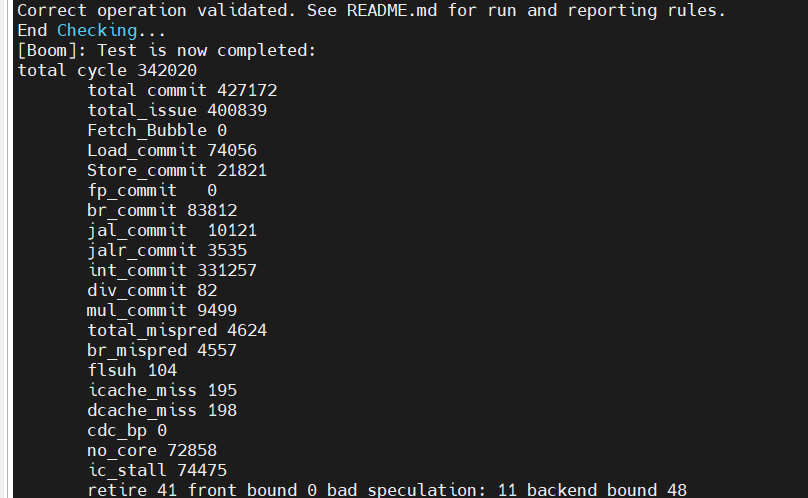
总体性能下降 :22.3%
slowdown:1.287
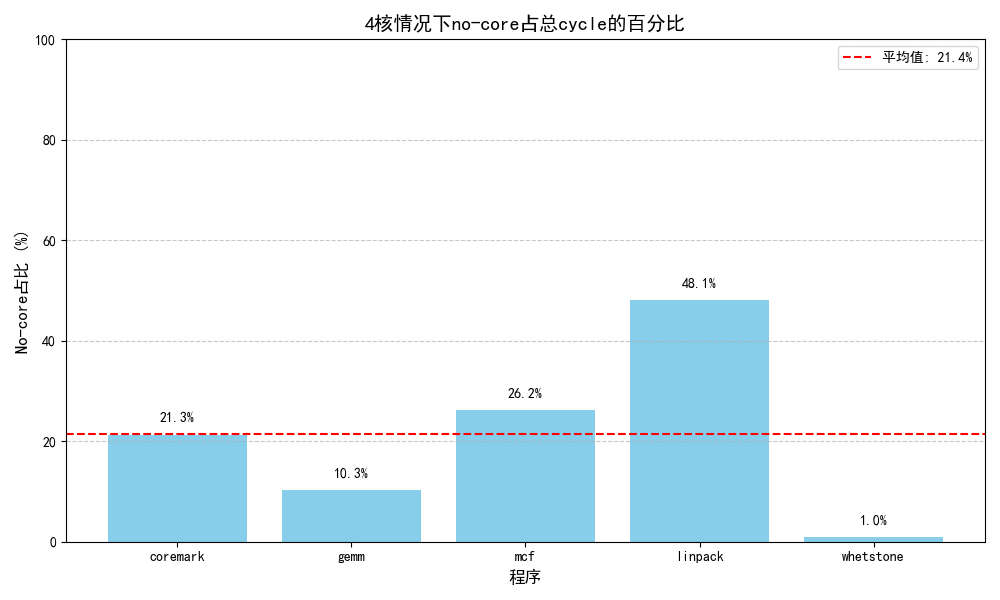
其中,no_core_avaliable占据了性能下降的最大部分(21%/95.5%)
5.6数据
四个小核执行
大核数据
Load
Store
br
jal
jalr
div
mul
指令总数/占比
72369/17.1%
21426/5.1%
82077/19.4%
9946/2.4%
3445/0.8%
82/0.02%
9499/2.2%
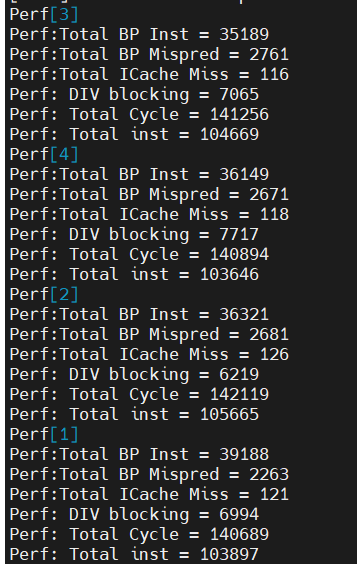
小核IPC
core1
core2
core3
core4
avag
IPC
0.73
0.745
0.744
0.734
0.74
分支误预测
5.8%
7.4%
7.8%
7.4%
7.1%
ICache缺失率
0.1%
0.1%
0.1%
0.1%
0.1%
DIV Block
5.0%
4.4%
5.5%
4.4%
5.0%
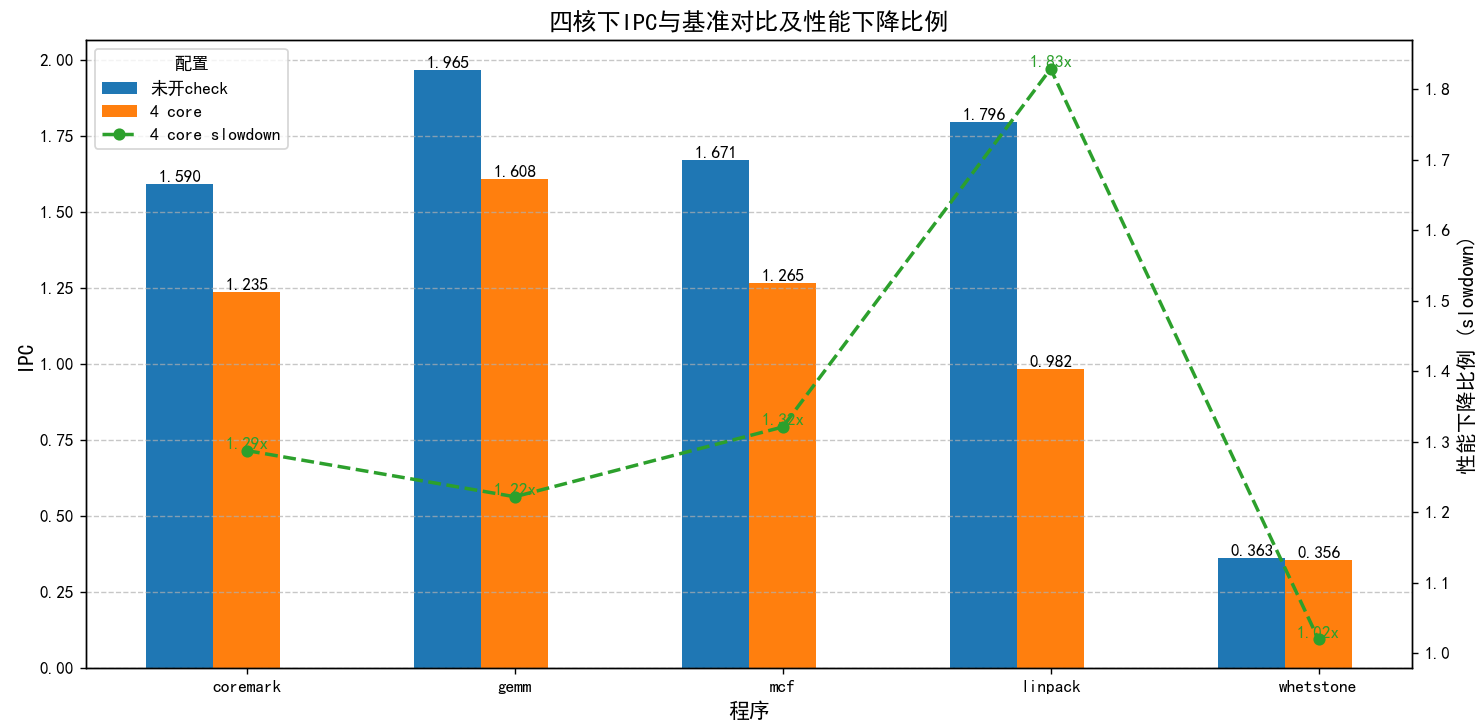
