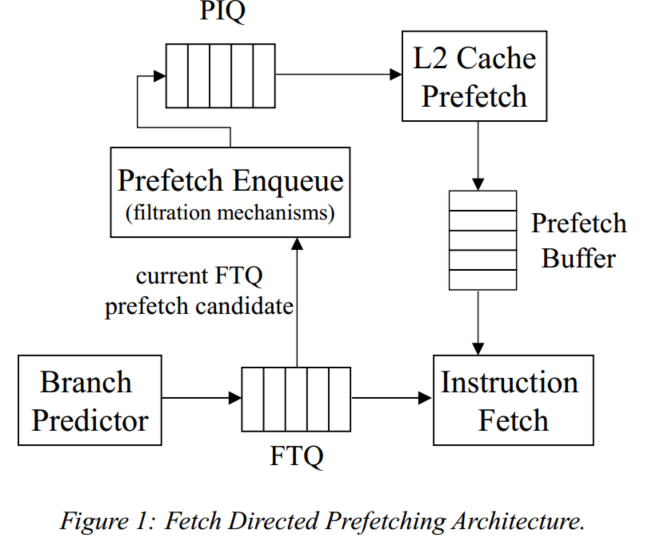
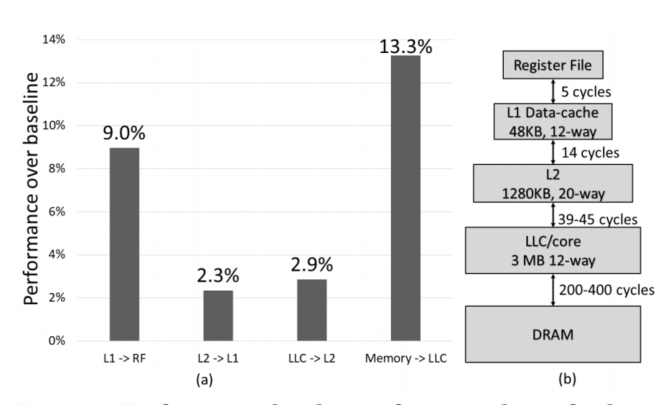
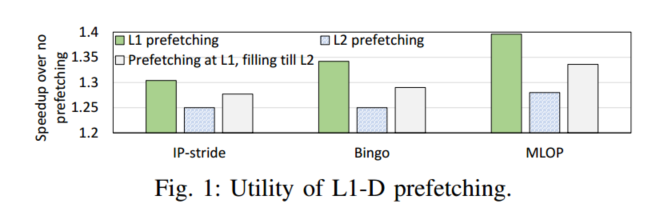
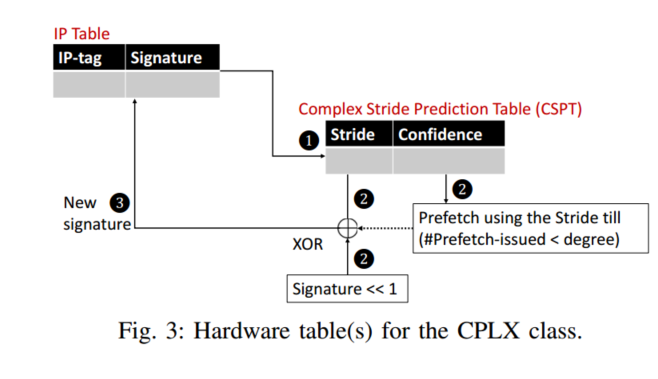
