spp
Path Confidence based Lookahead Prefetching
首先,SPP 使用基于压缩历史的方案,可以准确预测复杂的地址模式。 其次,与其他基于历史的算法不同,当地址模式在物理页面之间转换时,这些算法会错过许多预取机会,而 SPP 会跨物理页面边界跟踪复杂模式,并在它们移动到新页面时立即继续预取。最后,SPP 利用其对预测的信心,根据每个预取流自适应地限制自身。SPP 以最小的开销实现这一点,严格在物理地址空间内操作,并且不需要任何额外的处理器核心状态,例如 PC。
SPP贡献
- 我们引入了一种签名机制,以压缩形式存储内存访问模式并启动前瞻预取过程。此 12 位签名最多可压缩四个小增量,且不会产生混叠。通过将签名与未来可能的增量模式相关联,SPP 可以快速准确地学习简单和复杂的内存访问模式。签名还可用于检测两个物理页面之间的局部性,并从一个物理页面的末尾继续执行相同的预取模式,直到下一个物理页面。
- 我们开发了一种基于路径置信度的预取节流机制。随着lookahead预取的深入,一系列签名构建了一条签名路径。每条签名路径都有不同的置信度值,这取决于其之前的增量历史、预取准确性和预取深度。路径置信度值用于动态限制预取深度,以平衡预取覆盖率和准确性
- 与之前基于前瞻的预取器 [12]、[13] 不同,SPP 不需要深入到核心微架构中,而是纯粹基于物理内存访问流
MOTIVATION AND PRIOR WORK
对于之前的工作:
- 需要去处理复杂的访存模式
- 需要去自适应预取深度(lookahead深度)
- 需要考虑跨页预取
DESIGN
随着lookahead深度增加,预取置信度在下降,公式如下
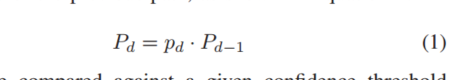
然后将Pd与置信度阈值对比,以确定何时停止预取,置信度Pd还可以选择插入哪个缓存,置信度高的插入高级别的
SPP在物理空间运行,不用访问tlb,spp使用一个页面的学习结果来预测其他页,通过两种模式:
首先,虽然增量历史签名是在每个物理页面的基础上维护的,如第 III-B 节所述,但这些签名索引到用于预测增量的全局表中,该表由所有页面共享。其次,如第 III-D 节所述,当第一次按需访问新的物理页面时,可以继承来自其增量预测跨越页面边界的先前物理页面的增量签名模式,并将其用于引导此新页面中的预测。这使 SPP 具有不需要长时间的每页预热期来开始预取复杂模式的优势,从而导致更高的预取覆盖率。
大致设计