由于小核频率是大核一半,故小核在大核频率下的IPC约为0.37 ,
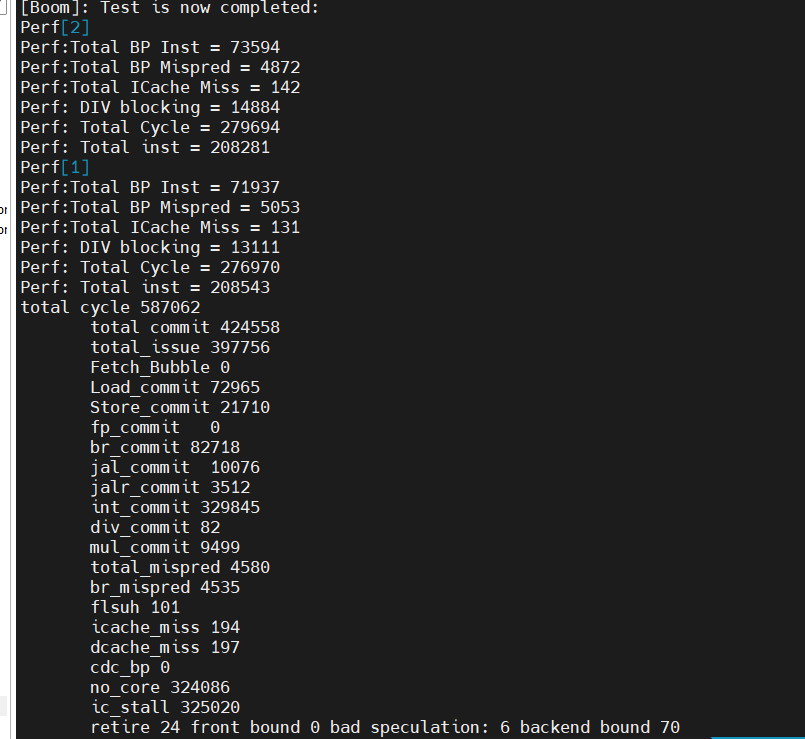
2 core
开启check:
6 core:
IPC
total cycle
cdc_bp
no_core_avaliable
ic_stall
未开check
1.59
265605
0
0
0
2 core
0.72
587062
0
324086/55.2%/99.7%
325020/55.3%
4 core
1.235
342020
0
72858/21.3%/97.8%
74475/21.7%
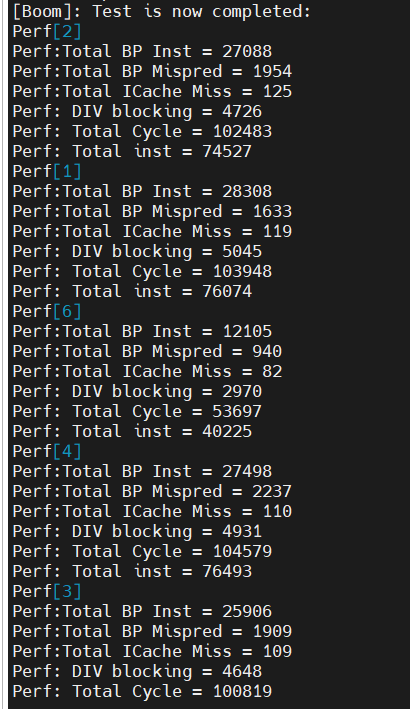
6 core
1.486
287138
0
16482/5.7%/93%
17717/6.2%
gemm
IPC
total cycle
cdc_bp
no_core_avaliable
ic_stall
未开check
1.965
182857
0
0
0
2 core
0.835
429344
0
230183/53.7%/100%
230434/53.7%
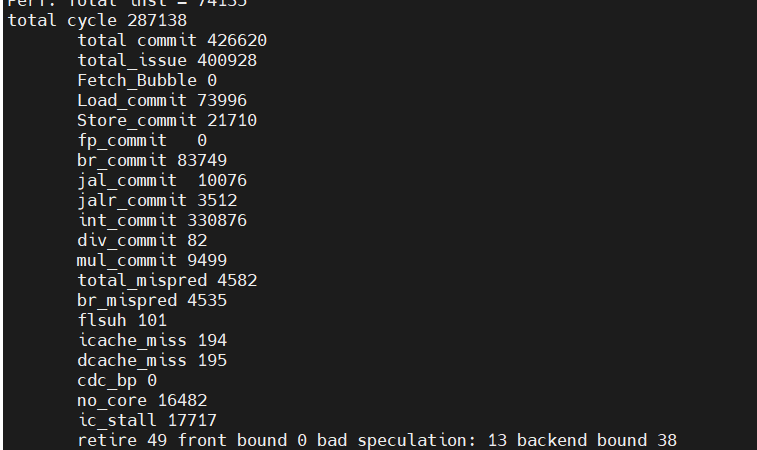