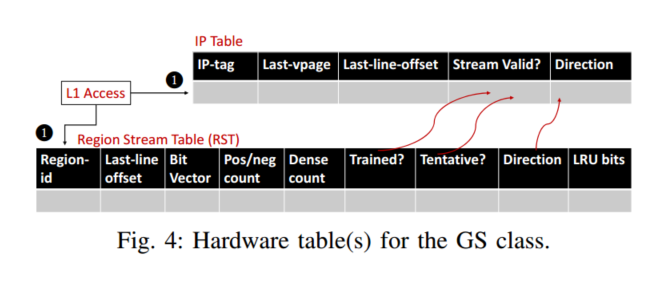
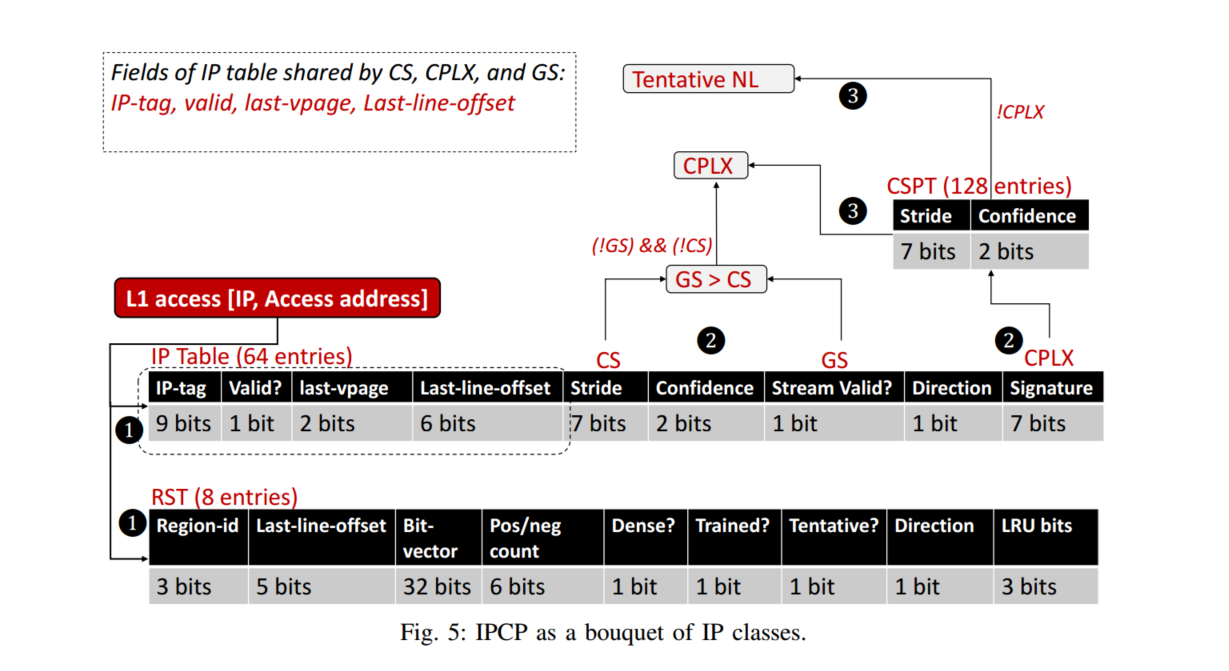
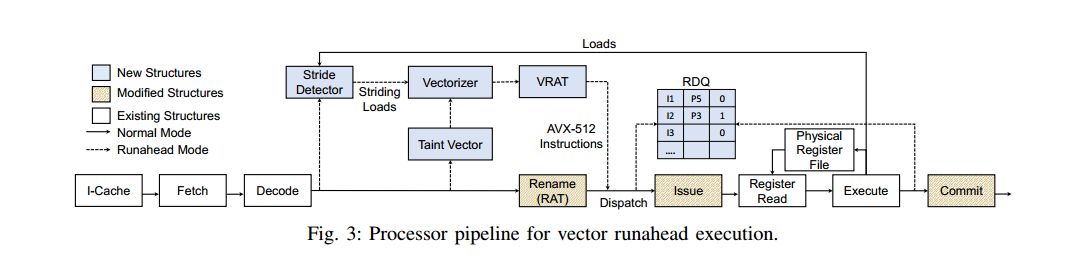
To Cross, or Not to Cross Pages for Prefetching?
