gem5
- event programming
- new config
- debug flags
- out of order
在GEM5退出时,Dump cache中所有的line的地址和内容, 参考Event-driven programming, 但是退出的event callback和这里展示的例子不完全一样,需要自己去阅读相关代码。
首先我使用的CPU类型为TimeSimpleCPU,直接找他与Cache如何交互,也即是下图
然后找到了tags,这里可以打印所有的blk
在cache/tags/base.cc,可以打印所有的blk
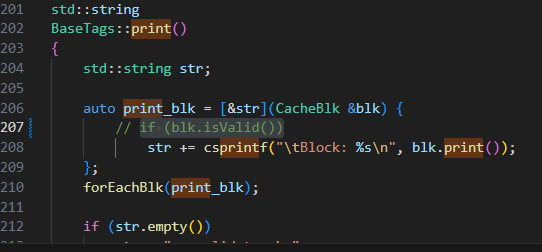
registerExitCallback注意这个函数
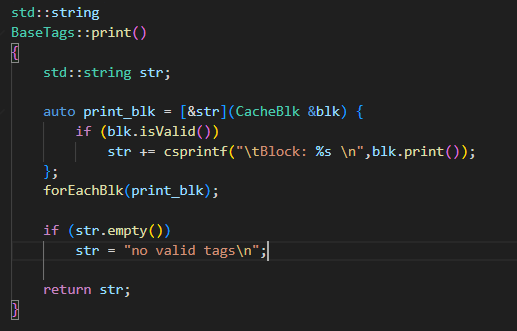
这个是tag/base.cc
这个如何实现遍历:
1 | void forEachBlk(std::function<void(CacheBlk &)> visitor) override { |
首先将输入参数变为函数,接受一个blk参数,然后这个blks是blk的集合,存了所有blk,然后进行遍历
这个是base_set_assoc.h
所以可以在结束时调用这个函数,这样就可打印全部内容
1 | BaseTags::BaseTags(const Params &p) |
具体就是在这个函数内会注册退出时的回调函数,只需要将里面函数换为print就行
NUMA
非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
SMT
1、SMT为什么能提升并行性能(多线程性能)?
SMT技术虽然是提升多线程下表现的性能,但SMT实际上是提升CPU单核性能大背景下的“副产品”。 一个单核单线程任务,在CPU的视角上,可以被看作是执行一连串连续的指令。比如说是下面这个例子里,假设执行的就是一个包含10个指令的任务:
1 | 任务1 = A1 A2 B1 C1 D1 A3 A4 D2 C2 B2 |
我们先看最简单的场景,CPU执行这些任务最直接的办法就是一个指令一个指令的执行,假设这些指令的执行周期都是N,那么执行完这些指令,就需要10N个周期。那么CPU的速度就只和CPU的频率相关了,显然这也不符合我们的认知,不同CPU在相同频率下的性能显然不一样。
除了频率以外,要提升CPU的单核性能,第一个常见手段就是尽可能的缩短每个指令执行的周期,不过在我们假设的这个场景中和SMT关系不大,这里就不说了。第二个常见手段就是指令级并行(ILP)。虽然说这个任务1理论上是得一个指令接着一个指令的执行,但实际上这些指令并一定只能这么顺序执行,只要两个指令之间没有相互依赖和冲突,那么就可以并发执行(一起执行),从而缩短总的执行时间。 例如在上面这个例子中,我将指令分组成A B C D四组,组内必须顺序执行,组间的指令完全没有依赖(彼此不依赖对方执行后的数据)和冲突(不共享资源,不是一类操作),那么我们就可以并发执行这些指令。
1 | 任务1A:A1 A2 A3 A4 |
那么我们还是假设每个任务的执行周期是N,可以看到只要我们按照上述分组执行代码,那么整体的执行时间就只取决于最长的一组任务1A,也就是执行时间可以缩短到4N,速度提升到2.5倍。
显然,如果说要在一个CPU核心里同时执行上述几组任务,那么CPU自然得具备至少4组执行端口,这里我们也简化成PA、PB、PC和PD,分别执行上述的1A 1B 1C 1D。所以现代的CPU要提升单核性能,都会尽可能的把后端的执行端口数目变多,并且尽可能的在单位时间内读入更多指令,从而促进指令间的并发。
但是,实际的任务里,指令之间的依赖冲突关系是错综复杂的,不可能完美的将指令均匀的分组到每一个端口上。 就比如说我们上面这个例子里,在并发执行后虽然时间缩短为了4N个周期,但是实际上只有端口PA是一直在工作的,而PB PC PD都会在中途闲下来。