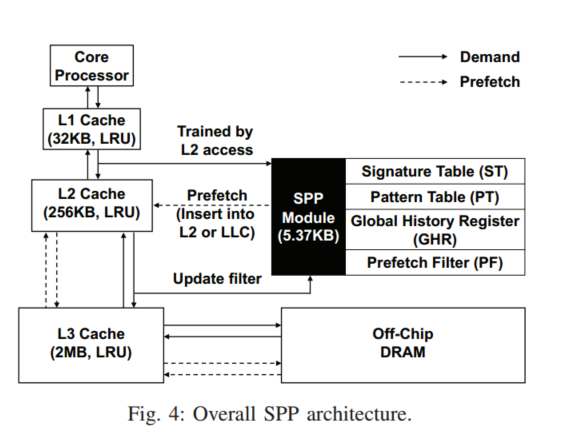
主要有三个结构:Signature Table, Pattern Table, and Prefetch Filter以及一个小的GHR(用于跨页预取)
SPP是用访问L2Cache的流来训练,可以将结果填充至L2或LLC,ST跟踪最近256个页面,每个页面的delta访问压缩为12bits的签名,然后这个可以去访问模式表(PT),存储预测的模式,PT还会去估计给定增量的置信度如果置信度高,就会作为预取候选传送给PF,PF检查是否存在冗余的预取,如果预测的增量跨4k边界,SPP不会发出预取,而是送入GHR学习
Learning Memory Access Patterns
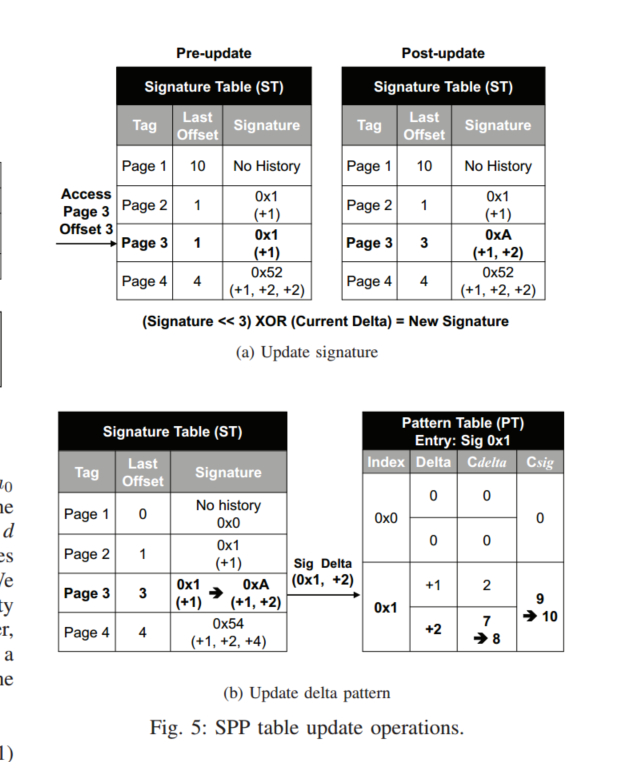
ST是在4K页面内捕获访问模式,并将先前的offset记录在表中,如上图A,物理页面3,offset为3的请求访问ST,ST会根据下面公式更新签名
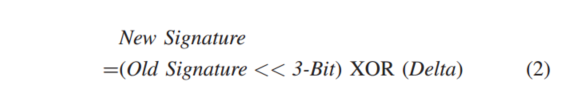
我们此时可以认为,给定的一组访问,比如0x1,他还会去访问增量为2的地址,如果PT不包含匹配的增量,他会在这个签名所属的一个地方去找一个Cdelta最低的值填入
我们会在PT中更新这种访问模式,更新策略就是,找到delta为2的,将置信度+1,为了去估计每个delta的预取准确率,还维护了sig计数器,他跟踪签名出现的次数,如果两个技术器其中一个饱和了,与该签名的所有计数器将会右移1,这样做不会去丢失之前的历史记录
PT的条目是全局共享的,也就是页面A,B共享相同的访问模式,他们会生成同样的签名,并且签名会索引到PT中相同的条目,更新PT访存模式
PT每个条目可容纳最多四个delta,如果其置信度Cd>=Cdelta/Csig,则这个条目就成为预取候选者
delta最大为7bit,假设 4KB 页面具有 64B 缓存行,所有可能的增量都在 (-63) 到 (+63) 的范围内。我们对正增量和负增量都使用 7 位符号+幅度表示。因此,负增量和正增量会产生不同的签名,指向模式表中的不同条目,并最终指向不同的预取目标。但注意大于7的delta会发生混叠
Path Confidence-based Prefetching
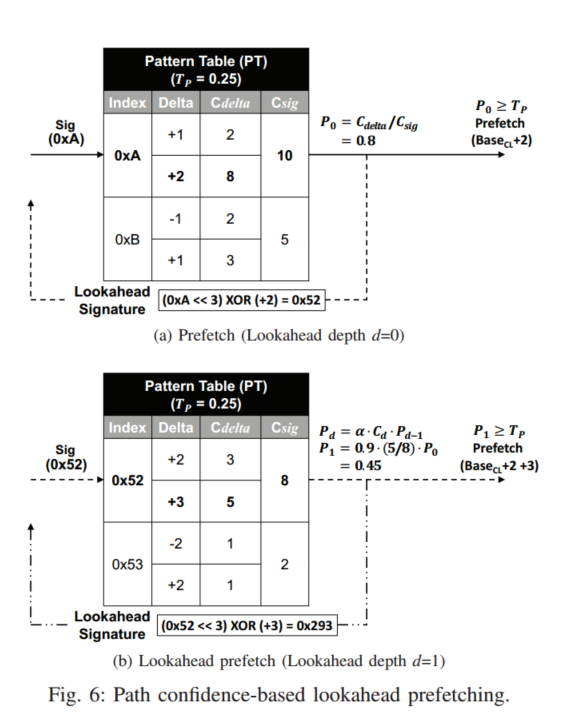
路径置信度是根据0XA的签名相关的增量计算的,初次访问置信度为Cdelta/Csig,所以+2的增量会被送入预取