4 core
1.608
223510
0
72858/21.3%/97.8%
23046/10%
6 core
1.766
203488
0
913/4.5%/45.1%
2025/1%
core1
core2
core3
core4
avag
IPC
0.86
0.85
0.86
0.84
0.855
分支误预测
0.9%
1.1%
0.8%
1.1%
1%
ICache缺失率
0.04%
0.01%
0.05%
0.06%
0.04%
DIV Block
0.67%
0.83%
0.81%
0.82%
0.78%
mcf
IPC
total cycle
cdc_bp
no_core_avaliable
ic_stall
未开check
1.671
1906116
0
0
0
2 core
0.72
4869315
0
3015365/55.2%/99.7%
3021601/55.3%
4 core
1.265
2518167
0
72858/21.3%/97.8%
660083/21.7%
6 core
1.666
1912461
0
8211/0.4%/37.8%
21735/1.1%
core1
core2
core3
core4
avag
IPC
0.74
0.67
0.7
分支误预测
5.5%
6.7%
6%
ICache缺失率
0.02%
0.03%
0.02%
DIV Block
1.4%
1.2%
1.3%
linpack
IPC
total cycle
cdc_bp
no_core_avaliable
ic_stall
未开check
1.796
243676
0
0
0
2 core
0.508
868162
0
632489/72.9%/100%
633141/72.9%
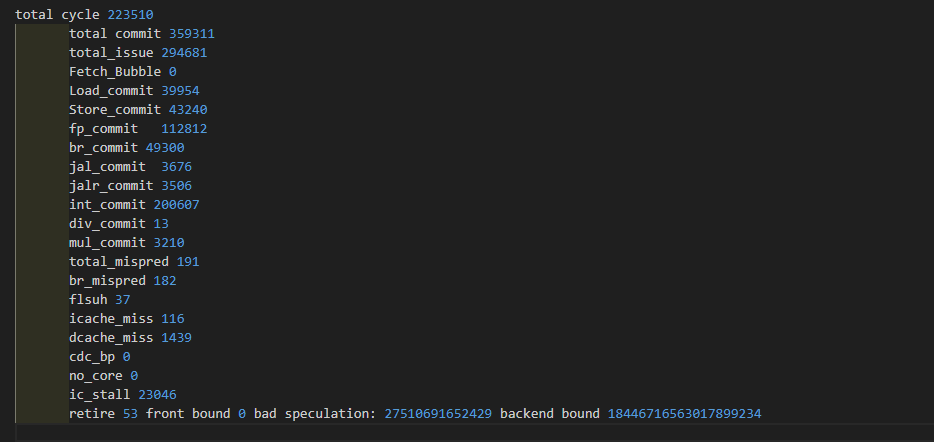
4 core
0.982
445532
0
214406/48.1%
6 core
1.387
315550
0
78638/24.9%/95.8%
82092/26.0%
core1
core2
core3
core4
avag
IPC
0.52
0.53
0.527
分支误预测
7.6%
7.7%
7.6%
ICache缺失率
0.03%
0.03%
0.03%
DIV Block
0.81%
0.66%
0.74%
whetstone
IPC
total cycle
cdc_bp
no_core_avaliable