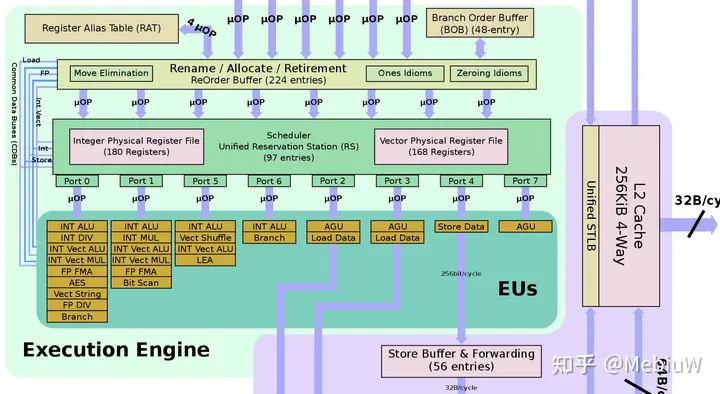
以Skylake为例子,后端执行端口EU不只一个
随着单核性能的不断提升,后端执行资源也越来越丰富,这种执行端口闲置的情况就会越来越明显,造成资源浪费。这时候,为了将这些资源物尽其用,同步多线程SMT就应运而生了。SMT的思路是这样的,既然一个任务填不满后端的资源,那么我们就找不只一个任务来填就好了,不同任务之间的相互依赖和冲突情况很低,放到一起来执行正合适去填满后端资源。
我们接着举例子,假设现在有一个新的任务2,同样是10个指令,同样按照端口分组:
1 | 任务2 = B‘1 A’1 B‘2 C’1 C‘2 D'1 D’2 D‘3 C’3 A‘2 |
那么在指令级并发的情况下,这个任务的执行时间就是3N。
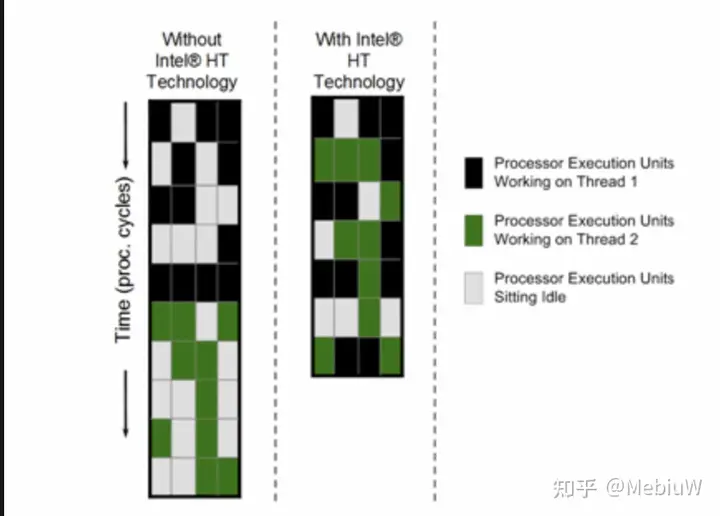
那么如果把任务1和任务2在单核CPU上分别执行,它们的执行时间就是4N+3N=7N。这时,如果我们引入SMT技术,虚拟出两个核心来,让他们同样在一个核心内执行,依然使用ABCD来表示互相不冲突的指令:
1 | PA:A1 A2 A3 A4 A’1 A’2 |
那么这时候整个执行时间就变成了6N,比起之前的7N又提升16.7%的速度。
前端有两组维护不同任务上下文的单元就可以
启动流程
gem5 是一个事件驱动(Event-driven)的模拟器。在事件驱动模型中,每个事件(Event)都有一个回调函数用于处理事件。
Gem5 是一个事件驱动的模拟器。因此,事件(Event)是模拟器的基本调度、执行单位,是一个非常重要的核心概念。事件可以理解为一系列改变系统状态的行为,包括但不限于对内存的读写、数据包的发送和到达等。模拟器整个的模拟过程就是对所有事件创建、调度、执行和终止的过程。从技术上讲,事件是由特殊的回调函数和一组状态信息位域实现的。对该事件的执行本质就是执行事件内的回调函数。
每个事件都会包含一个EventFunctionWrapper 用来注册回调函数, 每次执行回调函数都会去执行schedule,用来调度事件
实际上CPU开始仿真时,先通过python设置参数,然后启动simluate,该函数会去进入doSimLoop,然后一个一个事件的执行,实际上目前看到就一个事件:CPU的process,他会去调用回调函数tick,而CPU的回调函数会去调用每个阶段的tick函数,从而推动事件进行
所有的event都是继承于eventbase,其静态变量遵循事件调度的优先级:
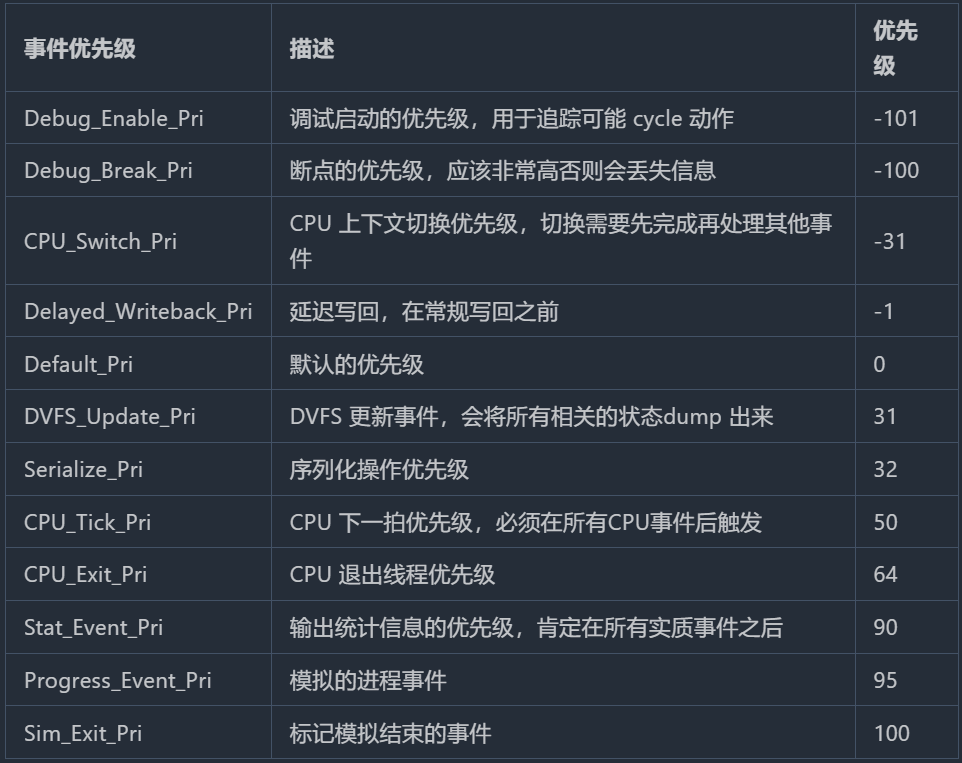
其还定义了很多flag来揭示权限和状态
Event
事件类 Event 是 Gem5 中的核心类,是所有事件的父类。该类继承自 Serializable 类(这今后再详聊)和 EventBase 类。此外,Event 类为抽象类,内含有一个纯虚函数 process(),通常程序员需要通过 Event 的派生类来创建事件对象。但在此之前,我们必须深入了解该类的运行机制。下面列出 Event 类中一些重要的成员。
1 | class Event : public EventBase, public Serializable { |
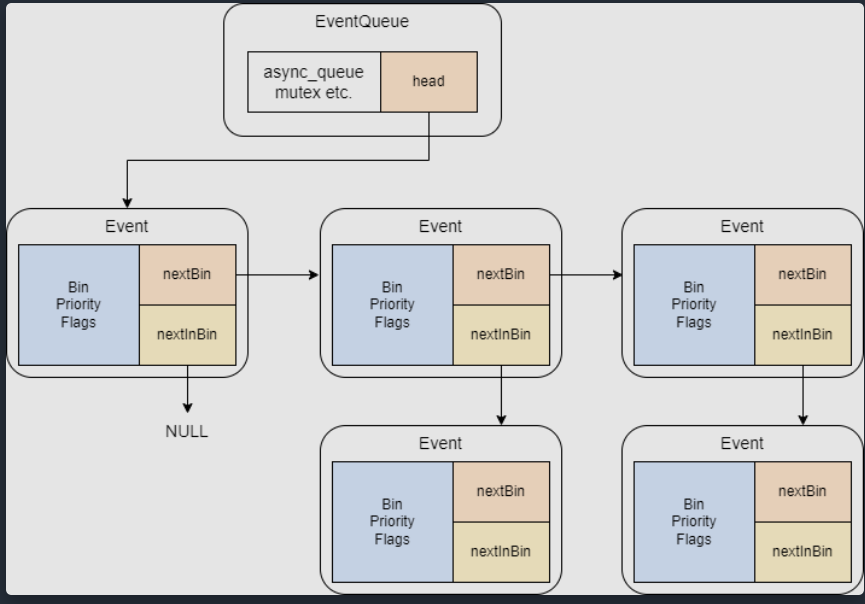
抽象类 Event 描述了事件这一核心概念,因而它也是整个底层机制的核心实现类。上节提到事件本质是由特殊的回调函数和一组状态标志位组成的,这体现在实现中便是类 Event 内部预留的虚函数 process(),以及存有运行时刻 _when,优先级 _priority,标记位 flags 和用于维护二维链表的两个指针变量 nextBin 和 nextInBin 等,其中 nextBin 指向链表中下一项,而 nextInBin 指向 Bin 相同的下一项事件。