此外PT还会构建新的签名以供下次预取使用,虽然可能会有多个候选,但只选择置信度最高的生成签名,新的lookahead签名用于再次访问PT,直至Pd小于Tp,更大的置信度Tf决定了给定的预取应该送入哪个缓存
SPP可以引入a来降低lookahead的概率
请注意,为简单起见,在上面的讨论中,我们在浮点数的背景下描述了路径置信度计算。然而,在实际实现中(以及在我们的模拟器中),我们使用 7 位定点数来表示 0∼100 之间的路径置信度值,并对这些定点数执行乘法和除法。此外,由于 Cdelta 和 Csig 是 4 位饱和计数器,我们可以使用一个简单的 16x16=256 条目查找表来存储所有可能的除法结果,这使我们能够完全删除昂贵的除法器模块。此外,额外的计算延迟可以被隐藏,因为 SPP 可以在 L2 缓存等待 DRAM 服务需求未命中时在后台计算路径置信度
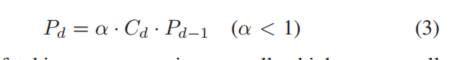
如果预取器观察到以下条件之一,SPP 会停止预取:1) 路径置信度 Pd 较低。 2) L2 读取队列资源太少。
Page Boundary Learning
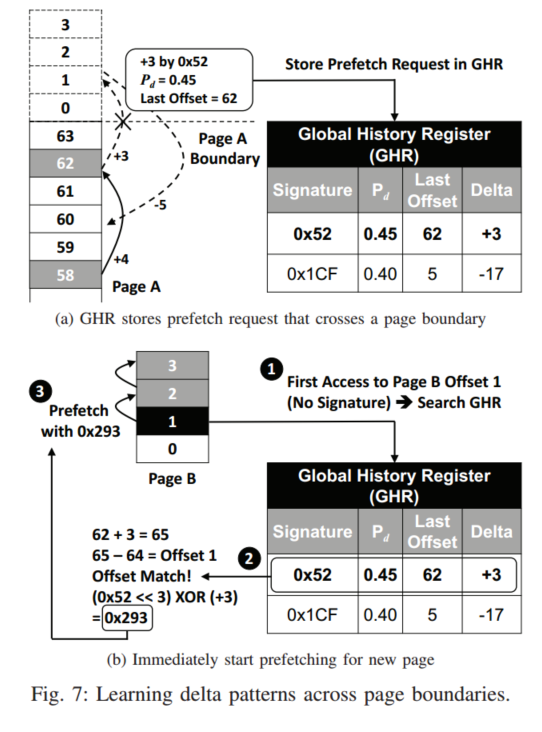
边界预测被存放到一个8entry的条目中,这个GHR存储当前的签名,路径置信度,以及偏移和delta,页面A发生跨页预取,那么会在新页面B访问GHR,匹配offset相等的,
也即是发生跨页时:
- 写入跨页请求,然后这个请求其实是B的offset为1的访问,此时访问GHR,发现匹配值,然后生成页面B的签名
Prefetch Filter
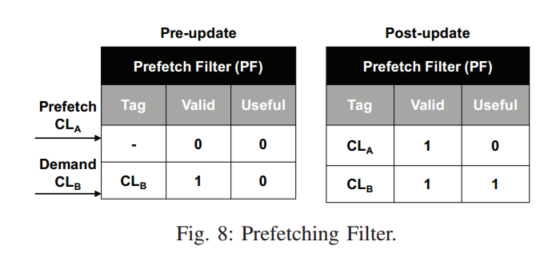
SPP总是先检查PF,然后再发出预取,如果PF已经包含一个缓存行,说明这个缓存行已经被预取,预取请求会被丢弃,当缓存行被替换,会重置有效位来清除条目
通过在每个过滤器条目中添加一个有用位,PF 还可以近似预取精度。SPP 有两个全局计数器,一个用于跟踪预取请求的总数 (Ctotal),另一个用于跟踪有用预取的数量 (Cuseful)。每当 SPP 发出未被过滤器丢弃的预取时,Ctotal 计数器就会增加。有用的预取由 PF 中命中的实际 L2 缓存需求请求检测到,这会增加 Cuseful 计数器。为了避免每个有用的预取行增加 Cuseful 超过一次,我们在 PF 条目中设置了一个已用位,以防止重复计算。此过滤器跟踪的全局预取精度用于公式 3 中的 α,以限制路径置信度值。