ic_stall
未开check
0.363
180812
0
0
0
2 core
0.283
225835
0
48576/21.5%/100%
48624/21.5%
4 core
0.356
181373
0
1728/1%
6 core
0.359
180019
0
2/0%/1%
213/0.01%
core1
core2
core3
core4
avag
IPC
0.374
0.376
0.274
0.348
分支误预测
2.1%
3.2%
1.9%
2.5%
ICache缺失率
0.2%
0.03%
0.2%
0.03%
DIV Block
0%
0%
firesim代码调试
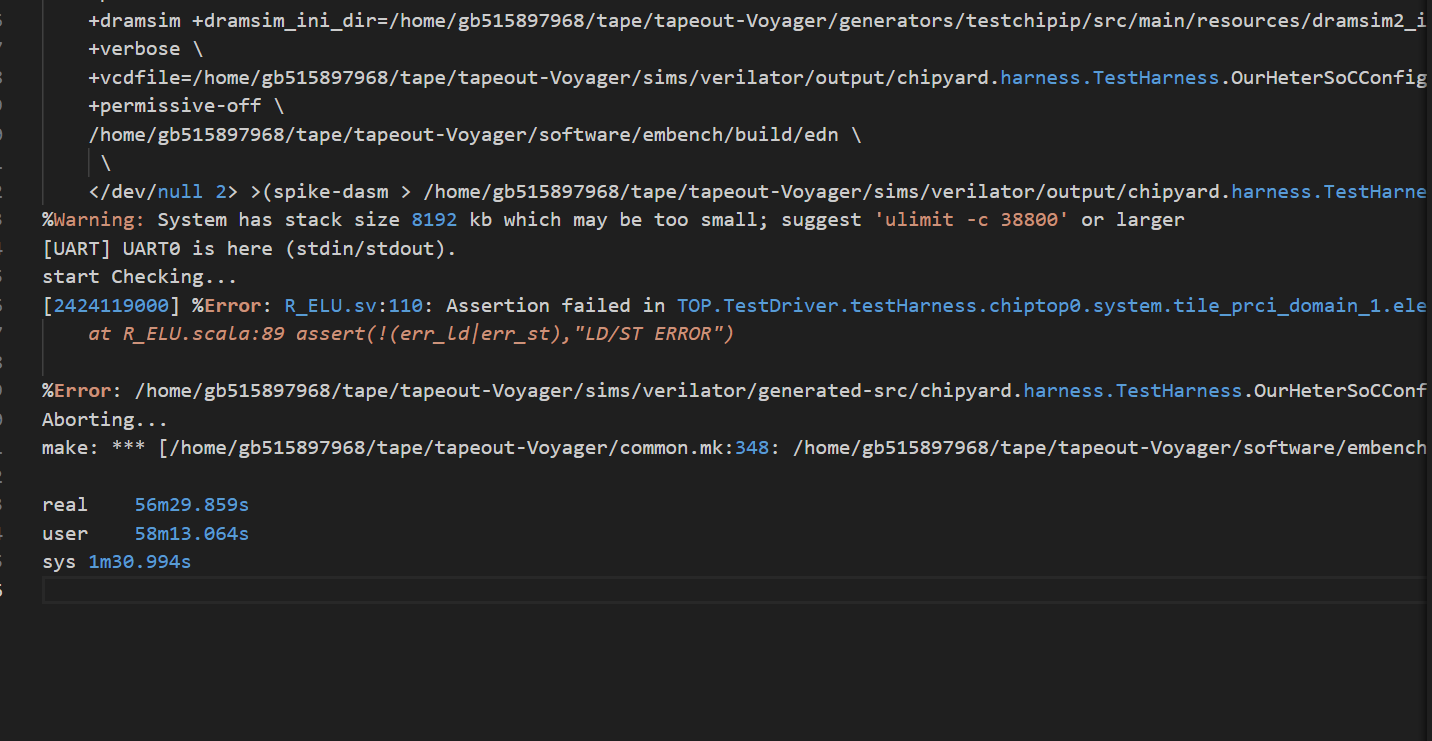
出错的地方小核执行的片段很少,应该是进入异常了,并且此时小核并未去写入2号寄存器,所以怀疑ECP转发有问题
根本问题:
在进入syscall时,需要退出检查模式,所以此时需要去给出相应的ecp
syscall只会持续12个周期左右,之后如果ECP没传过去,很有可能就是ECP出错(被异常程序复写)
这里发了两次ECP
这个trans阶段直接跳到fsm_presch暂时不清楚?