为降低用户使用难度,使用 EventManager 类来包装 EventQueue 类,包括常用的许多事件调度函数,而这些包装函数是 SimObject 类内经常调用的:
fetch
o3 cpu的所有阶段都在cpu.cc现在讲解fetch阶段
fetch首先初始化构造函数,初始化的参数容易理解,故不作讲解
注意这里会初始化线程,和smt有关
初始化阶段会去设置decoder(架构相关)
注意目前o3不支持fs的smt模式
CPU初始化阶段会去设置每个阶段,且设置每个阶段的queue的指针,这些函数只在初始化阶段使用
fetch阶段通过processCacheCompletion函数解释是否取指令成功,该过程会把取到的指令写入fetchbuffer,并且设置相应的valid为true(也会去设置fetch状态为IcacheAccessComplete),之后会发出probe1请求
1 | memcpy(fetchBuffer[tid], pkt->getConstPtr<uint8_t>(), fetchBufferSize); |
注意,gem5将tick函数置为每个阶段event的回调函数
fetch阶段会去解码,而decode阶段算是一个伪阶段,具体的:
当执行fetch的tick函数时,会去执行fetch函数,该函数会取出指令,然后去解码,首先会去判断是否这个是一个完整的指令包(比如rv的c扩展,可能有些指令被截断),然后去在指令buffer再取出一些,凑成一条指令,注意,这段代码前面有判断是否fetchBuffer有数据,否则去icache取
1 | memcpy(dec_ptr->moreBytesPtr(), |
之后进入一个do while循环,这个循环会去解码指令
下面给出对整个 fetch() 函数的详细解释,该函数实现了 O3 处理器中取指阶段的主要操作,其核心逻辑如下:
获取当前取指线程
- 调用 getFetchingThread() 获取一个能够取指的线程 ID(tid)。如果返回值为 InvalidThreadID,则说明当前没有可用线程,此时直接更新 threadFetched 并可能记录停顿统计后返回,结束本次取指。
准备和状态检查
- 取得当前线程的 PC(程序计数器)状态(this_pc)以及对应的 pcOffset(即当前在缓存行内的偏移)。
- 根据当前 PC 与偏移,计算出实际取指地址 fetchAddr,并用掩码对齐(pc_mask)确保地址合法。
- 使用 isRomMicroPC() 判断当前是否处于微操作 ROM 内(用于处理那些内建的微操作)。
处理缓存访问和中断请求
- 如果上一次因 icache 访问延迟而导致 fetchStatus 处于 IcacheAccessComplete 状态,那么将其恢复为 Running,并通知状态发生变化。
- 如果当前状态为 Running,则检查取指数据是否已经在 fetchBuffer 中。如果缓存数据无效或当前 fetchAddr 跨入了另一个缓存块(fetchBufferBlockPC 与原来的 fetchBufferPC 不一致),则发起新的 icache 访问请求(调用 fetchCacheLine)并返回,等待数据返回。
- 同时,还检查是否有中断等待,如果中断已挂起而当前指令又不允许延迟提交,则也会阻塞本次取指。
进入取指循环前的准备
- 增加 fetch 阶段的周期计数(fetchStats.cycles++)。
- 复制当前 PC 状态生成一个 next_pc,用于记录下一条指令的 PC。
- 定义用于存放解码得到的静态指令(StaticInstPtr staticInst)和当前正在处理的宏操作(curMacroop),前者将用于构造动态指令。
循环取指与译码