这项研究的目标是L1D预取器,而不是低级高速缓存预取器,因为一级高速缓存可以直接访问虚拟内存子系统,而不是低级高速缓存。
II. MOTIVATION
1) First-Level Caches and Page-Cross Prefetching:
在虚拟地址空间中容易检测到的模式可能在物理地址空间中难以检测到,因为在虚拟地址空间中相邻的两个地址可能在物理地址空间中相隔很远[48]。一级缓存是VIPT,可以直接访问TLB,但不准确的跨页预取可能会导致5次·内存访问,((最多4次内存访问用于推测性页遍历[12],1次内存访问用于高速缓存预取请求))
2) Lower-Level Caches and Page-Cross Prefetching:
放置在低级高速缓存旁边的预取器(L2C有限责任公司)[18],[20],[42],[48],[49],[71],[77],[92],[93]使用物理地址驱动预取决策,因为这些高速缓存被实现为物理索引的物理标记(PIPT)结构[15]。出于安全原因,这些预取器通常只允许在物理页面边界内预取,因为不能保证物理地址的连续性[89]
Trends on Page-Cross Prefetching
学术观点:
这些作品通常设计新的预取器,其将高速缓存访问与比先前设计更多的特征相关联,以捕获更独特的模式。学术L1D预取器主要限于页面边界内的预取,并且它们没有针对跨页面边界进行优化,尽管它们可以直接访问虚拟内存子系统(第II-A节)。
工业界:
当预取器能够准确地执行跨页预取时,将L1D预取器限制为在页边界内预取提供了次优的收益。虽然学术著作仍然限制L1D预取器在页边界内预取,但供应商允许L1D预取器跨页边界预取[3]、[8]、[29]、[35]。跨页预取需要通过TLB层次结构,并可能启动页遍历,该页遍历在TLB中获取预取块所在页的翻译;第II-A节介绍了跨页预取的优点和缺点。但是,供应商没有提供额外的信息。目前还不清楚供应商是遵循始终允许跨页面预取的静态策略,还是使用跨页面边界协调预取的技术。
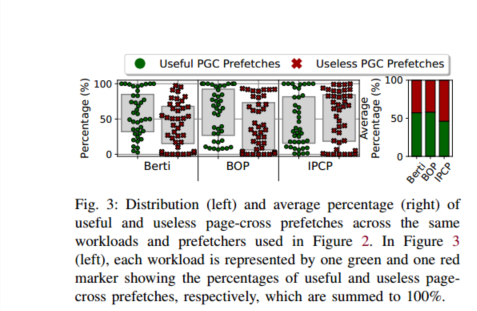
图3表示了(I)有用的跨页预取,即在其在高速缓存中的生命周期内提供至少一次命中的预取,以及(ii)无用的跨页预取,I
然后引出图4
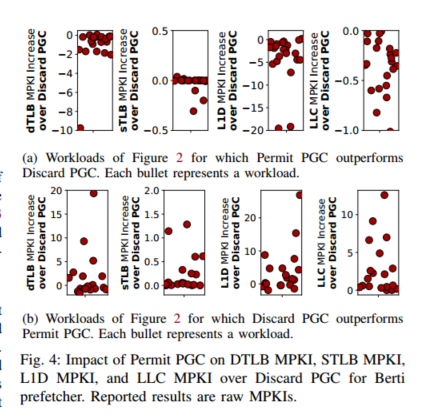
有用的预取一般会降低TLB KPKI,无用的预取大幅增加MPKI而导致不必要的内存访问(页表遍历)
A scheme able to accurately enable page-cross prefetching only when is beneficial has the potential to deliver
significant performance enhancements.
PAGE-CROSS PREFETCH FILTERING
提出了新的跨页预取算法:MOKA
(1)预测跨页边界预取的有用性的各种程序特征(例如,PC),(2)在决定是否发布跨页预取时考虑系统状态的各种系统特征(例如,sTLB MPKI),以及(3)在运行时调整决策阈值以确保跨不同执行阶段和工作负荷的准确预测的自适应方案。
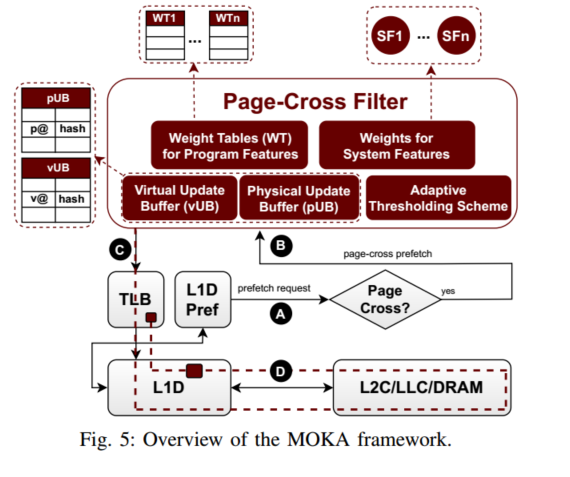
