runahead
runahead
(又是Onur Mutlu写的文章)
要解决的问题(摘要)
现如今高性能处理器都通过OoO来中和一些高延迟操作(如cache miss,中断异常,设备访问),之前做法都是增大指令窗口(个人理解为rob中可存储指令个数),现在可以提前执行,也即是runahead,在相同的机器上,runahead结合128个Instruction Windows与在没有提前执行和384个Instruction Windows相比性能几乎没有差异
相关工作
mem access对CPU的性能影响很大,故之前有人提出了cache,no-blocking cache,硬件预取,软件预取,基于线程预取
Balasubramonian提出了长延迟指令阻塞退役时执行未来指令的机制。它们的机制动态地将寄存器文件的一部分分配给“未来线程”,该线程在“主线程”停止时启动。这种机制需要对两种不同上下文的部分硬件支持。
缺点:两模式都无法全部享用处理器资源
在运行提前执行中,普通模式和运行提前模式都可以利用机器的全部资源,这有助于机器在运行提前模式中获得进一步的领先。
Lebeck提出,将依赖于长延迟操作的指令从(相对较小的)调度窗口中移除,放入(相对较大的)等待指令缓冲区(WIB)中,直到操作完成,然后将指令移回调度窗口。这结合了大指令窗口的延迟容忍优势和小调度窗口的快速周期时间优势。(类似于超标量发射队列的推测唤醒那一节)
IW和SW(和超标量哪一本的含义不同)
An out-of-order execution machine
accomplishes this using two windows: the instruction window and the scheduling window.
指令窗口是已经解码的指令但还没退休,也即是在rob的指令,调度窗口是指令窗口的一个子集,其主要作用就是找到可以执行的指令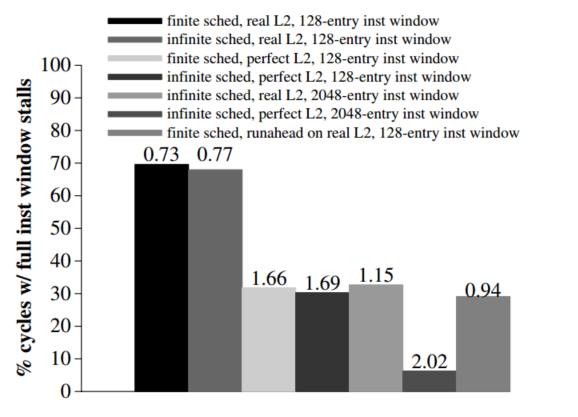
可以看到runahead+128表项的IW的停顿百分比与IPC(每个条顶部为IPC),其消除full window
stalls获得了20%的IPC提升
runahead
CPU任何时候都可以进入runahead,本论文在l2cache miss,并且该内存操作到达指令窗口的头部时(也就是最老的指令)进入提前执行.提前执行时的pc得存起来,以便退出runahead恢复archstate,IW中所有指令都被标记为runahead inst,在这个模式中取到的指令也是No updates to the checkpointed register file are allowed during runahead mode.runahead的执行与内存通信和无效结果的传播有关,一些规则:
- Invalid bits and instructions.
- Propagation of INV values.
进入runahead的第一条无效指令为load或者store(引起这个问题的原因),若为load,则rf的INV拉高,若为store,则runahead cache分配一个表项,并且将dest 的byte置为无效Any invalid instruction that writes to a register marks that
register as INV after it is scheduled or executed. Any valid
operation that writes to a register resets the INV bit ofits
destination register. - Runahead store operations and runahead cache.之前的工作runahead load之前有runahead store(raw)被视为无效指令并被删除我们认为转发是必要的,如果两个指令都在IW中,直接通过store buffer获取指令,如果指令伪退休了,
我们将其存入runahead cache,其目的是转发数据和状态,被替换的dirty行不会存入下一级存储器,而是会直接删除(正常模式的指令无法访问该cache)store buffer 和runahead cache的每个字节都有对应的INV,而runahead cache 中还有STO为,指示store是否写入该字节,只有访问该cache中的STO和valid 之高的line,才不会miss,规则如下:- 当有效runahead store执行->拉低cache的INV,若datacache中该数据缺失,则进行预取
- 当无效runahead store被选中->将store buffer对应位置拉高INV
- 当有效runahead store退休,写入cache,重置INV,设置写入字节的STO
- 当无效的runahead store执行,cache的INV升高,设置STO
- runahead store不会将数据写入data cache
但store地址无效时,其操作将会被视为NOP,这时与之相关的load可能无法获得正确的值,可以使用memory dependence predictors解决
- Runahead load operations.Runahead load操作可能因三种不同原因而无效它可能源于一个 INV 物理寄存器。(寄存器的INV位)它可能依赖于store buffer中标记为 INV 的存储。(store buffer的INV位)它可能依赖于一个已经伪退休的 INV 存储器。(runahead cache的INV位)Runahead load 执行时会并行访问data cache,store buffer和runahead cache访问store buffer和runahead cache:只有访问的line的INV置低,(STO置为高),才能获取数据,若无效,则该指令的dst reg 置为INV如果store buffer和runahead cache 都miss,但data cache hit,使用该数据,但实际这时数据可能是无效的->依赖于之前的store,但之前的store 的line是INV的或者被驱逐出cache(这种很罕见,故不会影响性能),如果三个都miss,则访问l2cache,如果访问l2cache miss,则驱除该指令,然后当作正常模式的指令运行,(个人理解这个可能会形成嵌套runahead)
- Execution and prediction of branches.在runahead模式的分支指令预测失败后不会恢复****训练策略runahead 时就训练BHT,这样其训练效果好不能再runahead训练BHT,这样可能导致分支预测不太行,导致runahead遇见分支性能下降只能在runahead训练BHT,正常模式通过fifo访问BHT两种模式有不同的表
- Instruction pseudo-retirement during runahead mode.
runahead模式退休和正常差不多,区别在于:runahead如果检测ROB有inv指令,直接退休,两种模式均会更新RAT
Exiting runahead mode
退出也是可以随时退出,本文使用和分支预测失误后恢复的方法相似
本文使用的是当blocking的数据返回后退出runahead,
一些名词
BHT,FIFO,ROB,RAT,store buffer