进入一个外部 while 循环,条件为:已经取指的指令数未达到 fetchWidth、取指队列未满,并且未遇到预测跳转或 quiesce 指令。5.1 从存储器中补充更多字节(needMem 部分)
- 根据状态判断是否需要向解码器补充更多字节:如果不在 ROM 内、没有正在处理的宏操作,并且解码器还没有足够字节(!dec_ptr->instReady()),则设置 needMem 为 true。
- 刷新 fetchAddr 和计算所在缓存块(fetchBufferBlockPC)。
- 如果缓存数据失效或 fetchAddr 已经超出当前缓存块(比较 fetchBufferBlockPC 与 fetchBufferPC),则退出循环,从 icache 再度获取数据。
- 如果当前缓存块中剩余字节不足(blkOffset >= numInsts),同样退出该循环。
- 否则,用 memcpy 将取指缓存(比如数组 c[tid],实际可能为 fetchBuffer[tid])中对应位置的一个指令字节复制到解码器的缓冲区(通过 dec_ptr->moreBytesPtr() 得到地址),之后调用 decoder->moreBytes(this_pc, fetchAddr) 告知新字节已加入到解码器内部。
- 如果解码器仍觉得不足,则将 blkOffset、fetchAddr 和 pcOffset 依次增加一条指令的大小(instSize),为下一次读取做准备。
5.2 在解码器中提取指令(do … while 循环)
- 进入 do while 循环,该循环不断从解码器缓冲区或当前宏操作中提取指令,直到满足下列条件之一:
• 已取指数达到 fetchWidth;
• 取指队列达到其上限;
• 碰到预测分支;
• 或当前没有足够数据继续解码。
- 在循环中,如果当前不处于宏操作(curMacroop)且不在 ROM 内,则检查解码器是否已有足够字节(instReady())。
- 如果准备就绪,调用 dec_ptr->decode(this_pc) 得到一条静态指令(staticInst),同时增加取指统计。
- 若解码出来的是宏操作(staticInst->isMacroop()),则将 curMacroop 设置为该宏操作;否则重置 pcOffset 为 0。
- 如果正处于宏操作或在 ROM 内,则从当前宏操作中调用 fetchMicroop() 或从解码器中调用 fetchRomMicroop(),以获得其中的一个微操作。
- 接着调用 buildInst() 生成动态指令(DynInstPtr instruction):该函数为取出的静态指令与当前宏操作状态、当前 PC 及下一 PC 生成一个完整的动态指令对象,同时将该指令加入到取指队列中。
- 通知相应的 probe(ppFetch),并更新统计信息(numInst++)。
- 调用 lookupAndUpdateNextPC() 对分支进行预测,更新下一条指令的 PC,并设置 predictedBranch 标志(如果预测分支被认为已取走,则退出本次循环)。
- 更新当前 PC 状态(set(next_pc, this_pc))和 inRom 状态,判断是否进入新宏操作(如果新指令的 PC 与上一条不一致或者遇到了宏操作结束标志,则清除 curMacroop 并重置偏移)。
- 如果遇到 quiesce 指令,则设置 fetchStatus 为 QuiescePending 并退出循环。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18if (!(curMacroop || inRom)) {
if (dec_ptr->instReady()) {
staticInst = dec_ptr->decode(this_pc);
// Increment stat of fetched instructions.