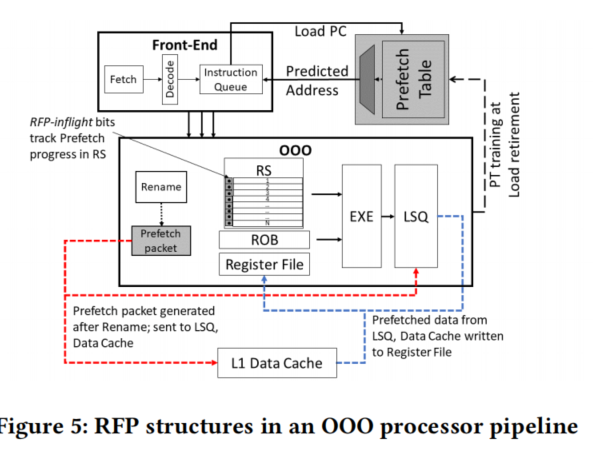
图5展示了假设VIPT L1D [12],[15]的MOKA框架的设计和高级操作。
在L1D访问时,L1D预取器产生预取请求。对于每个预取请求,MOKA检查它是否是跨页预取A。跨页过滤器仅在跨页边界B的预取中激活,并决定是否发出相应的请求。
通过跨页过滤器的预取需要通过TLB层次结构,以找到预取块所在的页的转换C。如果所请求的转换不是TLB驻留的,则触发推测性页遍历,以将相应的转换带入TLB层次结构D。
最后,发出跨页预取,最终将相应的预取块存储在L1D中。
Hardware Components of the Page-Cross Filter
Perceptron Predictors
MOKA框架提供散列感知器预测器[17],[85],用存储与选定程序特征相关的感知器权重的权重表(wt)实现;感知器权重由饱和计数器[32]、[35]、[44]-[47]、[58]、[59]、[72]、[85]、[86]实现。页面交叉过滤器为每个选定的节目特征使用一个散列感知器预测器。
Saturating Counters for System Features.
MOKA框架还提供系统特征,即,将跨页预取的有用性与系统状态(例如,TLB压力)相关联的特征。通过在跨页过滤器的决策中考虑系统状态,系统特征有助于预测跨页预取是否有用。系统特征是用饱和计数器实现的;我们称之为系统特征权重。
Virtual Update Buffer (vUB)
MOKA uses vUB for training purposes. vUB is responsible for capturing false negatives,i.e., cases where the Page-Cross Filter erroneously discarded a page-cross prefetch that would have saved a demand L1D miss if it was issued.,
Physical Update Buffer (pUB).
跨页过滤器使用pUB来确保根据所发布的跨页预取的有用性来正确更新权重(对于程序和系统功能)。当跨页预取在驱逐之前服务于至少一个L1D需求访问时,它被认为是有用的;否则被认为没用。为此,pUB条目存储跨页过滤器决定发出的跨页预取的物理地址以及相应的散列索引。请注意,pUB出于训练目的存储物理地址(而不是虚拟地址vUB ),因为它在L1D驱逐时更新权重,并且L1D被物理标记
Adaptive Thresholding Scheme.
为了确定跨页预取的有用性,跨页过滤器将累积权重(程序特征权重和系统特征权重的总和)与阈值进行比较;发出累积权重高于阈值的预取,而丢弃其他预取(第三部分-C1)。由于工作负载的异构性和阶段变化行为,使用静态阈值提供了次优的增益。MOKA框架采用了基于时期的机制(第三节-C3 ),该机制利用各种运行时信息(例如,LLC压力)来调整决策中使用的阈值。
Prediction
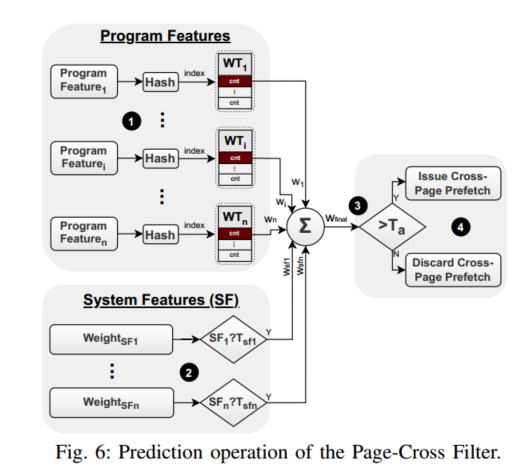
预测分为四个阶段:
第一阶段1包括三个步骤。首先,跨页过滤器从当前加载请求中提取一组选定的程序特征(第三部分-D1)。然后,每个特征被散列并用于索引相应的WT。在索引之后,从每个WT中检索权重(wi)。所有程序功能都采用相同的程序。第二阶段2检查在决策中是否需要考虑任何系统特征(第三章-D2)。为此,它计算每个系统特征(例如,sTLB MPKI)的值,并将其与阈值(SFn?图6中的Tsfn如果系统特征值(SFn)超过(或子种子,取决于特征)相关阈值(Tsfn),则在决策中考虑相应的权重(weightSFn)。
第三阶段3将所有考虑的程序和系统特征的权重相加,并生成最终权重(wfinal)。然后,将wfinal与激活阈值Ta 4进行比较。如果wfinal大于Ta,则发出跨页预取;否则它将被丢弃
training
MOKA为每个L1D块增加了一个额外的位,称为跨页位(PCB ),指示该块是否已通过跨页预取在L1D中获取。
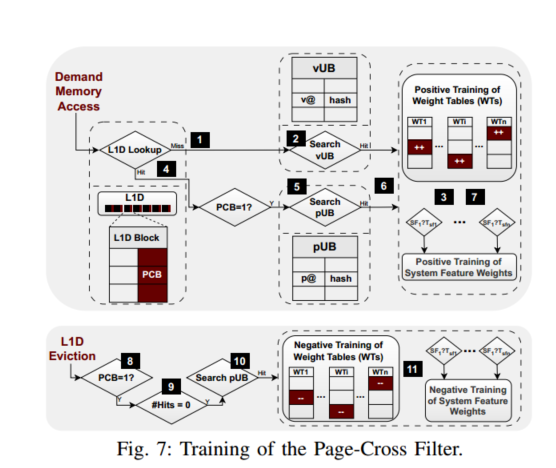
在L1D需求未命中1时,在vUB中搜索可能的命中2。vUB命中3表示相应的跨页预取被跨页过滤器错误地丢弃,于是程序和系统权重(正训练),增加了将来发布(允许)相应的跨页预取的概率。
类似地,当需求请求在L1D 4中命中并且命中的块具有其PCB设置时,即,该块由有用的跨页预取获取,则查询pUB 5。在pUB命中6时,命中pUB条目的散列索引被用于增加相应程序和系统特征7的权重
在具有PCB的块的L1D驱逐时,PageCross过滤器检查被驱逐的块在其生命期内是否在高速缓存9中提供了至少一次命中。如果没有,搜索pUB以找到匹配的条目10,因为pUB存储所发布的跨页预取的物理地址和散列索引;这就是为什么pUB将物理地址而不是虚拟地址存储为vUB(第III-B节)的原因。
匹配的pUB条目的散列索引用于减少相应的程序和系统权重(负训练)11,因为没有提供任何命中的被驱逐的L1D块指示跨页过滤器未能将相应的跨页预取分类为无用的。
Adaptive Thresholding Scheme:
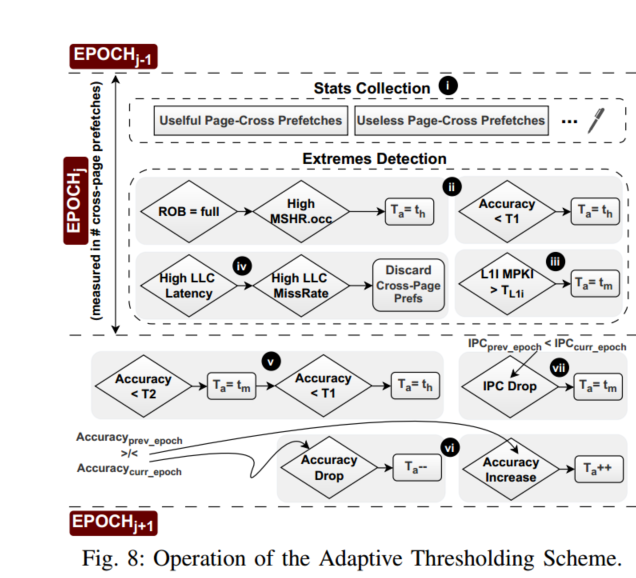
图8显示了自适应阈值方案的操作。在一个时期内,收集以下运行时统计数据(图8中的步骤I)并用于调整Ta:有用和无用的跨页预取的数量、IPC、LLC未命中率、ROB压力和L1I MPKI。
即具有非常高的缓存和ROB压力的阶段,并当场调整Ta的值。具体来说,它将Ta设置为高阈值(th ),以仅在以下情况下允许具有非常高置信度ii的跨页预取:(1)存在高ROB压力和许多进行中的L1D未命中,以及(2)跨页预取的准确性已经达到低值(T1)。此外,当存在高L1I压力(L1i MPKI>TL1i) iii时,阈值方案将Ta设置为中间值(tm ),以避免加剧L2C中跨页预取和需求指令访问之间的竞争。最后,在LLC压力非常高的阶段期间,阈值方案禁用跨页预取iv;如果LLC压力下降,则由于vUB的操作,页面交叉预取可能再次被激活(第三节-C2)。
在一个时期结束时,阈值方案潜在地使用在先前时期期间收集的运行时间信息来更新Ta。具体而言,它考虑了跨页预取的准确度v,并且当准确度分别低于阈值T2和T1时,它强制中或高阈值。此外,如果在两个连续时期vi之间跨页预取精度增加(减少),则阈值方案将Ta值增加(减少)1。最后,如果在两个连续时期vii之间存在IPC下降,则阈值方案将Ta设置为tm(如果Ta低于tm)
Bouquet of Features
Program Features:

表1显示,大多数程序特性使用虚拟地址的不同位,PC,以及发出跨页预取时预取器使用的增量。请注意,MOKA框架包含的程序特性不是专用于特定预取器的,而是对使用哪个预取器是透明的。制作利用特定预取器的元数据的专用特征(例如,前瞻)有可能进一步提高跨页过滤器的效率。我们的工作并不关注特定的预取器,而是提供了一个有效的跨页预取的整体方案。
System Features:
程序特性(第三节-D1)对于跨页过滤器的准确性和性能至关重要。但是,他们在做出决策时没有考虑系统状态(例如,TLB/缓存压力)。换句话说,过去被证明有用(无用)的跨页预取在具有不同属性的不同执行阶段可能是无用的(有用的)。MOKA框架考虑了表1中列出的6个系统特性来捕捉这些场景。每个系统功能都是用一个饱和计数器实现的,并在不同阶段监控跨页预取的有效性。例如,在sTLB未命中率高于预定义阈值(SFsTLB_missrate>TsTLB_missrate)的阶段,sTLB未命中率系统功能会监控跨页预取的有效性。
Combining Features:
The feature selection process takes place offline and uses IPC speedup as optimization metric.2
DRIPPER: A Page-Cross Filter Prototype

我们观察到所有滴头配置(表II)都使用一个程序特征和两个系统特征。为所有考虑的预取器选择相同的系统特征(sTLB MPKI,sTLB未命中率),而两个预取器(BOP,IPCP)还共同具有所使用的程序特征(PC⊕Delta).
所选功能背后的基本原理如下:此程序功能使用L1D预取器使用的增量来发布跨页预取,并了解特定增量在用于生成跨页预取请求时是否有益。
PC⊕Delta.该程序特征是通过将PC与预取器用来发出跨页预取的增量进行异或运算来计算的,并提供某个PC是否偏好用于跨页预取的特定增量的信息。
sTLB MPKI。这个系统特性将具有低sTLB MPKI速率(SFsTLB_mpki<TsTLB_mpki)的阶段与跨页预取的有用性相关联。该特性背后的核心思想是,当sTLB MPKI较低时,跨页预取请求在TLB层次结构中命中的概率较高(触发页遍历的概率较低)。因此,如果跨页预取在这些阶段有用/无用,这个特性通过增加最终的累积权重(第3步,图6)使DRIPPER对跨页预取更积极/更不积极。只有当SFsTLB_mpki<TsTLB_mpki时,该系统功能才有助于决策。
sTLB未命中率。该系统特征是对sTLB MPKI系统特征的补充,因为它以sTLB压力高的阶段为目标,而sTLB MPKI系统特征以sTLB压力低的阶段为目标。我们使用sTLB失效率度量而不是sTLB MPKI度量来捕获具有高sTLB压力的相位,因为前者比后者对变化更敏感。此系统功能在sTLB未命中率较高的阶段(SFsTLB_missrate>TsTLB_missrate)测量跨页预取的有用性,以识别其他功能无法捕捉的错过的机会。核心思想是,当sTLB中大多数请求内存访问未命中时,允许L1D预取器触发跨页预取可能会提高sTLB命中率,因为跨页预取会引入页遍历。因此,如果跨页预取在高sTLB未命中率的阶段被证明是有用的,这个特性增加了DRIPPER允许跨页预取的可能性。仅当SFsTLB_missrate>TsTLB_missrate时,才使用此功能。