CYCLE: 2109544445 C1: 377667396 [1] pc=[00000000000a84c4] W[r 1=0000000000107990][1] R[r 2=0000003fd64c7a00] R[r 0=0000000000000000] inst=[000070a2] DASM(000070a2)
异常处理程序好像会写入寄存器,导致寄存器SCP发送出错?
应该是上下文恢复,但看了之前的a0寄存器值为1,但恢复上下文写入了31?
根本原因就是异常处理程序一开始也会去更新寄存器,之后才是进入保存上下文
比如他会先执行csrrw x4, sscratch, x4,导致x4被修改
所以修改状态机是最合理的方法,
一个做法:
感觉得去独立SCP和ECP,但可能面积剧增
或者就是进异常处理后直接停止stall,直到ECP发出去
GHE的PID——CFG是什么意思,U模式的satp不一定一成不变吧,如果页表修改了,那么会触发什么呢,如何处理跨页的?
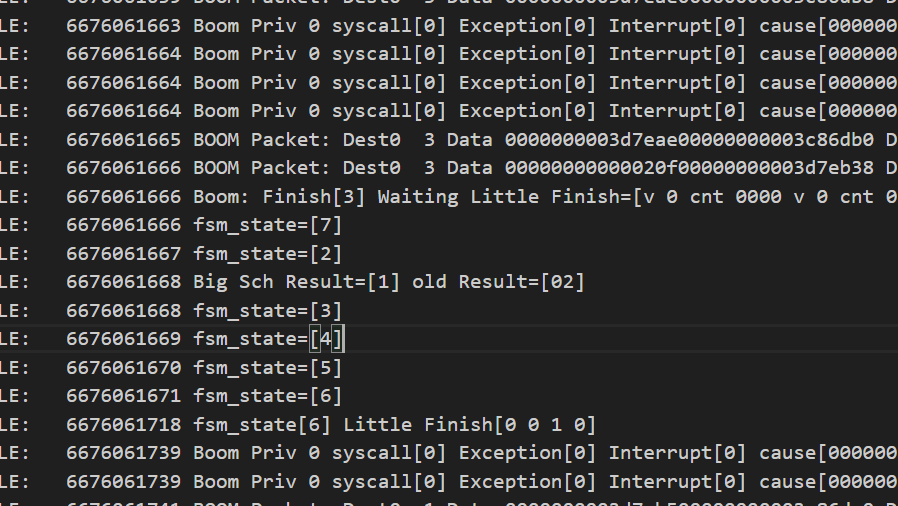
发现核1,2,4无响应,只有核3在
CYCLE: 1325299707 C1: 376960845 [1] pc=[00000000000139a4] W[r10=0000000000000000][1] R[r 0=0000000000000000] R[r 0=0000000000000000] inst=[c200452b] priv[0],没有正确进入检查模式
CYCLE: 1325294905 [C1] Paste PC [0000084aca]
CYCLE: 1325295441 [C1] ECP idx[1f] arfs 0000000000000003 farfs 0000000000000000
这个bug就是在处理异常中ECP发了过来,导致RCU status变为3,退不出循环
想到一个问题,小核心的信号会去修改大核
在ctrl c时,可能造成FPGA板子断开连接,具体原因是linux把PCI对应口给卸载了,可以让他重新扫描一遍
echo 1 | sudo tee /sys/bus/pci/rescan
无法跑多个workload
需要在退出时清空CDC,但reset信号或上自己的信号是否为一个正确的做法?