cpu->fetchStats[tid]->numInsts++;
if (staticInst->isMacroop()) {
curMacroop = staticInst;
} else {
pcOffset = 0;
}
} else {
// We need more bytes for this instruction so blkOffset and
// pcOffset will be updated
break;
}
}循环退出后的状态更新
- 循环结束后,更新当前线程的 macroop(保存可能未取完的宏操作)和 fetchOffset(留待下次取指时继续使用)。
- 如果本次 fetch 循环内至少提取了一条指令(numInst > 0),则标记 wroteToTimeBuffer 为 true,后续将把这些指令写入时间缓冲区传递到 decode 阶段。
- 此外,还会设置 flag issuePipelinedIfetch:如果取指地址已经跨过当前缓存边界,并且没有遇到延迟响应等状态,则触发新的流水线化 I-cache 请求。
总结
整个 fetch() 函数完成了以下任务:- 选择一个可用的线程以提取指令。
- 判断当前是否需要从 I-cache 中获取新数据或者从已有的 fetch buffer 中补充数据到解码器。
- 利用解码器逐条解码并构造动态指令,同时处理可能的宏操作拆分、分支预测以及异常指令(如 quiesce)。
- 将生成的动态指令放入取指队列,供后续 decode 阶段处理;同时更新各项统计并维护取指状态(例如 fetchStatus、fetchOffset 和 macroop 状态)。
整个函数是 O3 处理器中非常关键的一环,它负责从内存层缓存、解码器和微操作 ROM 中连续地提取、解码以及封装指令,为后续流水线各阶段提供指令流,并处理系统中因分支、异常或缺失数据而产生的各种边界情况。
在打印pc时可以使用inst.pcState():注意需要dync ptr类型,不过还是建议使用dump(),可以直接打印出反汇编
rename
rename阶段主要就是去对源寄存器和目的寄存器去重命名,然后查询scoreboard,送入发射队列(此时也会去分配ROB或者SQ LQ表项),这里源寄存器会去查rat,然后记录到inst
1 | renamed_reg = map->lookup(flat_reg); |
目的寄存器会去分配一个新的,然后将新旧的全部记录到inst
1 | rename_result = map->rename(flat_dest_regid); |
IEW
此阶段 (IEW) 负责将指令分派到指令队列、通知指令队列发出指令以及执行和写回指令。
后端计算执行函数链
1 | Rename::tick()->Rename::RenameInsts() |
后端load执行函数链
1 | IEW::tick()->IEW::executeInsts() |
后端store执行函数链
1 | IEW::tick()->IEW::executeInsts() |
首先讲dispatchInsts
该函数会将对应的指令送入IQ,注意,ld st指令会额外送入LSQ,然后将insts_to_dispatch数据取出
gem5使用集中式的发射队列
1 | if (add_to_iq) { |
dispatch阶段较为简单,接下来看计算指令的执行
计算指令执行
其调用executeInsts函数
,该函数首先在inst q去取出指令,然后判断该指令是否是isSquashed,这里可以理解为无效指令(因为异常等情况)。如果是,就会把该指令设置为可提交,
之后会进入inst->execute();函数,该函数架构相关,主要为每个指令生成了单独的执行函数,riscv好像是这样,然后setRegOperand函数会把计算结果写入instResult队列,
源寄存器的数从哪个函数读出?
执行阶段获取(getRegOperand函数)
什么时候写入目的寄存器?
执行完就写回了,写回阶段只是去唤醒其他指令(setRegOperand函数)
写回阶段干了什么?
