MLOP
Multi-Lookahead Offset Prefetching
摘要
讲的就是MLOP集timelineness和coverage于一体,并且可以弥补BOP只能预测一个offset,MLOP使用一个轻量级的硬件结构,由一个小存储器和一个简单的逻辑组成,用于识别在不同预测前瞻下可以覆盖特定缓存未命中的预取偏移量。基于此,MLOP为预取偏移量分配分数,并为每个前瞻选择分数最高的偏移量来发出预取请求。我们评估并比较了MLOP与各种最近的先进数据预取器,并表明我们的提议比没有数据预取器的系统提高了30%的系统性能,比之前性能最好的数据预取器提高了4%。
提议
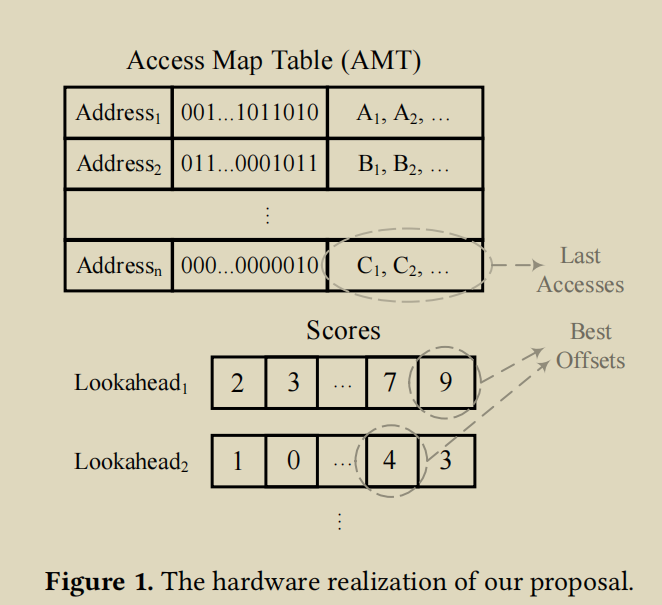
偏移量在前瞻级别X的分数表示预取器能够预取访问的次数,至少在发生前X次访问,例如,偏移量在前瞻级别1的分数表示预取器能够预取任何未来访问的次数
AMT中存放的是一个一个region的memory访问情况 每个region对应一个entry, entry中存储一个bit vector, 表示每一个位置是否被访问过了。 此外,每个region还会有一个history queue。以queue的形式存最近k个访问的offset,然后每个位向量都有level个级别的历史访问顺序。
因为MLOP有多个lookahead level, 每个level有自己的最佳offset。因此,MLOP开了level个score table, 记录当前level每个offset的得分
为了在前瞻级别1更新偏移量分数,每当发生访问时,我们找到其对应的位向量(使用其高位来搜索AMT),然后根据位向量信息,识别可以预取该访问的偏移量,并相应地增加这些偏移量在第一前瞻级别的分数。最后,我们在AMT中设置当前访问块对应的位。更新高位的分数需要先屏蔽低位的访问
说实话他这个论文比较空,建议读ppt