dcacheArbPorts具体含义?是否影响整体
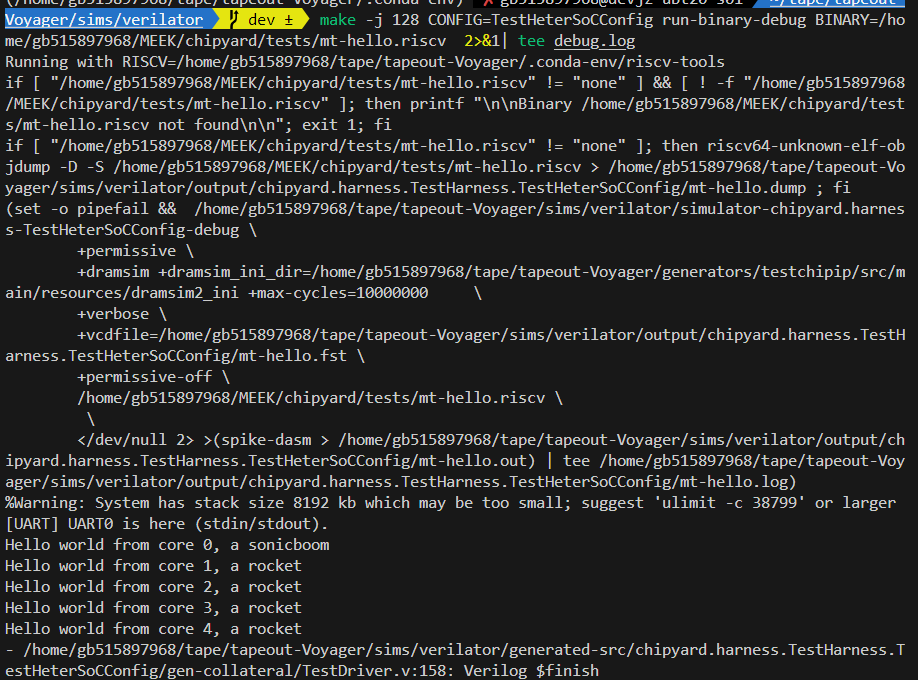
Chisel exception caught when instantiating ghm within DigitalTop at (generators/rocket-chip/src/main/scala/guardiancouncil/GHM.scala:393:28)
新版本的chipyard必须加入wrapper,要不会显示没有隐式时钟
diplomacy赋值node时,必须用val,使用var会导致node错误赋值,或者多次赋值
Could not find or load main class chipyard.Generator
将.classpath_cache文件夹删除
new chipyard.config.WithTileFrequency(500, Some(4)) ++
这个单纯只是把tile加入了id后缀,如果你的tile不是tile结尾,这里会出错的
这个和你的tile的 val baseName = “rockettile”
val uniqueName = s”${baseName}_$tileId”
有关,建议直接改为tile,这样就不用去修改WithTileFrequency函数
GHM会接入gemini的核心,导致小核的核心+1,从而需要修改GHM的配置
这个遇到bug,准备先停止,完成
global配置meek不太行,必须得上cde了,所有的node都得改
1.13.0必须挂代理才可以进去
新版本的不能和旧版本的使用同一个仿真文件夹,否则打不开blk——dev——log
目前感觉gcc的bug是因为没有正确给出ecp的target,
这里应该把ecp发到3,而不是2