首先搜索依赖链,然后根据该指令去让依赖链的指令ready,指令一般最多有三个寄存器(RISCV),markSrcRegReady里面就是将准备好的寄存器++,等到准备好的寄存器等于源寄存器总数,addIfReady函数检查是否指令准备发射(存入一个专门放准备好的指令的队列,该函数会对指令进行排序,然后更新最老指令的编号,listOrder存储最老的指令),然后设置scoreboard,将依赖指令从依赖链取出
1 | DynInstPtr dep_inst = dependGraph.pop(dest_reg->flatIndex()); |
MEM指令执行
mem执行有专门的exec指令,现在以load举例,initiateAcc架构相关,该函数会去计算地址,调用initiateMemRead发出请求,返回数据
1 | load_fault = inst->initiateAcc(); |
然后一步步调用,最后执行
1 | iew.ldstQueue.pushRequest |
如果不是突发传输,就会去执行,该函数就是去吧请求设置为一个SingleDataRequest,然后访问TLB进行地址转换
1 | request = new SingleDataRequest(&thread[tid], inst, isLoad, addr, |
之后如果指令完成地址转换,就会进入
1 | Fault |
下面对 LSQUnit::read(LSQRequest *request, ssize_t load_idx) 进行详细解释,该函数主要负责对 load 指令进行内存读取(或转发)操作,其总体流程如下:(GPT总结)
获取 Load 队列条目和对应指令
首先,根据给定的 load 队列索引 load_idx,在 loadQueue 中获得对应的条目(LQEntry)并获取其中绑定的动态指令(load_inst)。1
2LQEntry& load_entry = loadQueue[load_idx];
const DynInstPtr& load_inst = load_entry.instruction();绑定请求并基本检查
将传入的 request 与该 load 队列条目关联,并确保加载指令存在且还未执行(isExecuted() 为 false),防止重复读取。1
2
3load_entry.setRequest(request);
assert(load_inst);
assert(!load_inst->isExecuted());严格有序 load 检查
如果当前请求标记为严格有序(isStrictlyOrdered() 为 true),但当前 load 不是位于 loadQueue 的头部或者指令还未处于 commit 阶段,则:- 通知上游(IEW/mem dep unit)需要将该指令重新调度;
- 清除指令的“发射”标记和有效地址标志;
- 记录并统计该 reschedule 事件;
- 丢弃此 request(调用 request->discard()),并返回一个 fault(通常为 panic fault),表示此 load 还不能访问内存。
这样做确保严格有序 load 必须等到它处于队列头部且就绪时才真正执行内存操作。
打印调试信息
输出调试信息,显示 load 的索引、与 store 队列相关的位置以及请求的地址信息。1
2
3DPRINTF(LSQUnit, "Read called, load idx: %i, store idx: %i, storeHead: %i addr: %#x%s\n",
load_idx - 1, load_inst->sqIt._idx, storeQueue.head() - 1,
request->mainReq()->getPaddr(), request->isSplit() ? " split" : "");处理特殊指令:LLSC(读-链接)
如果请求属于 LLSC 类型:- 临时禁用结果记录(recordResult(false)),使得写入 misc 寄存器时不更新结果;
- 调用 ISA 的 handleLockedRead() 处理锁定读取的操作;
- 恢复结果记录设置(recordResult(true))。
处理 Local Access(本地访问)
如果请求标记为本地访问,则:- 为 load 分配存储数据的缓冲区(memData);
- 从当前线程上下文中调用 localAccessor() 直接进行读操作并计算延迟;
- 创建一个 WritebackEvent,并调度该事件在延迟后完成 writeback;
- 返回 NoFault。
Store-to-Load 转发检查
如果前面几项都不适用,则函数检查 load 指令是否可以从之前的 store 中直接转发数据,而不必去访问内存:- 从 load 指令关联的 store 队列迭代器(sqIt)处开始向“更老”(storeWBIt 之前)的 store 条目遍历;
- 对于每个候选 store,先确保 store 有数据(store_size != 0)、不严格有序且不属于 cache maintenance 操作,同时该 store 的有效地址已经设置;
- 根据 load 请求的地址范围与 store 有效数据范围计算“coverage”;
- 如果 store 包含 load 请求地址的全部数据(Full Coverage),则计算偏移后直接将 store 中的数据复制到 load 的 memData 中;
- 随后创建一个新的 Packet 并包装为 WritebackEvent,再调度该事件进行延迟 writeback,统计转发成功的次数,并返回 NoFault;
- 如果只满足“部分覆盖”(Partial Coverage):
- 说明 store 尚未完全写入 load 所需的数据,此时将 stall load(设置 stalled 标志、记录 stallingStoreIsn 和 stallingLoadIdx)并通知上游重新调度(rescheduleMemInst);
- 丢弃当前 request,返回 NoFault,等待下一个周期重新尝试。
无转发则发起内存访问
如果没有找到适合转发的 store,则证明必须访问真正的内存:- 分配 load 的 memData(如果尚未分配);
- 针对 hardware transactional memory(HTM)相关情况检查(例如设置 memData 特殊值);
- 调用 request->buildPackets() 构造 Memory Packets;
- 调用 request->sendPacketToCache() 将读取请求发送给缓存;
- 如果请求未成功发送,则调用 blockMemInst() 阻塞此 load 的发射;
- 最后返回 NoFault。
总结
LSQUnit::read() 的主要工作是判断当前 load 指令:
- 是否满足严格有序条件,否则需要 reschedule;
- 是否属于特殊访问(LLSC或本地访问);
- 是否可以通过 store-to-load forwarding 直接获得数据(完全或部分转发);
- 如果都不适用,则构造真实的内存读取请求并发送到缓存。
函数通过一系列检查和分支处理,确保 load 指令在乱序执行器中的数据依赖、顺序性和各类特殊情况(如转发、严格有序、HTM)的正确处理,并返回相应的 fault 状态(一般为 NoFault)或触发 fault 以供上层处理。
什么时候读出数据?
数据通过回调函数返回
调用什么函数执行内存操作?
一般为store_inst->initiateAcc();
其函数调用堆栈如下
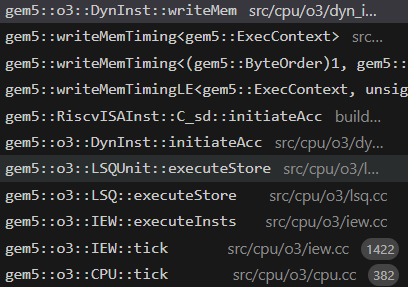
然后到最后会调用pushRequest函数,该函数层层调用会调用write函数
LSQUnit::write 函数的主要作用是将存储(store)指令的数据写入存储队列(Store Queue, SQ),并对存储请求进行必要的初始化和处理。以下是对该函数的详细解释:
1. 函数签名
1 | Fault |
request:指向当前存储请求的指针,包含存储操作的详细信息(如地址、大小、标志等)。data:指向要写入的数据的指针。store_idx:存储队列中当前存储指令的索引。
返回值是一个 Fault 对象,表示存储操作的结果。如果没有错误,返回 NoFault。
2. 确保存储队列条目有效
1 | assert(storeQueue[store_idx].valid()); |
- 确保存储队列中对应索引的条目是有效的。如果无效,则触发断言失败。
3. 打印调试信息
1 | DPRINTF(LSQUnit, "Doing write to store idx %i, addr %#x | storeHead:%i " |
- 打印当前存储操作的详细信息,包括:
- 存储队列索引(
store_idx)。 - 存储地址(
request->req()->getPaddr())。 - 存储队列头部索引(
storeQueue.head())。 - 存储指令的序列号(
seqNum)。
- 存储队列索引(
4. 设置存储请求
1 | storeQueue[store_idx].setRequest(request); |
- 将当前存储请求与存储队列中的条目关联起来。
5. 设置存储大小
1 | unsigned size = request->_size; |
- 从请求中获取存储操作的大小,并将其设置到存储队列条目中。
6. 检查是否为“无数据存储”
1 | bool store_no_data = |
- 检查存储请求是否为“无数据存储”(
STORE_NO_DATA标志)。- 如果是,则将
isAllZeros标志设置为true。 - 确保存储大小不超过存储队列条目的最大数据大小(
SQEntry::DataSize),或者存储请求是“无数据存储”。
- 如果是,则将
7. 将数据复制到存储队列
1 | if (!(request->req()->getFlags() & Request::CACHE_BLOCK_ZERO) && |
- 如果存储请求不是以下情况:
CACHE_BLOCK_ZERO:表示将整个缓存块置零。Cache Maintenance:缓存维护操作(如清除或刷新缓存)。Atomic:原子操作。
- 则将数据从
data指针复制到存储队列条目的数据缓冲区中。
8. 返回结果
1 | return NoFault; |
- 该函数只负责将数据写入存储队列,不涉及实际的内存访问,因此不会产生故障,直接返回
NoFault。
总结
LSQUnit::write 函数的主要功能是:
- 将存储请求与存储队列条目关联。
- 设置存储操作的大小和标志(如是否为“无数据存储”)。
- 将存储数据复制到存储队列(如果需要)。
- 返回存储操作的结果(通常为
NoFault)。
这是存储指令执行过程中将数据写入存储队列的关键步骤,后续的写回阶段会根据存储队列中的数据将其写入内存或缓存。
write函数将数据写入STQ,等待提交时写入Cache
问题
gem5如何取出一条指令的?
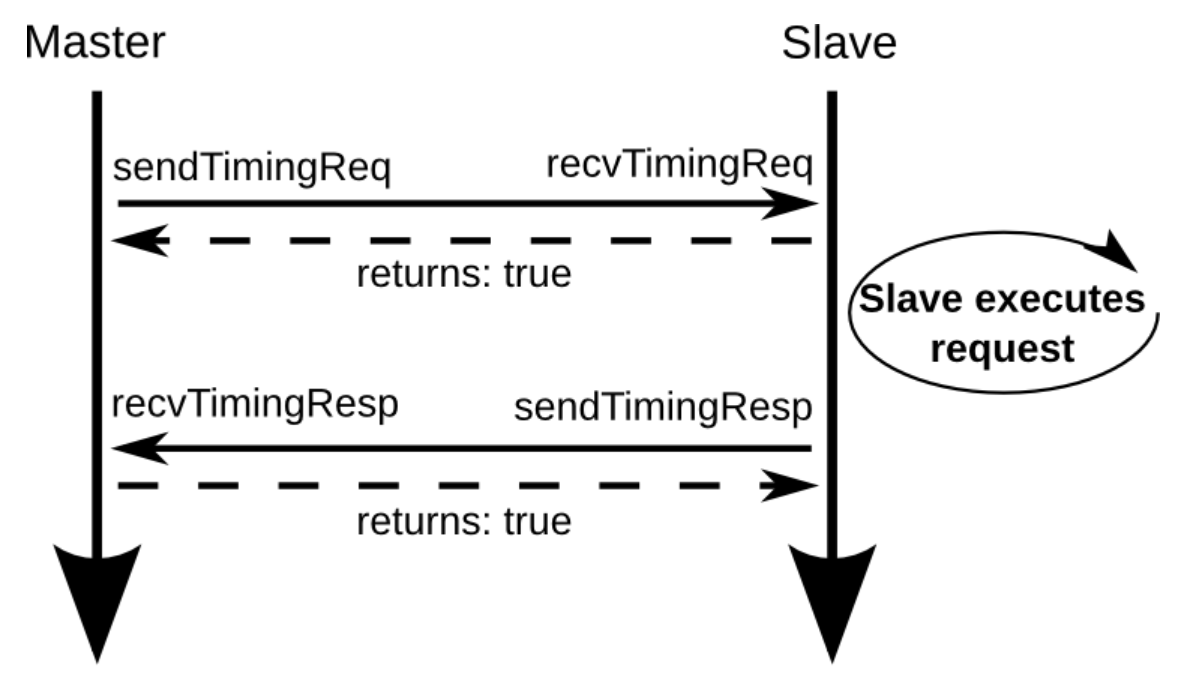
目前已知gem5是通过构建pkt来发送请求的,发送的函数为send_timing
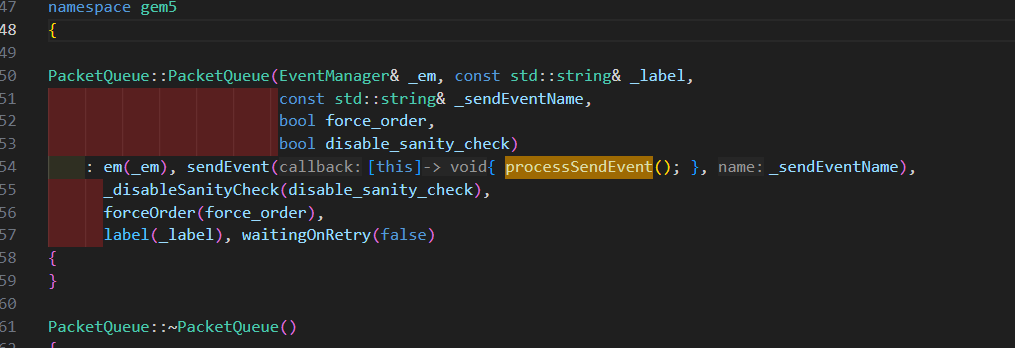
这个函数是在processSendEvent调用的,processSendEvent函数为一个回调函数,主要就是去返回发送请求得到的数据,最后会把他调度到event事件中
这些函数可能是icache端的,因为他是返回的信号
这个resp的流程:
首先cache得到recvTimingReq,该函数会访问cache
如果hit,会调用handleTimingReqHit
如果这个packet需要回复,调用cpuSidePort.schedTimingResp(pkt, request_time);,
这个函数调用respqueue,最后会调用回调函数processSendEvent,一步步到fetch的resp
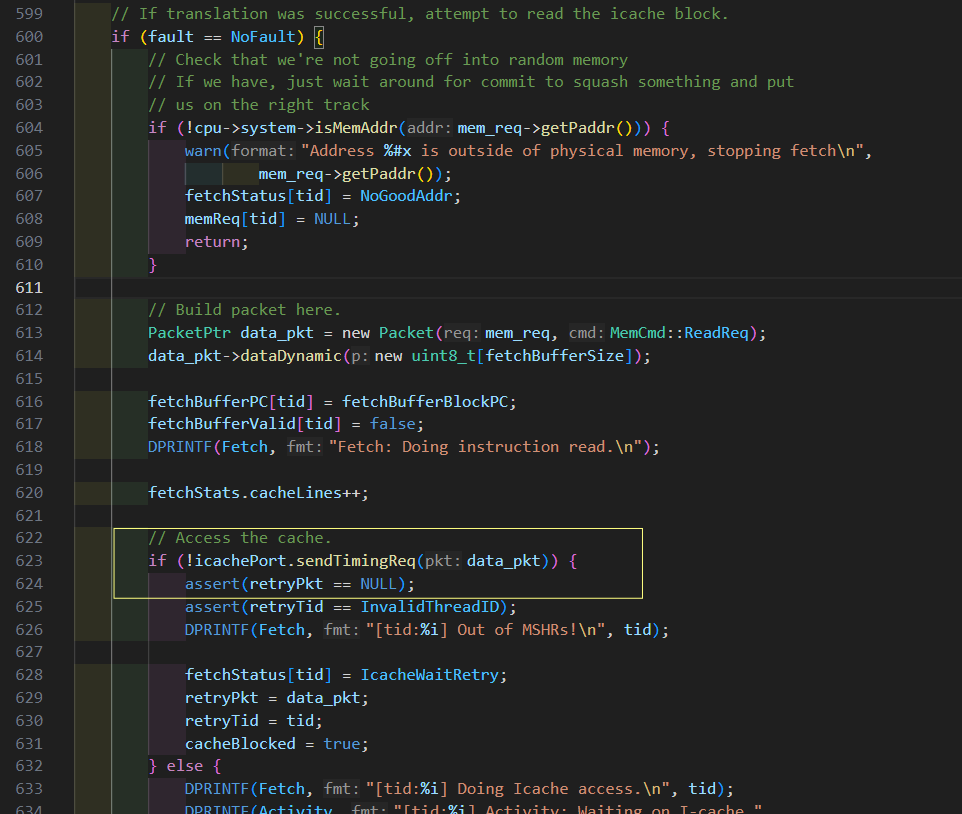
真相大白,在finishTranslation函数发出取指令
PC在哪更新?
在fetch函数,当取指令请求生成完成后,会去更新pc,
gem5实现FDIP的思路
1.单独实现FTQ
2.实现一个可以将fetch阶段和l2阶段连接的模块,或者就是预取模块,
3.实现一个分支预测管理模块,需要有预测,更新回滚结构
如何实现FTQ
FTQ需要包含的表项
gem5是以什么粒度取指令?
mininstsize,也就是指令大小长度,而不是以fetchblock为粒度,一次只取出一条